 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Training Under Limited Resources
Jan 23, 2023Training time budget and size of the dataset are among the factors affecting the performance of a Deep Neural Network (DNN). This paper shows that Neural Architecture Search (NAS), Hyper Parameters Optimization (HPO), and Data Augmentation help DNNs perform much better while these two factors are limited. However, searching for an optimal architecture and the best hyperparameter values besides a good combination of data augmentation techniques under low resources requires many experiments. We present our approach to achieving such a goal in three steps: reducing training epoch time by compressing the model while maintaining the performance compared to the original model, preventing model overfitting when the dataset is small, and performing the hyperparameter tuning. We used NOMAD, which is a blackbox optimization software based on a derivative-free algorithm to do NAS and HPO. Our work achieved an accuracy of 86.0 % on a tiny subset of Mini-ImageNet at the ICLR 2021 Hardware Aware Efficient Training (HAET) Challenge and won second place in the competition. The competition results can be found at haet2021.github.io/challenge and our source code can be found at github.com/DouniaLakhmiri/ICLR\_HAET2021.
Scaling Deep Networks with the Mesh Adaptive Direct Search algorithm
Jan 17, 2023Deep neural networks are getting larger. Their implementation on edge and IoT devices becomes more challenging and moved the community to design lighter versions with similar performance. Standard automatic design tools such as \emph{reinforcement learning} and \emph{evolutionary computing} fundamentally rely on cheap evaluations of an objective function. In the neural network design context, this objective is the accuracy after training, which is expensive and time-consuming to