 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Review of Hybrid and Ensemble in Deep Learning for Natural Language Processing
Dec 09, 2023This review presents a comprehensive exploration of hybrid and ensemble deep learning models within Natural Language Processing (NLP), shedding light on their transformative potential across diverse tasks such as Sentiment Analysis, Named Entity Recognition, Machine Translation, Question Answering, Text Classification, Generation, Speech Recognition, Summarization, and Language Modeling. The paper systematically introduces each task, delineates key architectures from Recurrent Neural Networks (RNNs) to Transformer-based models like BERT, and evaluates their performance, challenges, and computational demands. The adaptability of ensemble techniques is emphasized, highlighting their capacity to enhance various NLP applications. Challenges in implementation, including computational overhead, overfitting, and model interpretation complexities, are addressed alongside the trade-off between interpretability and performance. Serving as a concise yet invaluable guide, this review synthesizes insights into tasks, architectures, and challenges, offering a holistic perspective for researchers and practitioners aiming to advance language-driven applications through ensemble deep learning in NLP.
MiAMix: Enhancing Image Classification through a Multi-stage Augmented Mixed Sample Data Augmentation Method
Aug 15, 2023
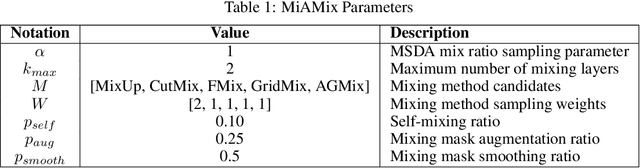
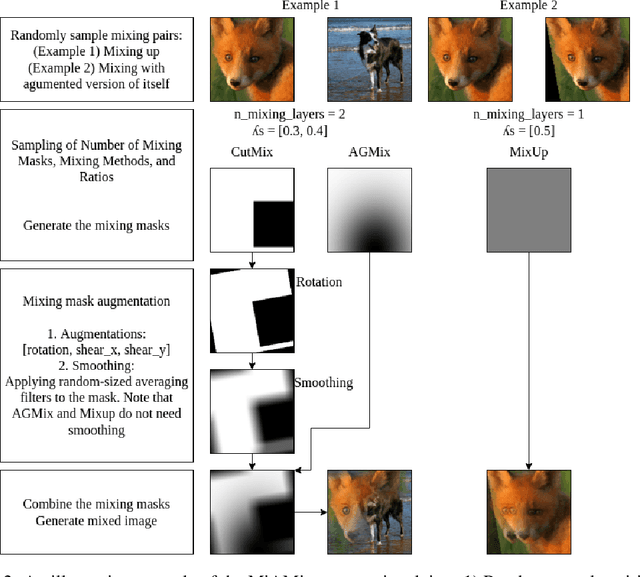
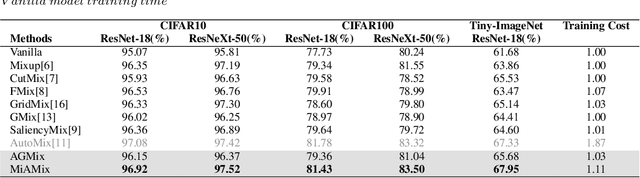
Despite substantial progress in the field of deep learning, overfitting persists as a critical challenge, and data augmentation has emerged as a particularly promising approach due to its capacity to enhance model generalization in various computer vision tasks. While various strategies have been proposed, Mixed Sample Data Augmentation (MSDA) has shown great potential for enhancing model performance and generalization. We introduce a novel mixup method called MiAMix, which stands for Multi-stage Augmented Mixup. MiAMix integrates image augmentation into the mixup framework, utilizes multiple diversified mixing methods concurrently, and improves the mixing method by randomly selecting mixing mask augmentation methods. Recent methods utilize saliency information and the MiAMix is designed for computational efficiency as well, reducing additional overhead and offering easy integration into existing training pipelines. We comprehensively evaluate MiaMix using four image benchmarks and pitting it against current state-of-the-art mixed sample data augmentation techniques to demonstrate that MIAMix improves performance without heavy computational overhead.
Cross-Attribute Matrix Factorization Model with Shared User Embedding
Aug 14, 2023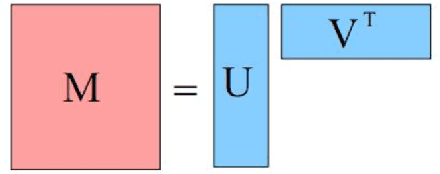
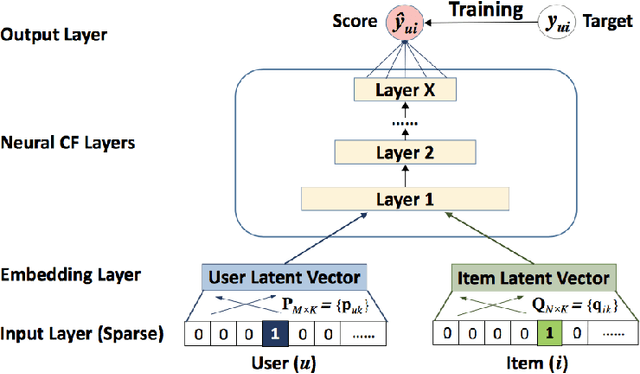
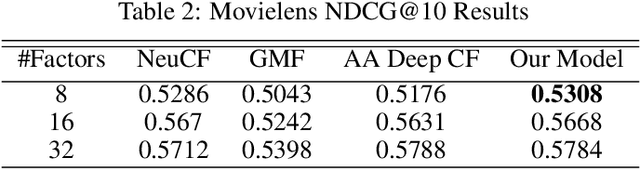
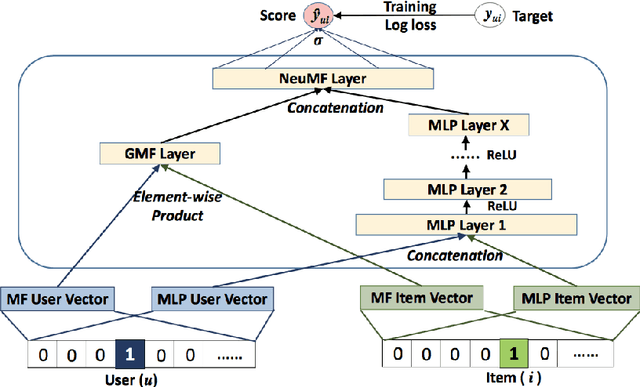
Over the past few years, deep learning has firmly established its prowess across various domains, including computer vision, speech recognition, and natural language processing. Motivated by its outstanding success, researchers have been directing their efforts towards applying deep learning techniques to recommender systems. Neural collaborative filtering (NCF) and Neural Matrix Factorization (NeuMF) refreshes the traditional inner product in matrix factorization with a neural architecture capable of learning complex and data-driven functions. While these models effectively capture user-item interactions, they overlook the specific attributes of both users and items. This can lead to robustness issues, especially for items and users that belong to the "long tail". Such challenges are commonly recognized in recommender systems as a part of the cold-start problem. A direct and intuitive approach to address this issue is by leveraging the features and attributes of the items and users themselves. In this paper, we introduce a refined NeuMF model that considers not only the interaction between users and items, but also acrossing associated attributes. Moreover, our proposed architecture features a shared user embedding, seamlessly integrating with user embeddings to imporve the robustness and effectively address the cold-start problem. Rigorous experiments on both the Movielens and Pinterest datasets demonstrate the superiority of our Cross-Attribute Matrix Factorization model, particularly in scenarios characterized by higher dataset sparsity.