 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCD^2: Constrained Dataset Distillation for Few-Shot Class-Incremental Learning
Jan 13, 2026Few-shot class-incremental learning (FSCIL) receives significant attention from the public to perform classification continuously with a few training samples, which suffers from the key catastrophic forgetting problem. Existing methods usually employ an external memory to store previous knowledge and treat it with incremental classes equally, which cannot properly preserve previous essential knowledge. To solve this problem and inspired by recent distillation works on knowledge transfer, we propose a framework termed \textbf{C}onstrained \textbf{D}ataset \textbf{D}istillation (\textbf{CD$^2$}) to facilitate FSCIL, which includes a dataset distillation module (\textbf{DDM}) and a distillation constraint module~(\textbf{DCM}). Specifically, the DDM synthesizes highly condensed samples guided by the classifier, forcing the model to learn compacted essential class-related clues from a few incremental samples. The DCM introduces a designed loss to constrain the previously learned class distribution, which can preserve distilled knowledge more sufficiently. Extensive experiments on three public datasets show the superiority of our method against other state-of-the-art competitors.
GPTDrawer: Enhancing Visual Synthesis through ChatGPT
Dec 11, 2024
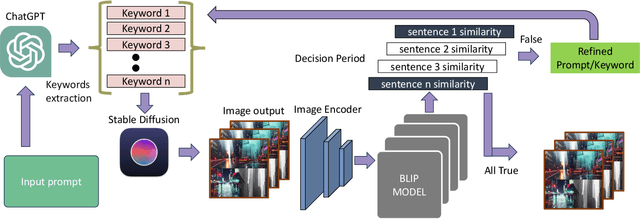

In the burgeoning field of AI-driven image generation, the quest for precision and relevance in response to textual prompts remains paramount. This paper introduces GPTDrawer, an innovative pipeline that leverages the generative prowess of GPT-based models to enhance the visual synthesis process. Our methodology employs a novel algorithm that iteratively refines input prompts using keyword extraction, semantic analysis, and image-text congruence evaluation. By integrating ChatGPT for natural language processing and Stable Diffusion for image generation, GPTDrawer produces a batch of images that undergo successive refinement cycles, guided by cosine similarity metrics until a threshold of semantic alignment is attained. The results demonstrate a marked improvement in the fidelity of images generated in accordance with user-defined prompts, showcasing the system's ability to interpret and visualize complex semantic constructs. The implications of this work extend to various applications, from creative arts to design automation, setting a new benchmark for AI-assisted creative processes.
Electronic Health Records-Based Data-Driven Diabetes Knowledge Unveiling and Risk Prognosis
Dec 05, 2024


In the healthcare sector, the application of deep learning technologies has revolutionized data analysis and disease forecasting. This is particularly evident in the field of diabetes, where the deep analysis of Electronic Health Records (EHR) has unlocked new opportunities for early detection and effective intervention strategies. Our research presents an innovative model that synergizes the capabilities of Bidirectional Long Short-Term Memory Networks-Conditional Random Field (BiLSTM-CRF) with a fusion of XGBoost and Logistic Regression. This model is designed to enhance the accuracy of diabetes risk prediction by conducting an in-depth analysis of electronic medical records data. The first phase of our approach involves employing BiLSTM-CRF to delve into the temporal characteristics and latent patterns present in EHR data. This method effectively uncovers the progression trends of diabetes, which are often hidden in the complex data structures of medical records. The second phase leverages the combined strength of XGBoost and Logistic Regression to classify these extracted features and evaluate associated risks. This dual approach facilitates a more nuanced and precise prediction of diabetes, outperforming traditional models, particularly in handling multifaceted and nonlinear medical datasets. Our research demonstrates a notable advancement in diabetes prediction over traditional methods, showcasing the effectiveness of our combined BiLSTM-CRF, XGBoost, and Logistic Regression model. This study highlights the value of data-driven strategies in clinical decision-making, equipping healthcare professionals with precise tools for early detection and intervention. By enabling personalized treatment and timely care, our approach signifies progress in incorporating advanced analytics in healthcare, potentially improving outcomes for diabetes and other chronic conditions.
Mitigating Knowledge Conflicts in Language Model-Driven Question Answering
Nov 18, 2024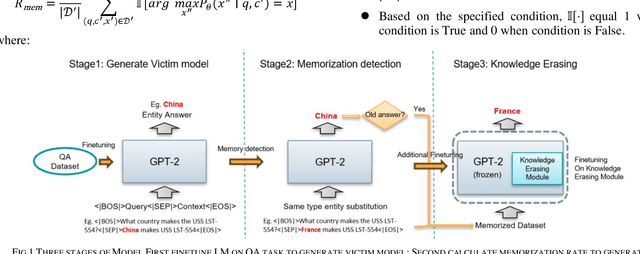


