 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Training Under Limited Resources
Jan 23, 2023Training time budget and size of the dataset are among the factors affecting the performance of a Deep Neural Network (DNN). This paper shows that Neural Architecture Search (NAS), Hyper Parameters Optimization (HPO), and Data Augmentation help DNNs perform much better while these two factors are limited. However, searching for an optimal architecture and the best hyperparameter values besides a good combination of data augmentation techniques under low resources requires many experiments. We present our approach to achieving such a goal in three steps: reducing training epoch time by compressing the model while maintaining the performance compared to the original model, preventing model overfitting when the dataset is small, and performing the hyperparameter tuning. We used NOMAD, which is a blackbox optimization software based on a derivative-free algorithm to do NAS and HPO. Our work achieved an accuracy of 86.0 % on a tiny subset of Mini-ImageNet at the ICLR 2021 Hardware Aware Efficient Training (HAET) Challenge and won second place in the competition. The competition results can be found at haet2021.github.io/challenge and our source code can be found at github.com/DouniaLakhmiri/ICLR\_HAET2021.
Training Integer-Only Deep Recurrent Neural Networks
Dec 22, 2022Recurrent neural networks (RNN) are the backbone of many text and speech applications. These architectures are typically made up of several computationally complex components such as; non-linear activation functions, normalization, bi-directional dependence and attention. In order to maintain good accuracy, these components are frequently run using full-precision floating-point computation, making them slow, inefficient and difficult to deploy on edge devices. In addition, the complex nature of these operations makes them challenging to quantize using standard quantization methods without a significant performance drop. We present a quantization-aware training method for obtaining a highly accurate integer-only recurrent neural network (iRNN). Our approach supports layer normalization, attention, and an adaptive piecewise linear (PWL) approximation of activation functions, to serve a wide range of state-of-the-art RNNs. The proposed method enables RNN-based language models to run on edge devices with $2\times$ improvement in runtime, and $4\times$ reduction in model size while maintaining similar accuracy as its full-precision counterpart.
Demystifying and Generalizing BinaryConnect
Oct 25, 2021

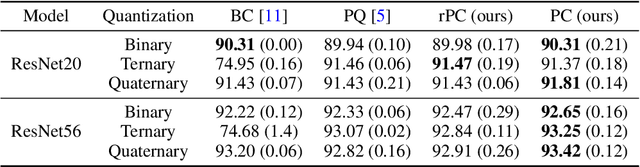
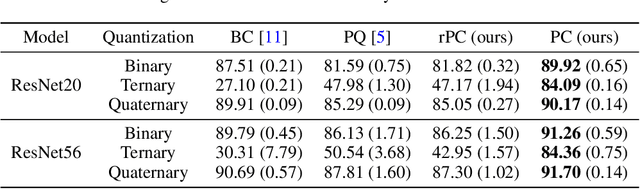
BinaryConnect (BC) and its many variations have become the de facto standard for neural network quantization. However, our understanding of the inner workings of BC is still quite limited. We attempt to close this gap in four different aspects: (a) we show that existing quantization algorithms, including post-training quantization, are surprisingly similar to each other; (b) we argue for proximal maps as a natural family of quantizers that is both easy to design and analyze; (c) we refine the observation that BC is a special case of dual averaging, which itself is a special case of the generalized conditional gradient algorithm; (d) consequently, we propose ProxConnect (PC) as a generalization of BC and we prove its convergence properties by exploiting the established connections. We conduct experiments on CIFAR-10 and ImageNet, and verify that PC achieves competitive performance.
iRNN: Integer-only Recurrent Neural Network
Sep 20, 2021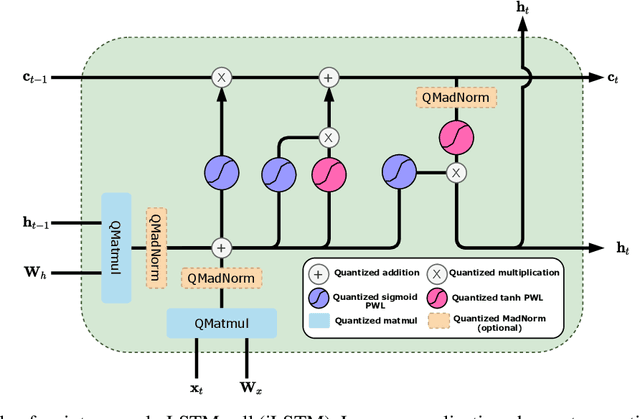

