 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAwesome Multi-modal Object Tracking
Paper and Code
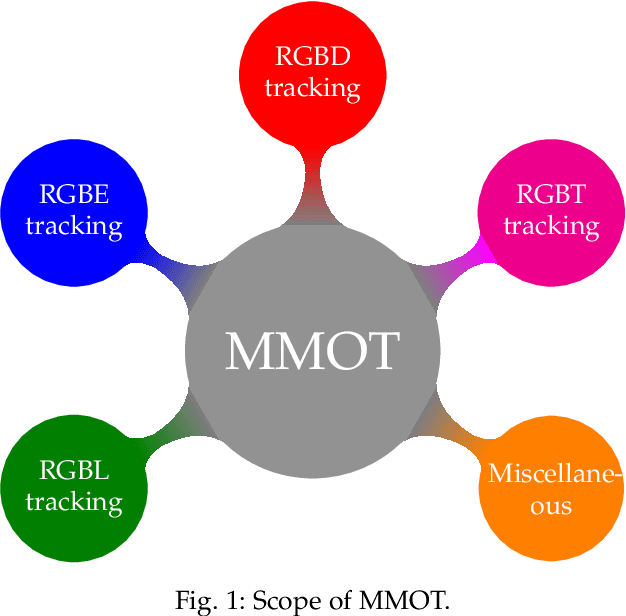
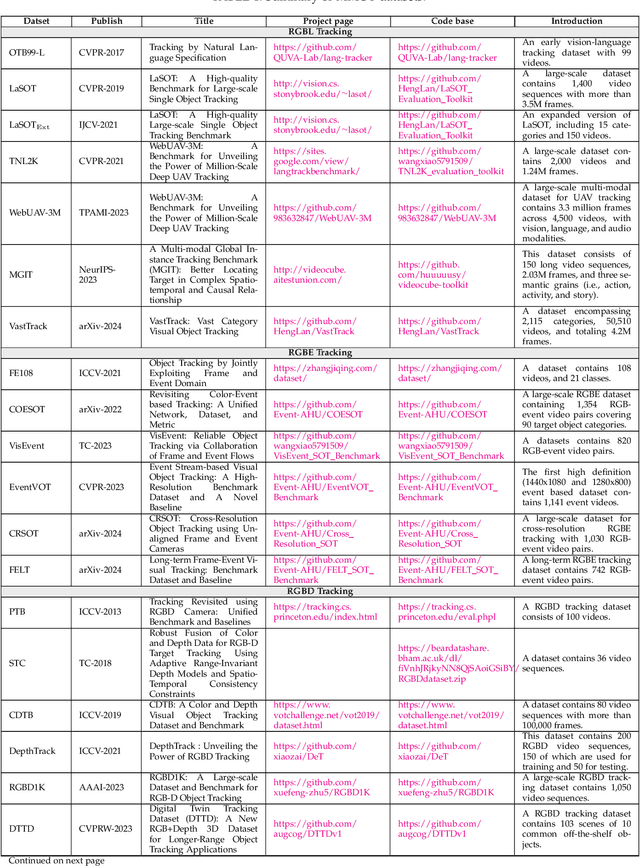

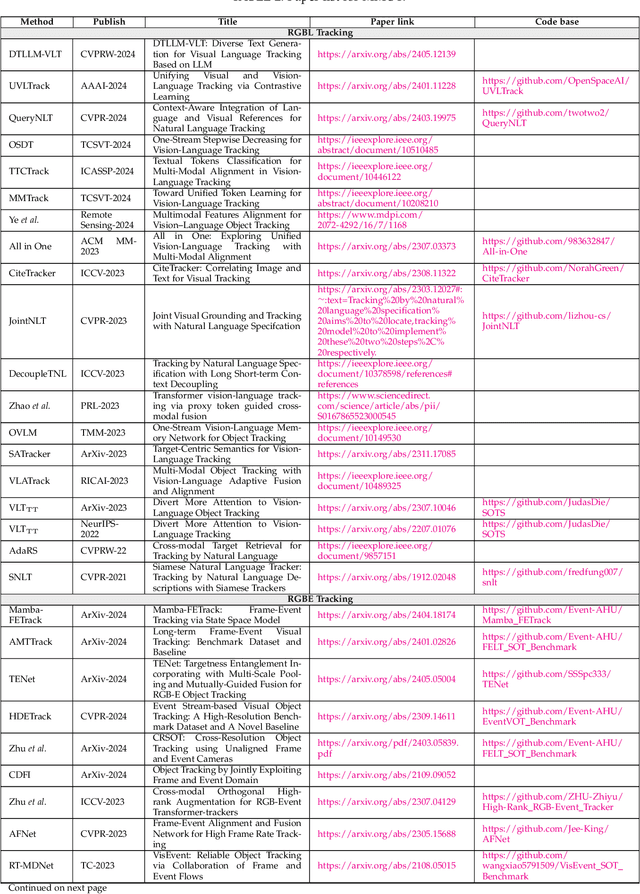
Multi-modal object tracking (MMOT) is an emerging field that combines data from various modalities, \eg vision (RGB), depth, thermal infrared, event, language and audio, to estimate the state of an arbitrary object in a video sequence. It is of great significance for many applications such as autonomous driving and intelligent surveillance. In recent years, MMOT has received more and more attention. However, existing MMOT algorithms mainly focus on two modalities (\eg RGB+depth, RGB+thermal infrared, and RGB+language). To leverage more modalities, some recent efforts have been made to learn a unified visual object tracking model for any modality. Additionally, some large-scale multi-modal tracking benchmarks have been established by simultaneously providing more than two modalities, such as vision-language-audio (\eg WebUAV-3M) and vision-depth-language (\eg UniMod1K). To track the latest progress in MMOT, we conduct a comprehensive investigation in this report. Specifically, we first divide existing MMOT tasks into five main categories, \ie RGBL tracking, RGBE tracking, RGBD tracking, RGBT tracking, and miscellaneous (RGB+X), where X can be any modality, such as language, depth, and event. Then, we analyze and summarize each MMOT task, focusing on widely used datasets and mainstream tracking algorithms based on their technical paradigms (\eg self-supervised learning, prompt learning, knowledge distillation, generative models, and state space models). Finally, we maintain a continuously updated paper list for MMOT at https://github.com/983632847/Awesome-Multimodal-Object-Tracking.