evaluate. We automate the design of a light deep neural network for image classification using the \emph{Mesh Adaptive Direct Search}(MADS) algorithm, a mature derivative-free optimization method that effectively accounts for the expensive blackbox nature of the objective function to explore the design space, even in the presence of constraints.Our tests show competitive compression rates with reduced numbers of trials.
A Stochastic Proximal Method for Nonsmooth Regularized Finite Sum Optimization
Jun 16, 2022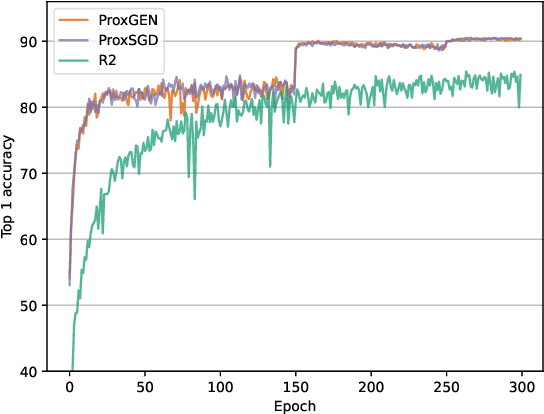
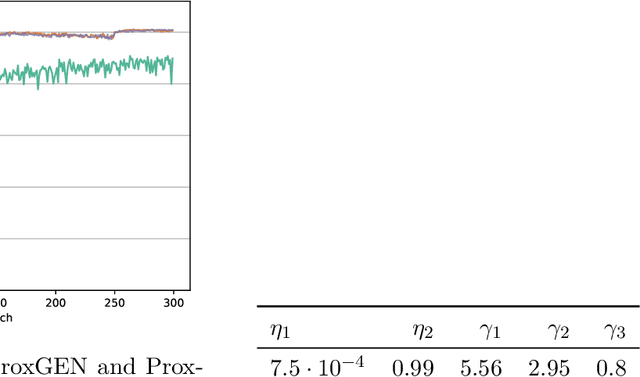
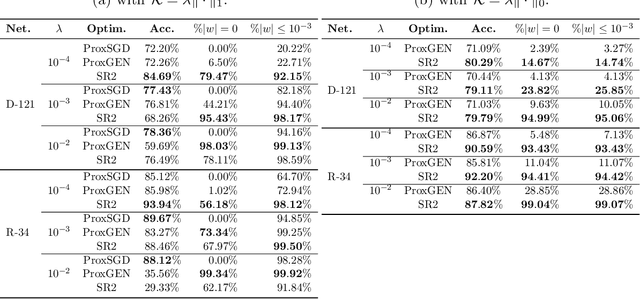
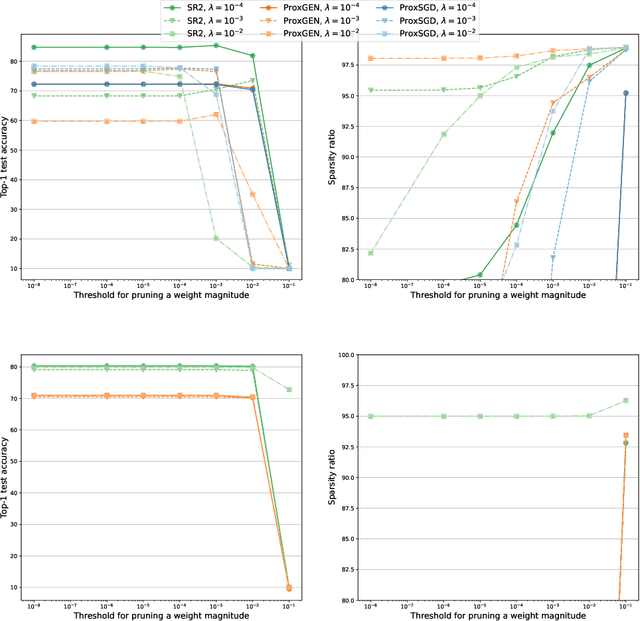
We consider the problem of training a deep neural network with nonsmooth regularization to retrieve a sparse and efficient sub-structure. Our regularizer is only assumed to be lower semi-continuous and prox-bounded. We combine an adaptive quadratic regularization approach with proximal stochastic gradient principles to derive a new solver, called SR2, whose convergence and worst-case complexity are established without knowledge or approximation of the gradient's Lipschitz constant. We formulate a stopping criteria that ensures an appropriate first-order stationarity measure converges to zero under certain conditions. We establish a worst-case iteration complexity of $\mathcal{O}(\epsilon^{-2})$ that matches those of related methods like ProxGEN, where the learning rate is assumed to be related to the Lipschitz constant. Our experiments on network instances trained on CIFAR-10 and CIFAR-100 with $\ell_1$ and $\ell_0$ regularizations show that SR2 consistently achieves higher sparsity and accuracy than related methods such as ProxGEN and ProxSGD.
Use of static surrogates in hyperparameter optimization
Mar 14, 2021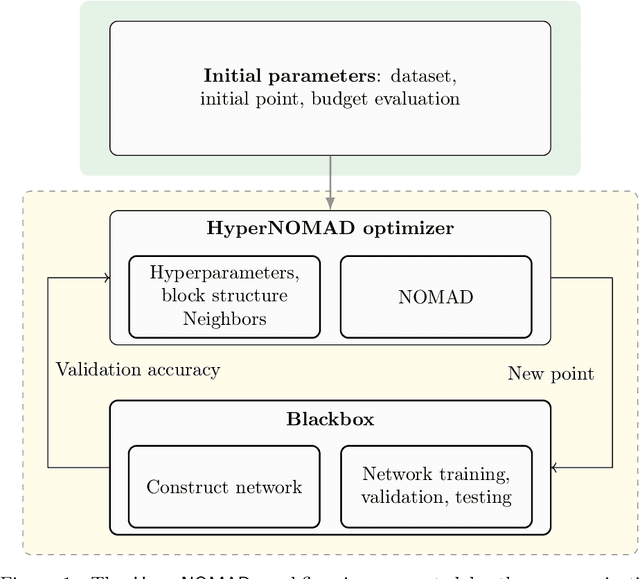
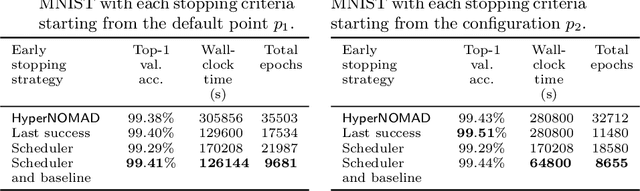
