 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Training Under Limited Resources
Jan 23, 2023Training time budget and size of the dataset are among the factors affecting the performance of a Deep Neural Network (DNN). This paper shows that Neural Architecture Search (NAS), Hyper Parameters Optimization (HPO), and Data Augmentation help DNNs perform much better while these two factors are limited. However, searching for an optimal architecture and the best hyperparameter values besides a good combination of data augmentation techniques under low resources requires many experiments. We present our approach to achieving such a goal in three steps: reducing training epoch time by compressing the model while maintaining the performance compared to the original model, preventing model overfitting when the dataset is small, and performing the hyperparameter tuning. We used NOMAD, which is a blackbox optimization software based on a derivative-free algorithm to do NAS and HPO. Our work achieved an accuracy of 86.0 % on a tiny subset of Mini-ImageNet at the ICLR 2021 Hardware Aware Efficient Training (HAET) Challenge and won second place in the competition. The competition results can be found at haet2021.github.io/challenge and our source code can be found at github.com/DouniaLakhmiri/ICLR\_HAET2021.
Scaling Deep Networks with the Mesh Adaptive Direct Search algorithm
Jan 17, 2023Deep neural networks are getting larger. Their implementation on edge and IoT devices becomes more challenging and moved the community to design lighter versions with similar performance. Standard automatic design tools such as \emph{reinforcement learning} and \emph{evolutionary computing} fundamentally rely on cheap evaluations of an objective function. In the neural network design context, this objective is the accuracy after training, which is expensive and time-consuming to evaluate. We automate the design of a light deep neural network for image classification using the \emph{Mesh Adaptive Direct Search}(MADS) algorithm, a mature derivative-free optimization method that effectively accounts for the expensive blackbox nature of the objective function to explore the design space, even in the presence of constraints.Our tests show competitive compression rates with reduced numbers of trials.
Rethinking Pareto Frontier for Performance Evaluation of Deep Neural Networks
Feb 18, 2022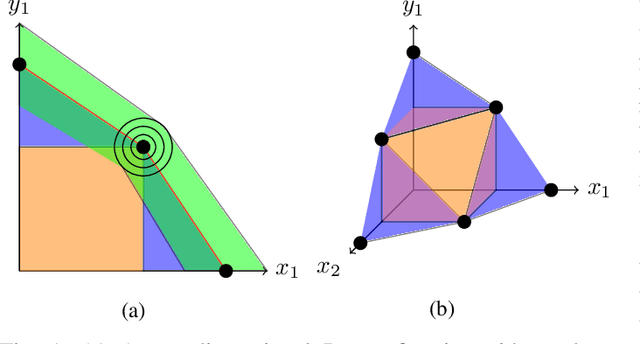
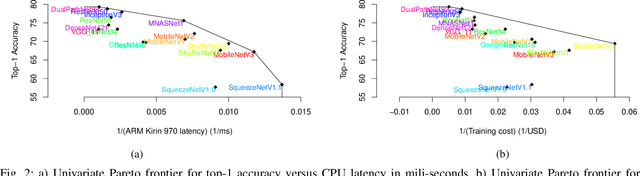
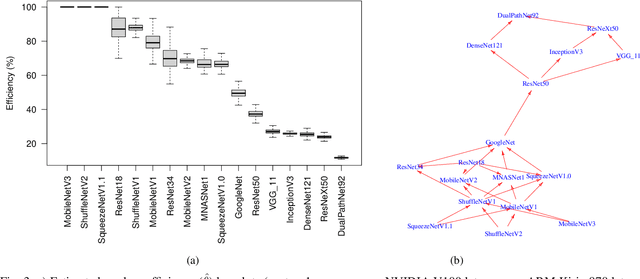

Recent efforts in deep learning show a considerable advancement in redesigning deep learning models for low-resource and edge devices. The performance optimization of deep learning models are conducted either manually or through automatic architecture search, or a combination of both. The throughput and power consumption of deep learning models strongly depend on the target hardware. We propose to use a \emph{multi-dimensional} Pareto frontier to re-define the efficiency measure using a multi-objective optimization, where other variables such as power consumption, latency, and accuracy play a relative role in defining a dominant model. Furthermore, a random version of the multi-dimensional Pareto frontier is introduced to mitigate the uncertainty of accuracy, latency, and throughput variations of deep learning models in different experimental setups. These two breakthroughs provide an objective benchmarking method for a wide range of deep learning models. We run our novel multi-dimensional stochastic relative efficiency on a wide range of deep image classification models trained ImageNet data. Thank to this new approach we combine competing variables with stochastic nature simultaneously in a single relative efficiency measure. This allows to rank deep models that run efficiently on different computing hardware, and combines inference efficiency with training efficiency objectively.