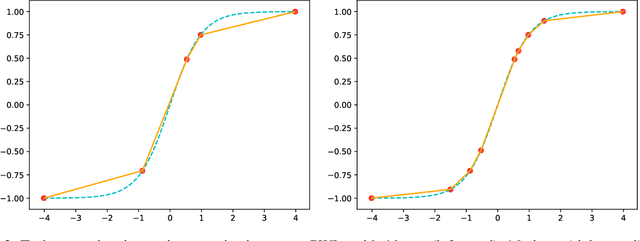

Recurrent neural networks (RNN) are used in many real-world text and speech applications. They include complex modules such as recurrence, exponential-based activation, gate interaction, unfoldable normalization, bi-directional dependence, and attention. The interaction between these elements prevents running them on integer-only operations without a significant performance drop. Deploying RNNs that include layer normalization and attention on integer-only arithmetic is still an open problem. We present a quantization-aware training method for obtaining a highly accurate integer-only recurrent neural network (iRNN). Our approach supports layer normalization, attention, and an adaptive piecewise linear approximation of activations, to serve a wide range of RNNs on various applications. The proposed method is proven to work on RNN-based language models and automatic speech recognition. Our iRNN maintains similar performance as its full-precision counterpart, their deployment on smartphones improves the runtime performance by $2\times$, and reduces the model size by $4\times$.
Batch Normalization in Quantized Networks
Apr 29, 2020Implementation of quantized neural networks on computing hardware leads to considerable speed up and memory saving. However, quantized deep networks are difficult to train and batch~normalization (BatchNorm) layer plays an important role in training full-precision and quantized networks. Most studies on BatchNorm are focused on full-precision networks, and there is little research in understanding BatchNorm affect in quantized training which we address here. We show BatchNorm avoids gradient explosion which is counter-intuitive and recently observed in numerical experiments by other researchers.
How Does Batch Normalization Help Binary Training?
Oct 10, 2019

Binary Neural Networks (BNNs) are difficult to train, and suffer from drop of accuracy. It appears in practice that BNNs fail to train in the absence of Batch Normalization (BatchNorm) layer. We find the main role of BatchNorm is to avoid exploding gradients in the case of BNNs. This finding suggests that the common initialization methods developed for full-precision networks are irrelevant to BNNs. We build a theoretical study on the role of BatchNorm in binary training, backed up by numerical experiments.
Smart Ternary Quantization
Sep 26, 2019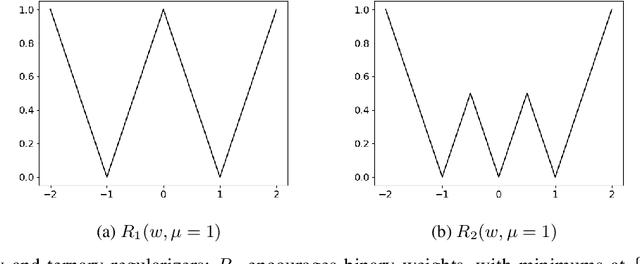
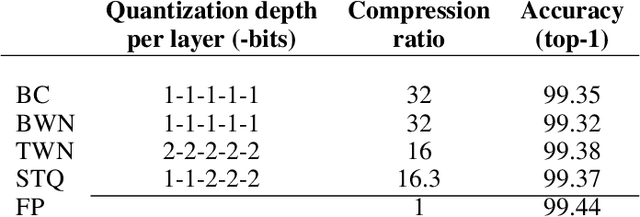
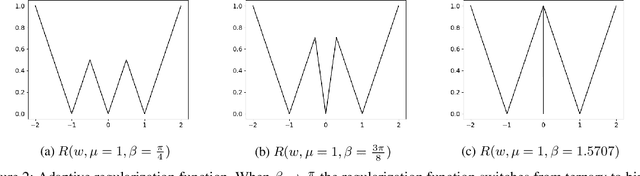