Knowledge-aware sequence to sequence generation tasks such as document question answering and abstract summarization typically requires two types of knowledge: encoded parametric knowledge and retrieved contextual information. Previous work show improper correlation between parametric knowledge and answers in the training set could cause the model ignore input information at test time, resulting in un-desirable model behaviour such as over-stability and hallucination. In this work, we argue that hallucination could be mitigated via explicit correlation between input source and generated content. We focus on a typical example of hallucination, entity-based knowledge conflicts in question answering, where correlation of entities and their description at training time hinders model behaviour during inference.
Optimization and Application of Cloud-based Deep Learning Architecture for Multi-Source Data Prediction
Oct 16, 2024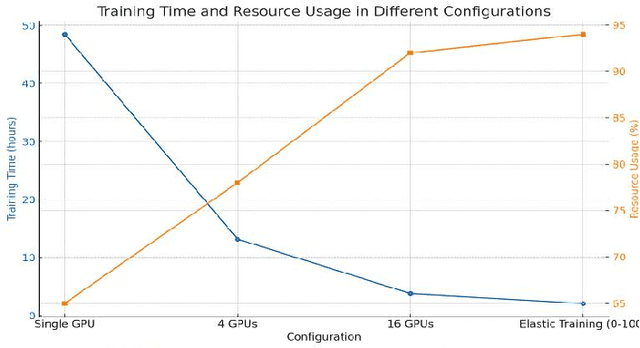
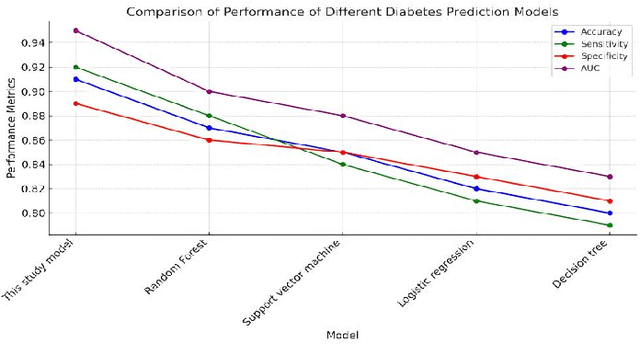
This study develops a cloud-based deep learning system for early prediction of diabetes, leveraging the distributed computing capabilities of the AWS cloud platform and deep learning technologies to achieve efficient and accurate risk assessment. The system utilizes EC2 p3.8xlarge GPU instances to accelerate model training, reducing training time by 93.2% while maintaining a prediction accuracy of 94.2%. With an automated data processing and model training pipeline built using Apache Airflow, the system can complete end-to-end updates within 18.7 hours. In clinical applications, the system demonstrates a prediction accuracy of 89.8%, sensitivity of 92.3%, and specificity of 95.1%. Early interventions based on predictions lead to a 37.5% reduction in diabetes incidence among the target population. The system's high performance and scalability provide strong support for large-scale diabetes prevention and management, showcasing significant public health value.
Offline Signature Verification Based on Feature Disentangling Aided Variational Autoencoder
Sep 29, 2024Offline handwritten signature verification systems are used to verify the identity of individuals, through recognizing their handwritten signature image as genuine signatures or forgeries. The main tasks of signature verification systems include extracting features from signature images and training a classifier for classification. The challenges of these tasks are twofold. First, genuine signatures and skilled forgeries are highly similar in their appearances, resulting in a small inter-class distance. Second, the instances of skilled forgeries are often unavailable, when signature verification models are being trained. To tackle these problems, this paper proposes a new signature verification method. It is the first model that employs a variational autoencoder (VAE) to extract features directly from signature images. To make the features more discriminative, it improves the traditional VAEs by introducing a new loss function for feature disentangling. In addition, it relies on SVM (Support Vector Machine) for classification according to the extracted features. Extensive experiments are conducted on two public datasets: MCYT-75 and GPDS-synthetic where the proposed method significantly outperformed $13$ representative offline signature verification methods. The achieved improvement in distinctive datasets indicates the robustness and great potential of the developed system in real application.
DANCE: Dual-View Distribution Alignment for Dataset Condensation
Jun 03, 2024



