 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Integer-Only Deep Recurrent Neural Networks
Dec 22, 2022Recurrent neural networks (RNN) are the backbone of many text and speech applications. These architectures are typically made up of several computationally complex components such as; non-linear activation functions, normalization, bi-directional dependence and attention. In order to maintain good accuracy, these components are frequently run using full-precision floating-point computation, making them slow, inefficient and difficult to deploy on edge devices. In addition, the complex nature of these operations makes them challenging to quantize using standard quantization methods without a significant performance drop. We present a quantization-aware training method for obtaining a highly accurate integer-only recurrent neural network (iRNN). Our approach supports layer normalization, attention, and an adaptive piecewise linear (PWL) approximation of activation functions, to serve a wide range of state-of-the-art RNNs. The proposed method enables RNN-based language models to run on edge devices with $2\times$ improvement in runtime, and $4\times$ reduction in model size while maintaining similar accuracy as its full-precision counterpart.
DenseShift: Towards Accurate and Transferable Low-Bit Shift Network
Aug 20, 2022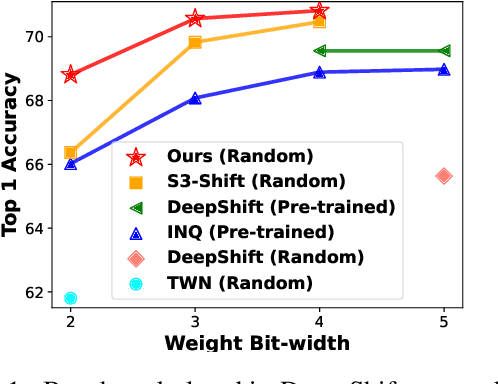
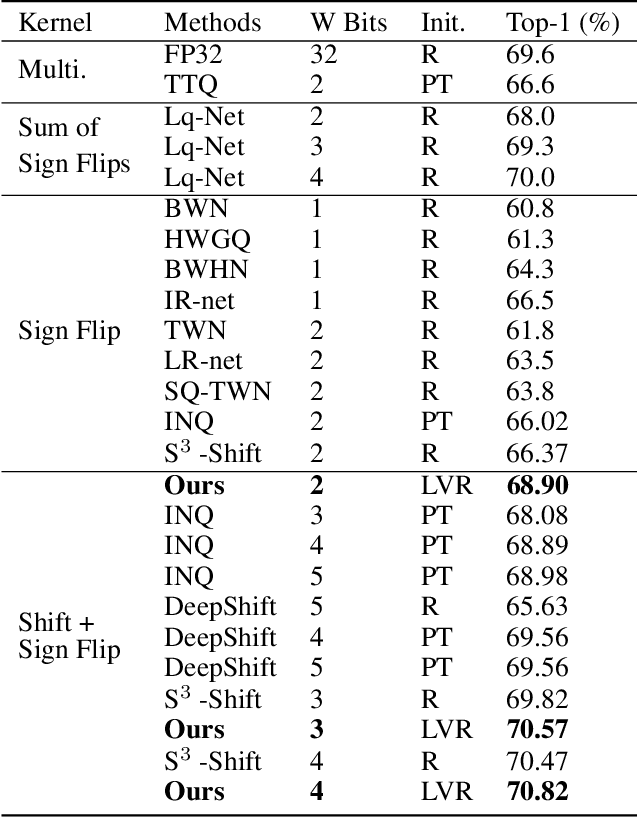
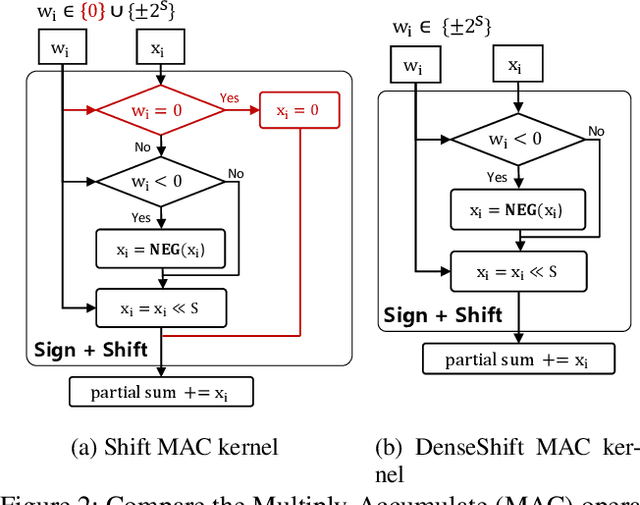
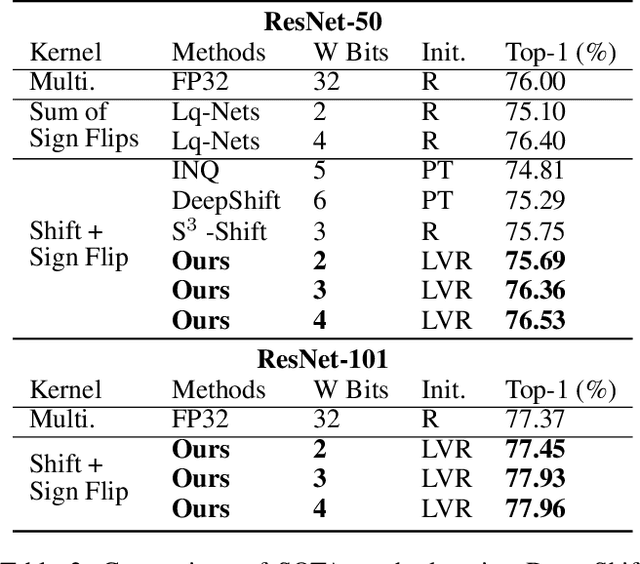
Deploying deep neural networks on low-resource edge devices is challenging due to their ever-increasing resource requirements. Recent investigations propose multiplication-free neural networks to reduce computation and memory consumption. Shift neural network is one of the most effective tools towards these reductions. However, existing low-bit shift networks are not as accurate as their full precision counterparts and cannot efficiently transfer to a wide range of tasks due to their inherent design flaws. We propose DenseShift network that exploits the following novel designs. First, we demonstrate that the