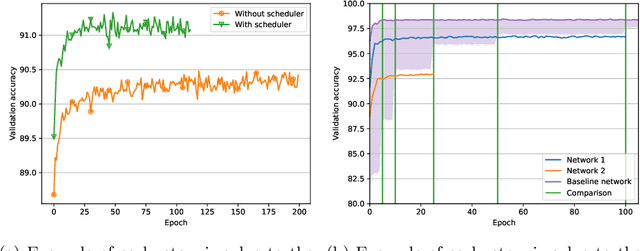
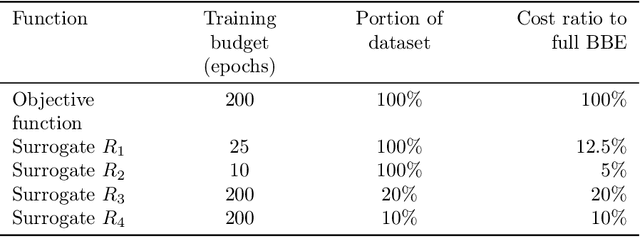
Optimizing the hyperparameters and architecture of a neural network is a long yet necessary phase in the development of any new application. This consuming process can benefit from the elaboration of strategies designed to quickly discard low quality configurations and focus on more promising candidates. This work aims at enhancing HyperNOMAD, a library that adapts a direct search derivative-free optimization algorithm to tune both the architecture and the training of a neural network simultaneously, by targeting two keys steps of its execution and exploiting cheap approximations in the form of static surrogates to trigger the early stopping of the evaluation of a configuration and the ranking of pools of candidates. These additions to HyperNOMAD are shown to improve on its resources consumption without harming the quality of the proposed solutions.
Tuning a variational autoencoder for data accountability problem in the Mars Science Laboratory ground data system
Jun 06, 2020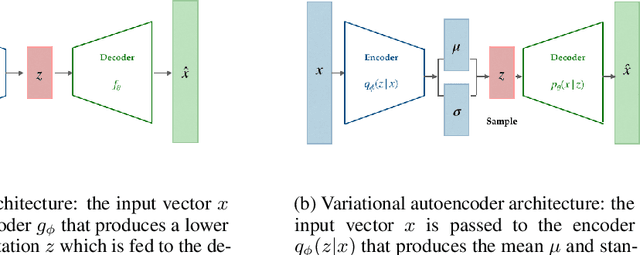

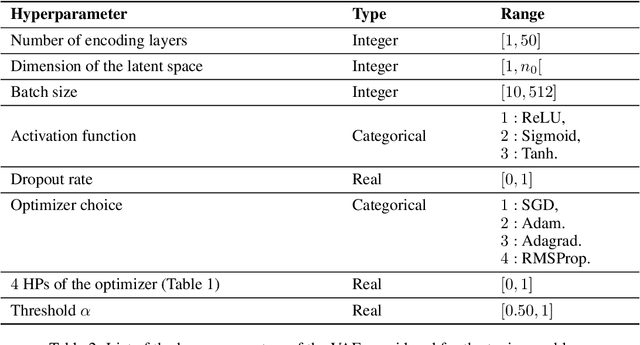
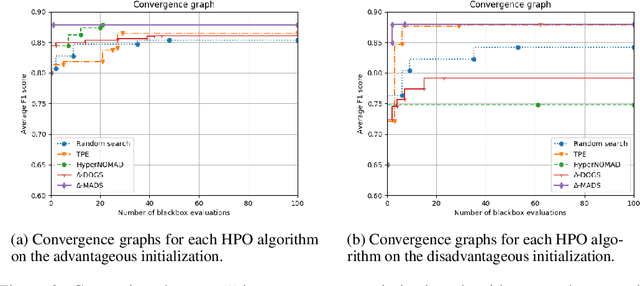
The Mars Curiosity rover is frequently sending back engineering and science data that goes through a pipeline of systems before reaching its final destination at the mission operations center making it prone to volume loss and data corruption. A ground data system analysis (GDSA) team is charged with the monitoring of this flow of information and the detection of anomalies in that data in order to request a re-transmission when necessary. This work presents $\Delta$-MADS, a derivative-free optimization method applied for tuning the architecture and hyperparameters of a variational autoencoder trained to detect the data with missing patches in order to assist the GDSA team in their mission.
