 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Stochastic Proximal Method for Nonsmooth Regularized Finite Sum Optimization
Paper and Code
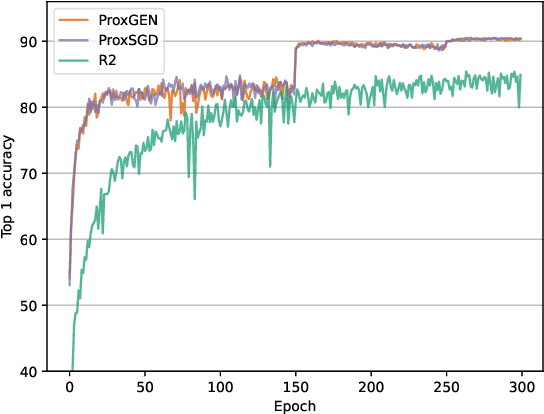
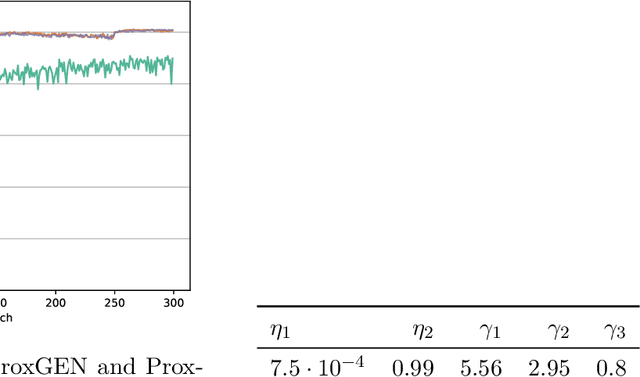
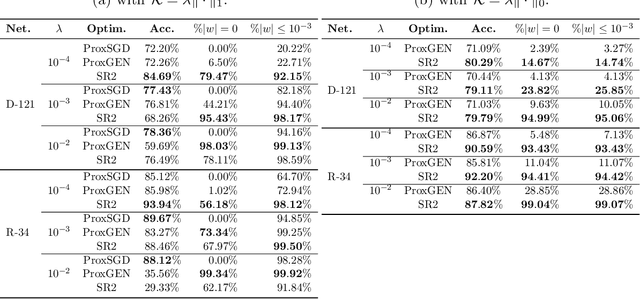
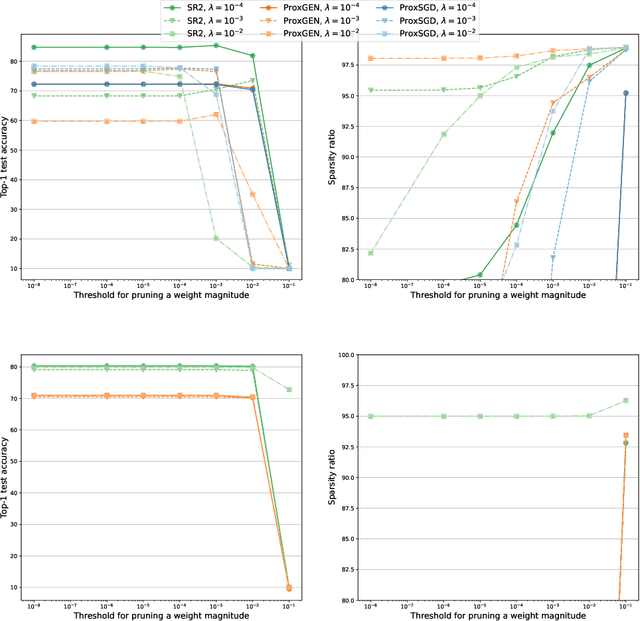
We consider the problem of training a deep neural network with nonsmooth regularization to retrieve a sparse and efficient sub-structure. Our regularizer is only assumed to be lower semi-continuous and prox-bounded. We combine an adaptive quadratic regularization approach with proximal stochastic gradient principles to derive a new solver, called SR2, whose convergence and worst-case complexity are established without knowledge or approximation of the gradient's Lipschitz constant. We formulate a stopping criteria that ensures an appropriate first-order stationarity measure converges to zero under certain conditions. We establish a worst-case iteration complexity of $\mathcal{O}(\epsilon^{-2})$ that matches those of related methods like ProxGEN, where the learning rate is assumed to be related to the Lipschitz constant. Our experiments on network instances trained on CIFAR-10 and CIFAR-100 with $\ell_1$ and $\ell_0$ regularizations show that SR2 consistently achieves higher sparsity and accuracy than related methods such as ProxGEN and ProxSGD.