 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Mask Pruning for Neural Networks
Paper and Code
Sep 10, 2019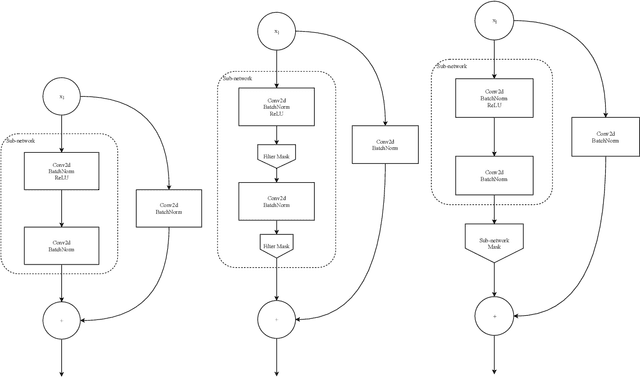
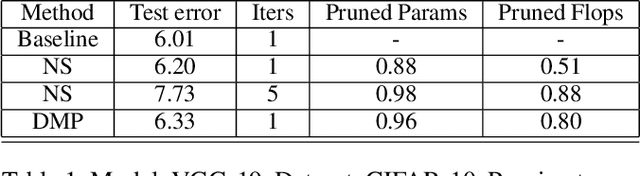
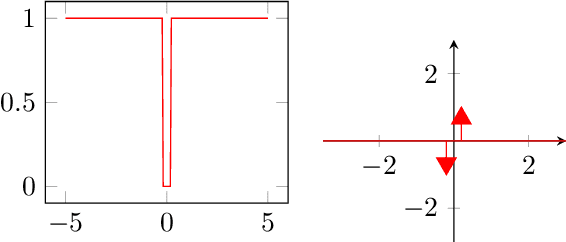
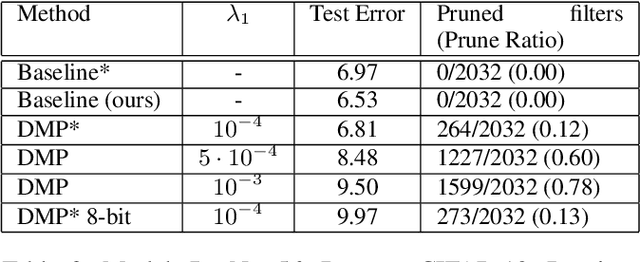
Pruning of neural networks is one of the well-known and promising model simplification techniques. Most neural network models are large and require expensive computations to predict new instances. It is imperative to compress the network to deploy models on low resource devices. Most compression techniques, especially pruning have been focusing on computer vision and convolution neural networks. Existing techniques are complex and require multi-stage optimization and fine-tuning to recover the state-of-the-art accuracy. We introduce a \emph{Differentiable Mask Pruning} (DMP), that simplifies the network while training, and can be used to induce sparsity on weight, filter, node or sub-network. Our method achieves competitive results on standard vision and NLP benchmarks, and is easy to integrate within the deep learning toolbox. DMP bridges the gap between neural model compression and differentiable neural architecture search.