HyperNOMAD: Hyperparameter optimization of deep neural networks using mesh adaptive direct search
Jul 03, 2019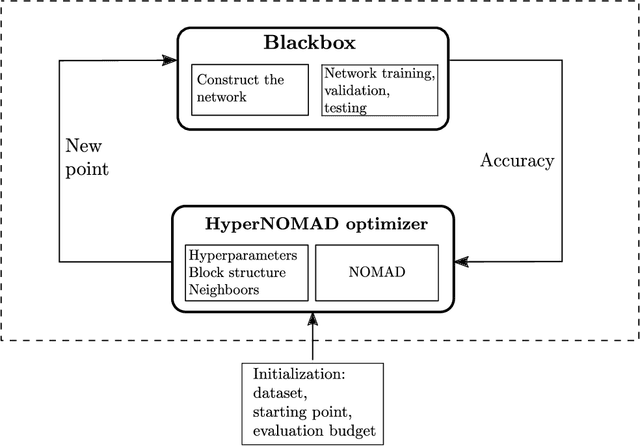
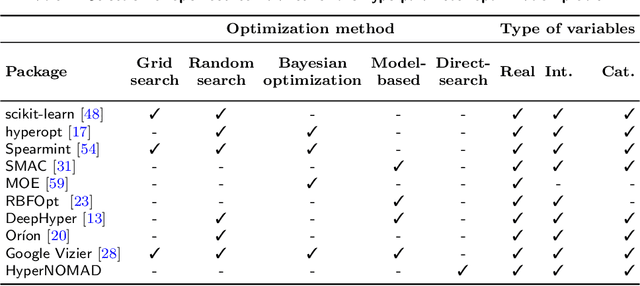
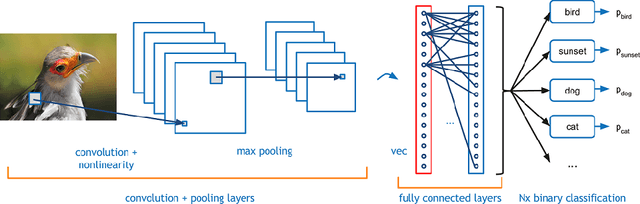
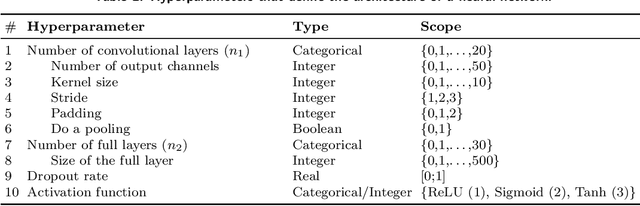
The performance of deep neural networks is highly sensitive to the choice of the hyperparameters that define the structure of the network and the learning process. When facing a new application, tuning a deep neural network is a tedious and time consuming process that is often described as a "dark art". This explains the necessity of automating the calibration of these hyperparameters. Derivative-free optimization is a field that develops methods designed to optimize time consuming functions without relying on derivatives. This work introduces the HyperNOMAD package, an extension of the NOMAD software that applies the MADS algorithm [7] to simultaneously tune the hyperparameters responsible for both the architecture and the learning process of a deep neural network (DNN), and that allows for an important flexibility in the exploration of the search space by taking advantage of categorical variables. This new approach is tested on the MNIST and CIFAR-10 data sets and achieves results comparable to the current state of the art.