zero-weight values in low-bit shift networks are neither useful to the model capacity nor simplify the model inference. Therefore, we propose to use a zero-free shifting mechanism to simplify inference while increasing the model capacity. Second, we design a new metric to measure the weight freezing issue in training low-bit shift networks, and propose a sign-scale decomposition to improve the training efficiency. Third, we propose the low-variance random initialization strategy to improve the model's performance in transfer learning scenarios. We run extensive experiments on various computer vision and speech tasks. The experimental results show that DenseShift network significantly outperforms existing low-bit multiplication-free networks and can achieve competitive performance to the full-precision counterpart. It also exhibits strong transfer learning performance with no drop in accuracy.
iRNN: Integer-only Recurrent Neural Network
Sep 20, 2021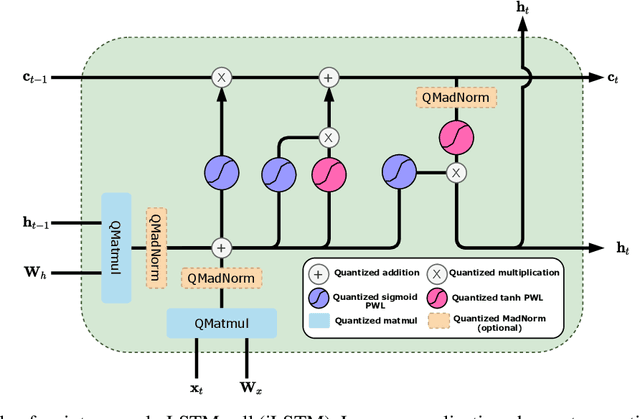

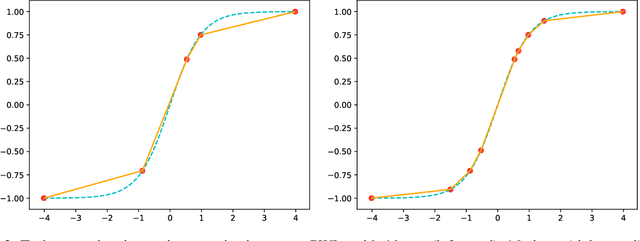

Recurrent neural networks (RNN) are used in many real-world text and speech applications. They include complex modules such as recurrence, exponential-based activation, gate interaction, unfoldable normalization, bi-directional dependence, and attention. The interaction between these elements prevents running them on integer-only operations without a significant performance drop. Deploying RNNs that include layer normalization and attention on integer-only arithmetic is still an open problem. We present a quantization-aware training method for obtaining a highly accurate integer-only recurrent neural network (iRNN). Our approach supports layer normalization, attention, and an adaptive piecewise linear approximation of activations, to serve a wide range of RNNs on various applications. The proposed method is proven to work on RNN-based language models and automatic speech recognition. Our iRNN maintains similar performance as its full-precision counterpart, their deployment on smartphones improves the runtime performance by $2\times$, and reduces the model size by $4\times$.