 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple Plugin for Transforming Images to Arbitrary Scales
Paper and Code

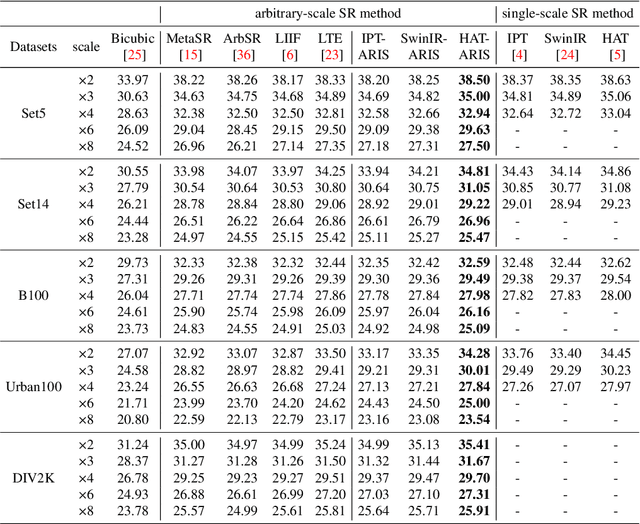


Existing models on super-resolution often specialized for one scale, fundamentally limiting their use in practical scenarios. In this paper, we aim to develop a general plugin that can be inserted into existing super-resolution models, conveniently augmenting their ability towards Arbitrary Resolution Image Scaling, thus termed ARIS. We make the following contributions: (i) we propose a transformer-based plugin module, which uses spatial coordinates as query, iteratively attend the low-resolution image feature through cross-attention, and output visual feature for the queried spatial location, resembling an implicit representation for images; (ii) we introduce a novel self-supervised training scheme, that exploits consistency constraints to effectively augment the model's ability for upsampling images towards unseen scales, i.e. ground-truth high-resolution images are not available; (iii) without loss of generality, we inject the proposed ARIS plugin module into several existing models, namely, IPT, SwinIR, and HAT, showing that the resulting models can not only maintain their original performance on fixed scale factor but also extrapolate to unseen scales, substantially outperforming existing any-scale super-resolution models on standard benchmarks, e.g. Urban100, DIV2K, etc.