Neural network models are resource hungry. Low bit quantization such as binary and ternary quantization is a common approach to alleviate this resource requirements. Ternary quantization provides a more flexible model and often beats binary quantization in terms of accuracy, but doubles memory and increases computation cost. Mixed quantization depth models, on another hand, allows a trade-off between accuracy and memory footprint. In such models, quantization depth is often chosen manually (which is a tiring task), or is tuned using a separate optimization routine (which requires training a quantized network multiple times). Here, we propose Smart Ternary Quantization (STQ) in which we modify the quantization depth directly through an adaptive regularization function, so that we train a model only once. This method jumps between binary and ternary quantization while training. We show its application on image classification.
Differentiable Mask Pruning for Neural Networks
Sep 10, 2019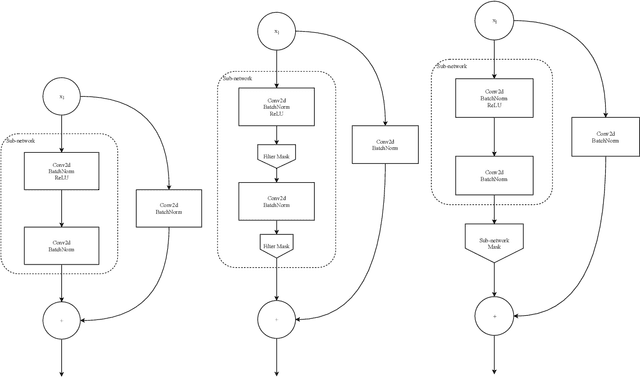
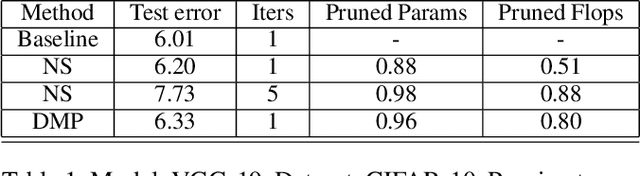
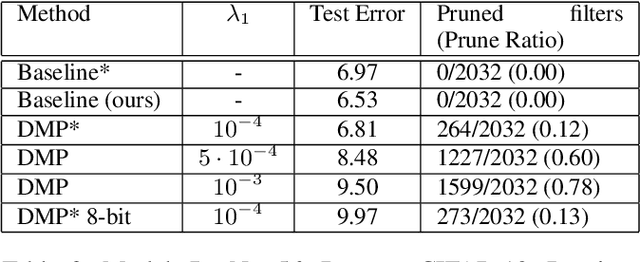
Pruning of neural networks is one of the well-known and promising model simplification techniques. Most neural network models are large and require expensive computations to predict new instances. It is imperative to compress the network to deploy models on low resource devices. Most compression techniques, especially pruning have been focusing on computer vision and convolution neural networks. Existing techniques are complex and require multi-stage optimization and fine-tuning to recover the state-of-the-art accuracy. We introduce a \emph{Differentiable Mask Pruning} (DMP), that simplifies the network while training, and can be used to induce sparsity on weight, filter, node or sub-network. Our method achieves competitive results on standard vision and NLP benchmarks, and is easy to integrate within the deep learning toolbox. DMP bridges the gap between neural model compression and differentiable neural architecture search.
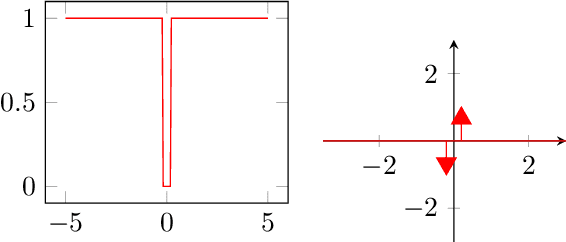
Foothill: A Quasiconvex Regularization Function
Jan 18, 2019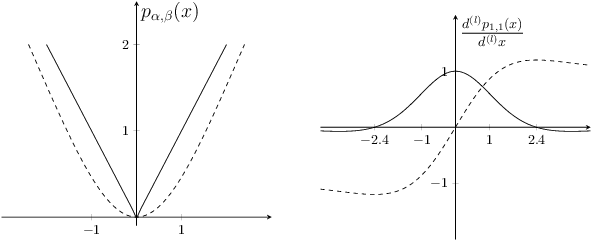

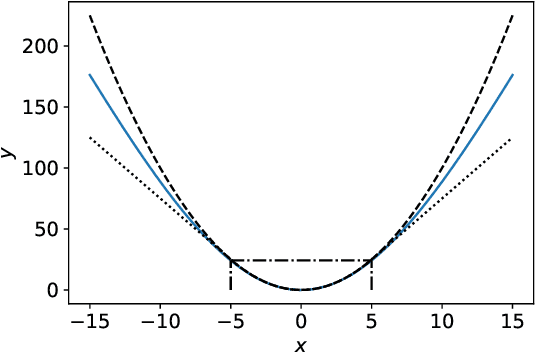
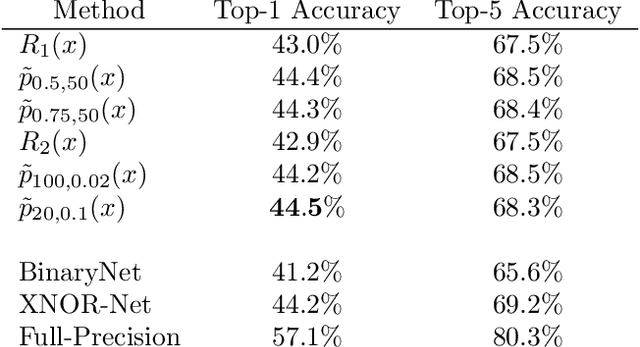
Deep neural networks (DNNs) have demonstrated success for many supervised learning tasks, ranging from voice recognition, object detection, to image classification. However, their increasing complexity yields poor generalization error. Adding noise to the input data or using a concrete regularization function helps to improve generalization. Here we introduce foothill function, an infinitely differentiable quasiconvex function. This regularizer is flexible enough to deform towards $L_1$ and $L_2$ penalties. Foothill can be used as a loss, as a regularizer, or as a binary quantizer.