 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Text-to-Image Diffusion Model Towards Grounded Generation
Paper and Code


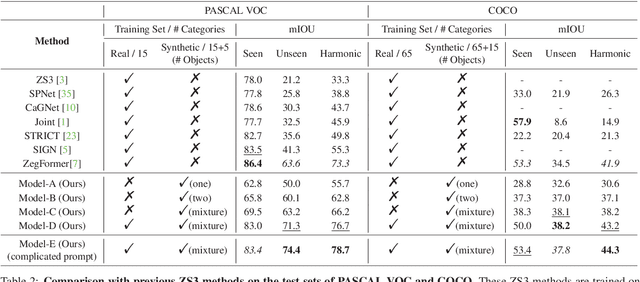

The goal of this paper is to augment a pre-trained text-to-image diffusion model with the ability of open-vocabulary objects grounding, i.e., simultaneously generating images and segmentation masks for the corresponding visual entities described in the text prompt. We make the following contributions: (i) we insert a grounding module into the existing diffusion model, that can be trained to align the visual and textual embedding space of the diffusion model with only a small number of object categories; (ii) we propose an automatic pipeline for constructing a dataset, that consists of {image, segmentation mask, text prompt} triplets, to train the proposed grounding module; (iii) we evaluate the performance of open-vocabulary grounding on images generated from the text-to-image diffusion model and show that the module can well segment the objects of categories beyond seen ones at training time; (iv) we adopt the guided diffusion model to build a synthetic semantic segmentation dataset, and show that training a standard segmentation model on such dataset demonstrates competitive performance on zero-shot segmentation(ZS3) benchmark, which opens up new opportunities for adopting the powerful diffusion model for discriminative tasks.