Dataset condensation addresses the problem of data burden by learning a small synthetic training set that preserves essential knowledge from the larger real training set. To date, the state-of-the-art (SOTA) results are often yielded by optimization-oriented methods, but their inefficiency hinders their application to realistic datasets. On the other hand, the Distribution-Matching (DM) methods show remarkable efficiency but sub-optimal results compared to optimization-oriented methods. In this paper, we reveal the limitations of current DM-based methods from the inner-class and inter-class views, i.e., Persistent Training and Distribution Shift. To address these problems, we propose a new DM-based method named Dual-view distribution AligNment for dataset CondEnsation (DANCE), which exploits a few pre-trained models to improve DM from both inner-class and inter-class views. Specifically, from the inner-class view, we construct multiple "middle encoders" to perform pseudo long-term distribution alignment, making the condensed set a good proxy of the real one during the whole training process; while from the inter-class view, we use the expert models to perform distribution calibration, ensuring the synthetic data remains in the real class region during condensing. Experiments demonstrate the proposed method achieves a SOTA performance while maintaining comparable efficiency with the original DM across various scenarios. Source codes are available at https://github.com/Hansong-Zhang/DANCE.
M3D: Dataset Condensation by Minimizing Maximum Mean Discrepancy
Jan 03, 2024Training state-of-the-art (SOTA) deep models often requires extensive data, resulting in substantial training and storage costs. To address these challenges, dataset condensation has been developed to learn a small synthetic set that preserves essential information from the original large-scale dataset. Nowadays, optimization-oriented methods have been the primary method in the field of dataset condensation for achieving SOTA results. However, the bi-level optimization process hinders the practical application of such methods to realistic and larger datasets. To enhance condensation efficiency, previous works proposed Distribution-Matching (DM) as an alternative, which significantly reduces the condensation cost. Nonetheless, current DM-based methods have yielded less comparable results to optimization-oriented methods due to their focus on aligning only the first moment of the distributions. In this paper, we present a novel DM-based method named M3D for dataset condensation by Minimizing the Maximum Mean Discrepancy between feature representations of the synthetic and real images. By embedding their distributions in a reproducing kernel Hilbert space, we align all orders of moments of the distributions of real and synthetic images, resulting in a more generalized condensed set. Notably, our method even surpasses the SOTA optimization-oriented method IDC on the high-resolution ImageNet dataset. Extensive analysis is conducted to verify the effectiveness of the proposed method.
Coupled Confusion Correction: Learning from Crowds with Sparse Annotations
Dec 26, 2023



As the size of the datasets getting larger, accurately annotating such datasets is becoming more impractical due to the expensiveness on both time and economy. Therefore, crowd-sourcing has been widely adopted to alleviate the cost of collecting labels, which also inevitably introduces label noise and eventually degrades the performance of the model. To learn from crowd-sourcing annotations, modeling the expertise of each annotator is a common but challenging paradigm, because the annotations collected by crowd-sourcing are usually highly-sparse. To alleviate this problem, we propose Coupled Confusion Correction (CCC), where two models are simultaneously trained to correct the confusion matrices learned by each other. Via bi-level optimization, the confusion matrices learned by one model can be corrected by the distilled data from the other. Moreover, we cluster the ``annotator groups'' who share similar expertise so that their confusion matrices could be corrected together. In this way, the expertise of the annotators, especially of those who provide seldom labels, could be better captured. Remarkably, we point out that the annotation sparsity not only means the average number of labels is low, but also there are always some annotators who provide very few labels, which is neglected by previous works when constructing synthetic crowd-sourcing annotations. Based on that, we propose to use Beta distribution to control the generation of the crowd-sourcing labels so that the synthetic annotations could be more consistent with the real-world ones. Extensive experiments are conducted on two types of synthetic datasets and three real-world datasets, the results of which demonstrate that CCC significantly outperforms state-of-the-art approaches.
Multi-Label Noise Transition Matrix Estimation with Label Correlations: Theory and Algorithm
Sep 22, 2023



Noisy multi-label learning has garnered increasing attention due to the challenges posed by collecting large-scale accurate labels, making noisy labels a more practical alternative. Motivated by noisy multi-class learning, the introduction of transition matrices can help model multi-label noise and enable the development of statistically consistent algorithms for noisy multi-label learning. However, estimating multi-label noise transition matrices remains a challenging task, as most existing estimators in noisy multi-class learning rely on anchor points and accurate fitting of noisy class posteriors, which is hard to satisfy in noisy multi-label learning. In this paper, we address this problem by first investigating the identifiability of class-dependent transition matrices in noisy multi-label learning. Building upon the identifiability results, we propose a novel estimator that leverages label correlations without the need for anchor points or precise fitting of noisy class posteriors. Specifically, we first estimate the occurrence probability of two noisy labels to capture noisy label correlations. Subsequently, we employ sample selection techniques to extract information implying clean label correlations, which are then used to estimate the occurrence probability of one noisy label when a certain clean label appears. By exploiting the mismatches in label correlations implied by these occurrence probabilities, we demonstrate that the transition matrix becomes identifiable and can be acquired by solving a bilinear decomposition problem. Theoretically, we establish an estimation error bound for our multi-label transition matrix estimator and derive a generalization error bound for our statistically consistent algorithm. Empirically, we validate the effectiveness of our estimator in estimating multi-label noise transition matrices, leading to excellent classification performance.