 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Neural Video Representation via Online Structural Reparameterization
Nov 14, 2025Neural Video Representation~(NVR) is a promising paradigm for video compression, showing great potential in improving video storage and transmission efficiency. While recent advances have made efforts in architectural refinements to improve representational capability, these methods typically involve complex designs, which may incur increased computational overhead and lack the flexibility to integrate into other frameworks. Moreover, the inherent limitation in model capacity restricts the expressiveness of NVR networks, resulting in a performance bottleneck. To overcome these limitations, we propose Online-RepNeRV, a NVR framework based on online structural reparameterization. Specifically, we propose a universal reparameterization block named ERB, which incorporates multiple parallel convolutional paths to enhance the model capacity. To mitigate the overhead, an online reparameterization strategy is adopted to dynamically fuse the parameters during training, and the multi-branch structure is equivalently converted into a single-branch structure after training. As a result, the additional computational and parameter complexity is confined to the encoding stage, without affecting the decoding efficiency. Extensive experiments on mainstream video datasets demonstrate that our method achieves an average PSNR gain of 0.37-2.7 dB over baseline methods, while maintaining comparable training time and decoding speed.
* 15 pages, 7 figures
CFNet: Cascade Fusion Network for Dense Prediction
Feb 13, 2023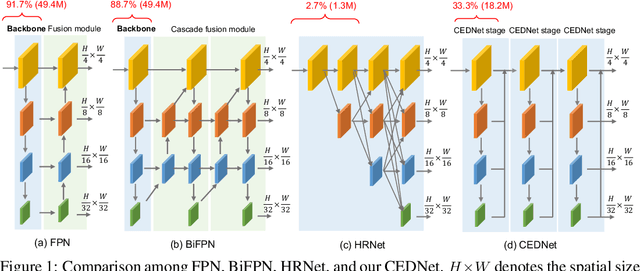
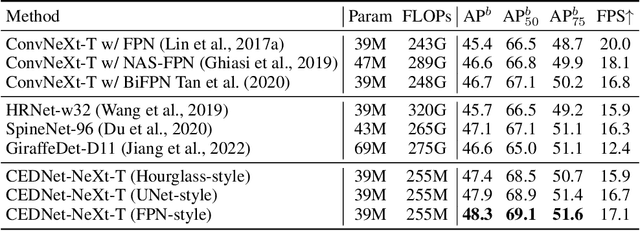
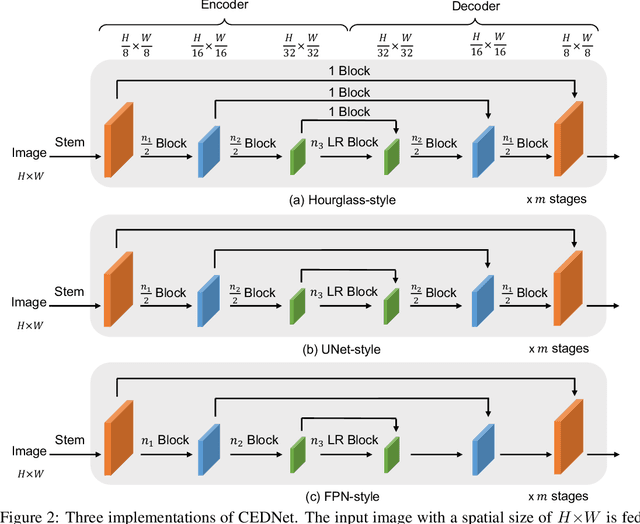
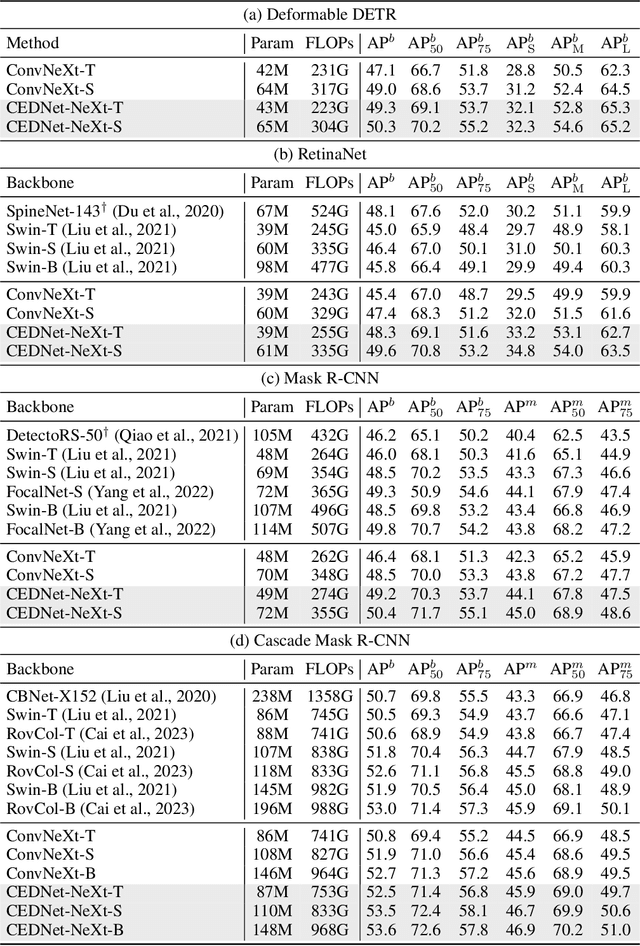
Multi-scale features are essential for dense prediction tasks, including object detection, instance segmentation, and semantic segmentation. Existing state-of-the-art methods usually first extract multi-scale features by a classification backbone and then fuse these features by a lightweight module (e.g. the fusion module in FPN). However, we argue that it may not be sufficient to fuse the multi-scale features through such a paradigm, because the parameters allocated for feature fusion are limited compared with the heavy classification backbone. In order to address this issue, we propose a new architecture named Cascade Fusion Network (CFNet) for dense prediction. Besides the stem and several blocks used to extract initial high-resolution features, we introduce several cascaded stages to generate multi-scale features in CFNet. Each stage includes a sub-backbone for feature extraction and an extremely lightweight transition block for feature integration. This design makes it possible to fuse features more deeply and effectively with a large proportion of parameters of the whole backbone. Extensive experiments on object detection, instance segmentation, and semantic segmentation validated the effectiveness of the proposed CFNet. Codes will be available at https://github.com/zhanggang001/CFNet.
Guiding Text-to-Image Diffusion Model Towards Grounded Generation
Jan 12, 2023