Demystifying and Generalizing BinaryConnect
Oct 25, 2021

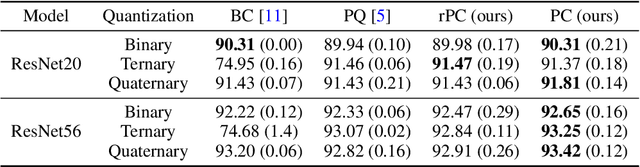
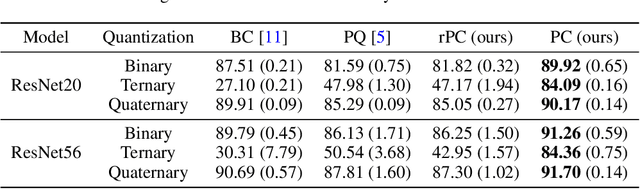
BinaryConnect (BC) and its many variations have become the de facto standard for neural network quantization. However, our understanding of the inner workings of BC is still quite limited. We attempt to close this gap in four different aspects: (a) we show that existing quantization algorithms, including post-training quantization, are surprisingly similar to each other; (b) we argue for proximal maps as a natural family of quantizers that is both easy to design and analyze; (c) we refine the observation that BC is a special case of dual averaging, which itself is a special case of the generalized conditional gradient algorithm; (d) consequently, we propose ProxConnect (PC) as a generalization of BC and we prove its convergence properties by exploiting the established connections. We conduct experiments on CIFAR-10 and ImageNet, and verify that PC achieves competitive performance.
Importance of Data Loading Pipeline in Training Deep Neural Networks
Apr 21, 2020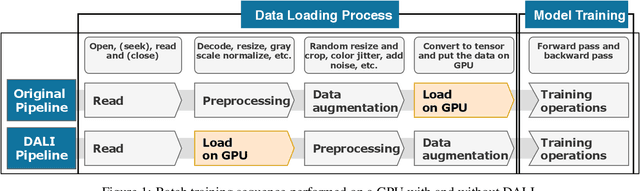
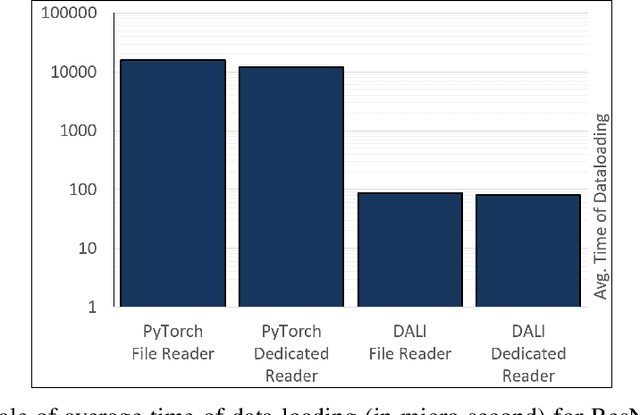
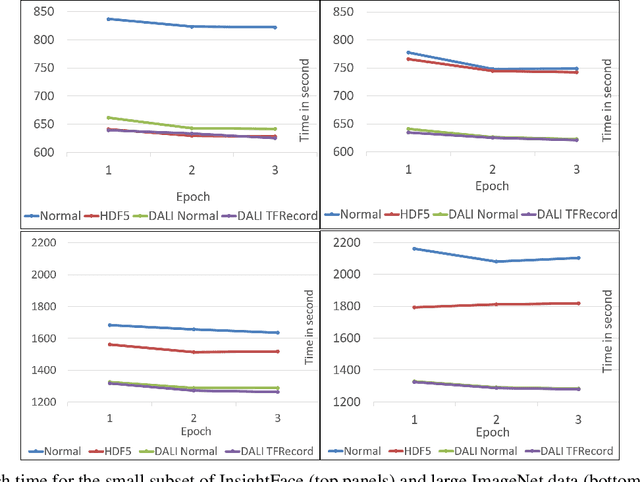
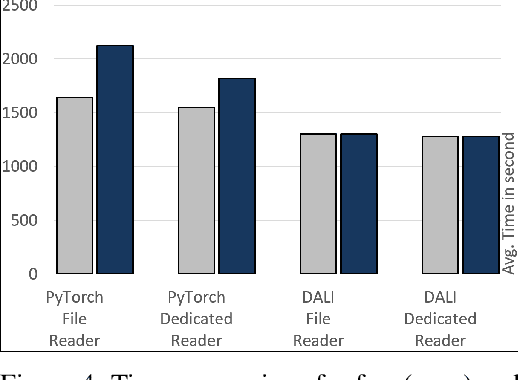
Training large-scale deep neural networks is a long, time-consuming operation, often requiring many GPUs to accelerate. In large models, the time spent loading data takes a significant portion of model training time. As GPU servers are typically expensive, tricks that can save training time are valuable.Slow training is observed especially on real-world applications where exhaustive data augmentation operations are required. Data augmentation techniques include: padding, rotation, adding noise, down sampling, up sampling, etc. These additional operations increase the need to build an efficient data loading pipeline, and to explore existing tools to speed up training time. We focus on the comparison of two main tools designed for this task, namely binary data format to accelerate data reading, and NVIDIA DALI to accelerate data augmentation. Our study shows improvement on the order of 20% to 40% if such dedicated tools are used.