 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Dimension-Free Communication in Federated Learning via Zeroth-Order Optimization
Paper and Code
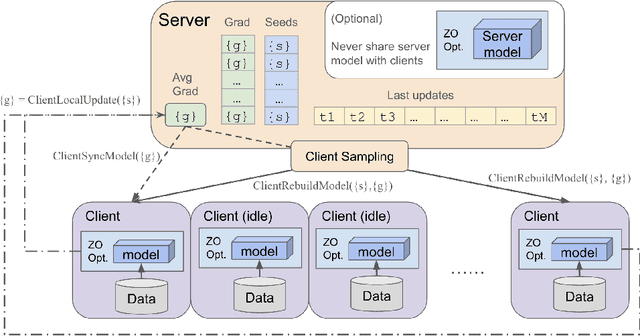



Federated Learning (FL) offers a promising framework for collaborative and privacy-preserving machine learning across distributed data sources. However, the substantial communication costs associated with FL pose a significant challenge to its efficiency. Specifically, in each communication round, the communication costs scale linearly with the model's dimension, which presents a formidable obstacle, especially in large model scenarios. Despite various communication efficient strategies, the intrinsic dimension-dependent communication cost remains a major bottleneck for current FL implementations. In this paper, we introduce a novel dimension-free communication strategy for FL, leveraging zero-order optimization techniques. We propose a new algorithm, FedDisco, which facilitates the transmission of only a constant number of scalar values between clients and the server in each communication round, thereby reducing the communication cost from $\mathscr{O}(d)$ to $\mathscr{O}(1)$, where $d$ is the dimension of the model parameters. Theoretically, in non-convex functions, we prove that our algorithm achieves state-of-the-art rates, which show a linear speedup of the number of clients and local steps under standard assumptions and dimension-free rate for low effective rank scenarios. Empirical evaluations through classic deep learning training and large language model fine-tuning substantiate significant reductions in communication overhead compared to traditional FL approaches.