 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Text-to-Image Diffusion Model Towards Grounded Generation
Jan 12, 2023

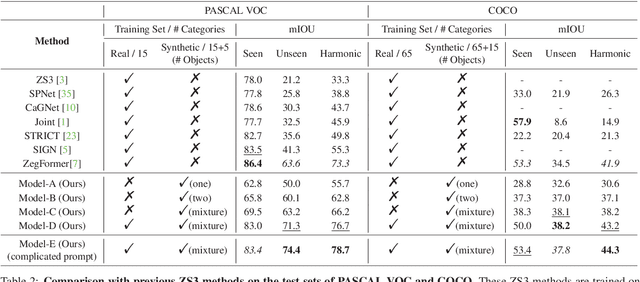

The goal of this paper is to augment a pre-trained text-to-image diffusion model with the ability of open-vocabulary objects grounding, i.e., simultaneously generating images and segmentation masks for the corresponding visual entities described in the text prompt. We make the following contributions: (i) we insert a grounding module into the existing diffusion model, that can be trained to align the visual and textual embedding space of the diffusion model with only a small number of object categories; (ii) we propose an automatic pipeline for constructing a dataset, that consists of {image, segmentation mask, text prompt} triplets, to train the proposed grounding module; (iii) we evaluate the performance of open-vocabulary grounding on images generated from the text-to-image diffusion model and show that the module can well segment the objects of categories beyond seen ones at training time; (iv) we adopt the guided diffusion model to build a synthetic semantic segmentation dataset, and show that training a standard segmentation model on such dataset demonstrates competitive performance on zero-shot segmentation(ZS3) benchmark, which opens up new opportunities for adopting the powerful diffusion model for discriminative tasks.
A Simple Plugin for Transforming Images to Arbitrary Scales
Oct 07, 2022
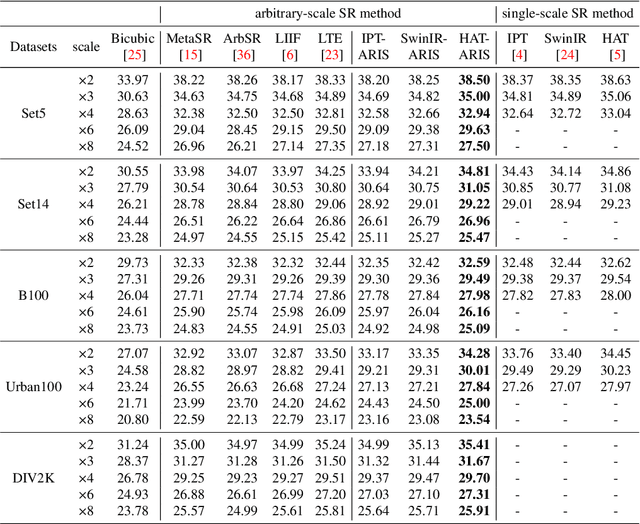


Existing models on super-resolution often specialized for one scale, fundamentally limiting their use in practical scenarios. In this paper, we aim to develop a general plugin that can be inserted into existing super-resolution models, conveniently augmenting their ability towards Arbitrary Resolution Image Scaling, thus termed ARIS. We make the following contributions: (i) we propose a transformer-based plugin module, which uses spatial coordinates as query, iteratively attend the low-resolution image feature through cross-attention, and output visual feature for the queried spatial location, resembling an implicit representation for images; (ii) we introduce a novel self-supervised training scheme, that exploits consistency constraints to effectively augment the model's ability for upsampling images towards unseen scales, i.e. ground-truth high-resolution images are not available; (iii) without loss of generality, we inject the proposed ARIS plugin module into several existing models, namely, IPT, SwinIR, and HAT, showing that the resulting models can not only maintain their original performance on fixed scale factor but also extrapolate to unseen scales, substantially outperforming existing any-scale super-resolution models on standard benchmarks, e.g. Urban100, DIV2K, etc.