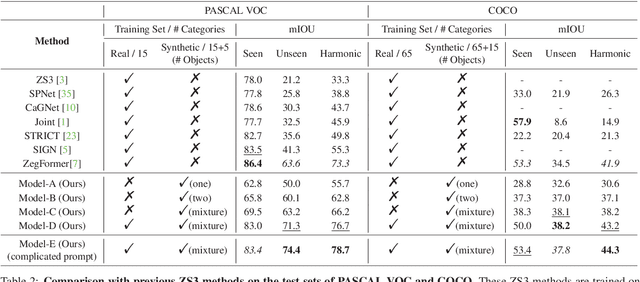

The goal of this paper is to augment a pre-trained text-to-image diffusion model with the ability of open-vocabulary objects grounding, i.e., simultaneously generating images and segmentation masks for the corresponding visual entities described in the text prompt. We make the following contributions: (i) we insert a grounding module into the existing diffusion model, that can be trained to align the visual and textual embedding space of the diffusion model with only a small number of object categories; (ii) we propose an automatic pipeline for constructing a dataset, that consists of {image, segmentation mask, text prompt} triplets, to train the proposed grounding module; (iii) we evaluate the performance of open-vocabulary grounding on images generated from the text-to-image diffusion model and show that the module can well segment the objects of categories beyond seen ones at training time; (iv) we adopt the guided diffusion model to build a synthetic semantic segmentation dataset, and show that training a standard segmentation model on such dataset demonstrates competitive performance on zero-shot segmentation(ZS3) benchmark, which opens up new opportunities for adopting the powerful diffusion model for discriminative tasks.
A Simple Plugin for Transforming Images to Arbitrary Scales
Oct 07, 2022
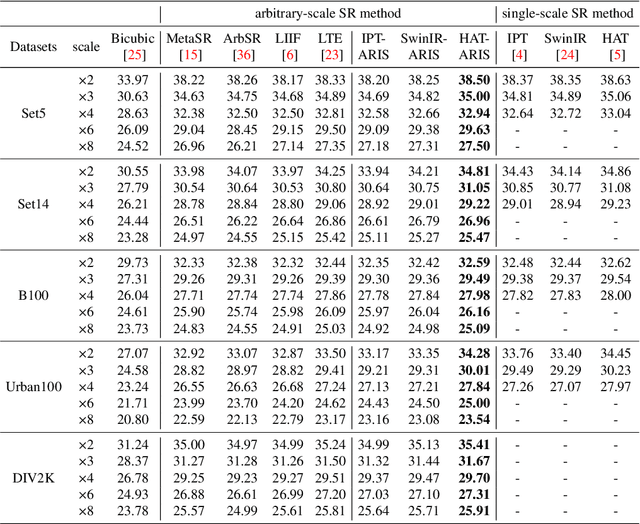


Existing models on super-resolution often specialized for one scale, fundamentally limiting their use in practical scenarios. In this paper, we aim to develop a general plugin that can be inserted into existing super-resolution models, conveniently augmenting their ability towards Arbitrary Resolution Image Scaling, thus termed ARIS. We make the following contributions: (i) we propose a transformer-based plugin module, which uses spatial coordinates as query, iteratively attend the low-resolution image feature through cross-attention, and output visual feature for the queried spatial location, resembling an implicit representation for images; (ii) we introduce a novel self-supervised training scheme, that exploits consistency constraints to effectively augment the model's ability for upsampling images towards unseen scales, i.e. ground-truth high-resolution images are not available; (iii) without loss of generality, we inject the proposed ARIS plugin module into several existing models, namely, IPT, SwinIR, and HAT, showing that the resulting models can not only maintain their original performance on fixed scale factor but also extrapolate to unseen scales, substantially outperforming existing any-scale super-resolution models on standard benchmarks, e.g. Urban100, DIV2K, etc.