 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeachAnything: A Multimodal Crowdsourcing Platform for Training Embodied AI Agents in Symmetrical Reality
May 14, 2026Symmetrical Reality (SR) is emerging as a future trend for human-agent coexistence, placing higher demands on agents to acquire human-like intelligence. It calls for richer and more diverse human guidance. We introduce a three-stage demonstration paradigm integrating multimodal demonstration signals. Building on this paradigm, we developed TeachAnything, a cloud-based, crowdsourcing-oriented demonstration platform with physics simulation capable of collecting diverse demonstration data across varied scenes, tasks, and embodiments. By unifying virtual and physical interactions through both methodological design and physics simulation, the system serves as a practical foundation for developing embodied agents aligned with Symmetrical Reality.
Learning Dynamics of Zeroth-Order Optimization: A Kernel Perspective
May 05, 2026Classical optimization theory establishes that zeroth-order (ZO) algorithms suffer from a dimension-dependent slowdown, with convergence rates typically scaling with the model dimension compared to first-order methods. However, in contrast to these theoretical expectations, a growing body of recent work demonstrates the successful application of ZO methods to fine-tuning Large Language Models (LLMs) with billions of parameters. To explain this paradox, we derive the one-step learning dynamics of ZO SGD, where the empirical Neural Tangent Kernel (eNTK) naturally emerges as the key term governing the learning behavior. Inspection of the eNTK produced by ZO SGD reveals that each element corresponds to the inner product of neural tangent vectors projected onto a random low-dimensional subspace. Thus, by invoking the Johnson-Lindenstrauss Lemma, our analysis shows that the fidelity of the ZO eNTK is governed primarily by the number of perturbations. Crucially, the approximation error depends on the model output size rather than the massive parameter dimension. This dimension-free property provides a theoretical justification for the scalability of ZO methods to LLMs finetuning tasks. We believe that this kernel-based framework offers a novel perspective for understanding ZO methods within the context of learning dynamics.
Can Language Models Compose Skills In-Context?
Oct 27, 2025Composing basic skills from simple tasks to accomplish composite tasks is crucial for modern intelligent systems. We investigate the in-context composition ability of language models to perform composite tasks that combine basic skills demonstrated in in-context examples. This is more challenging than the standard setting, where skills and their composition can be learned in training. We conduct systematic experiments on various representative open-source language models, utilizing linguistic and logical tasks designed to probe composition abilities. The results reveal that simple task examples can have a surprising negative impact on the performance, because the models generally struggle to recognize and assemble the skills correctly, even with Chain-of-Thought examples. Theoretical analysis further shows that it is crucial to align examples with the corresponding steps in the composition. This inspires a method for the probing tasks, whose improved performance provides positive support for our insights.
Achieving Dimension-Free Communication in Federated Learning via Zeroth-Order Optimization
May 24, 2024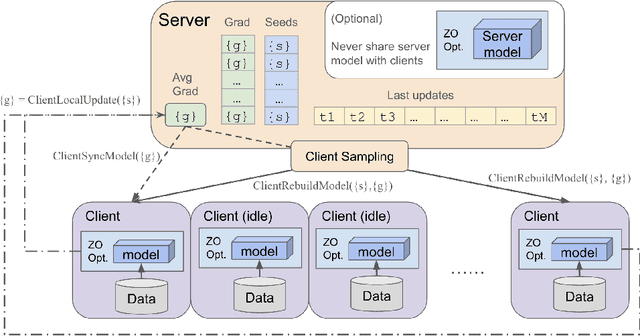



Federated Learning (FL) offers a promising framework for collaborative and privacy-preserving machine learning across distributed data sources. However, the substantial communication costs associated with FL pose a significant challenge to its efficiency. Specifically, in each communication round, the communication costs scale linearly with the model's dimension, which presents a formidable obstacle, especially in large model scenarios. Despite various communication efficient strategies, the intrinsic dimension-dependent communication cost remains a major bottleneck for current FL implementations. In this paper, we introduce a novel dimension-free communication strategy for FL, leveraging zero-order optimization techniques. We propose a new algorithm, FedDisco, which facilitates the transmission of only a constant number of scalar values between clients and the server in each communication round, thereby reducing the communication cost from $\mathscr{O}(d)$ to $\mathscr{O}(1)$, where $d$ is the dimension of the model parameters. Theoretically, in non-convex functions, we prove that our algorithm achieves state-of-the-art rates, which show a linear speedup of the number of clients and local steps under standard assumptions and dimension-free rate for low effective rank scenarios. Empirical evaluations through classic deep learning training and large language model fine-tuning substantiate significant reductions in communication overhead compared to traditional FL approaches.
VeCAF: VLM-empowered Collaborative Active Finetuning with Training Objective Awareness
Jan 15, 2024
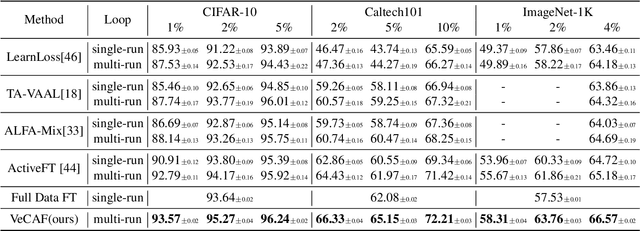


Finetuning a pretrained vision model (PVM) is a common technique for learning downstream vision tasks. The conventional finetuning process with the randomly sampled data points results in diminished training efficiency. To address this drawback, we propose a novel approach, VLM-empowered Collaborative Active Finetuning (VeCAF). VeCAF optimizes a parametric data selection model by incorporating the training objective of the model being tuned. Effectively, this guides the PVM towards the performance goal with improved data and computational efficiency. As vision-language models (VLMs) have achieved significant advancements by establishing a robust connection between image and language domains, we exploit the inherent semantic richness of the text embedding space and utilize text embedding of pretrained VLM models to augment PVM image features for better data selection and finetuning. Furthermore, the flexibility of text-domain augmentation gives VeCAF a unique ability to handle out-of-distribution scenarios without external augmented data. Extensive experiments show the leading performance and high efficiency of VeCAF that is superior to baselines in both in-distribution and out-of-distribution image classification tasks. On ImageNet, VeCAF needs up to 3.3x less training batches to reach the target performance compared to full finetuning and achieves 2.8% accuracy improvement over SOTA methods with the same number of batches.
InstructPix2NeRF: Instructed 3D Portrait Editing from a Single Image
Nov 06, 2023



With the success of Neural Radiance Field (NeRF) in 3D-aware portrait editing, a variety of works have achieved promising results regarding both quality and 3D consistency. However, these methods heavily rely on per-prompt optimization when handling natural language as editing instructions. Due to the lack of labeled human face 3D datasets and effective architectures, the area of human-instructed 3D-aware editing for open-world portraits in an end-to-end manner remains under-explored. To solve this problem, we propose an end-to-end diffusion-based framework termed InstructPix2NeRF, which enables instructed 3D-aware portrait editing from a single open-world image with human instructions. At its core lies a conditional latent 3D diffusion process that lifts 2D editing to 3D space by learning the correlation between the paired images' difference and the instructions via triplet data. With the help of our proposed token position randomization strategy, we could even achieve multi-semantic editing through one single pass with the portrait identity well-preserved. Besides, we further propose an identity consistency module that directly modulates the extracted identity signals into our diffusion process, which increases the multi-view 3D identity consistency. Extensive experiments verify the effectiveness of our method and show its superiority against strong baselines quantitatively and qualitatively.