 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-UNet: Refined Class Activation Mapping for Weakly-Supervised Semantic Segmentation with Multi-scale Inference
May 06, 2022
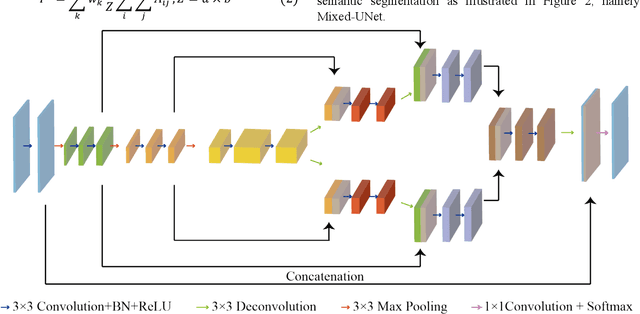
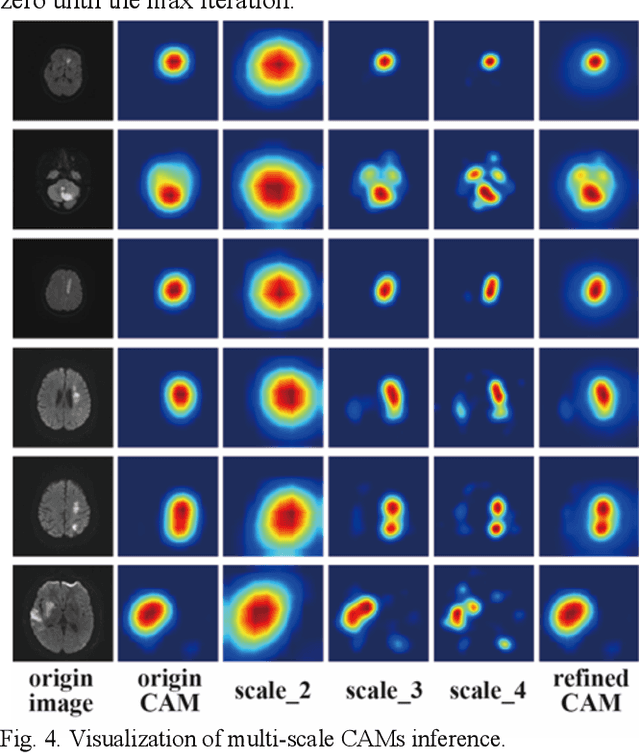
Deep learning techniques have shown great potential in medical image processing, particularly through accurate and reliable image segmentation on magnetic resonance imaging (MRI) scans or computed tomography (CT) scans, which allow the localization and diagnosis of lesions. However, training these segmentation models requires a large number of manually annotated pixel-level labels, which are time-consuming and labor-intensive, in contrast to image-level labels that are easier to obtain. It is imperative to resolve this problem through weakly-supervised semantic segmentation models using image-level labels as supervision since it can significantly reduce human annotation efforts. Most of the advanced solutions exploit class activation mapping (CAM). However, the original CAMs rarely capture the precise boundaries of lesions. In this study, we propose the strategy of multi-scale inference to refine CAMs by reducing the detail loss in single-scale reasoning. For segmentation, we develop a novel model named Mixed-UNet, which has two parallel branches in the decoding phase. The results can be obtained after fusing the extracted features from two branches. We evaluate the designed Mixed-UNet against several prevalent deep learning-based segmentation approaches on our dataset collected from the local hospital and public datasets. The validation results demonstrate that our model surpasses available methods under the same supervision level in the segmentation of various lesions from brain imaging.