 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Pareto Frontier for Performance Evaluation of Deep Neural Networks
Paper and Code
Feb 18, 2022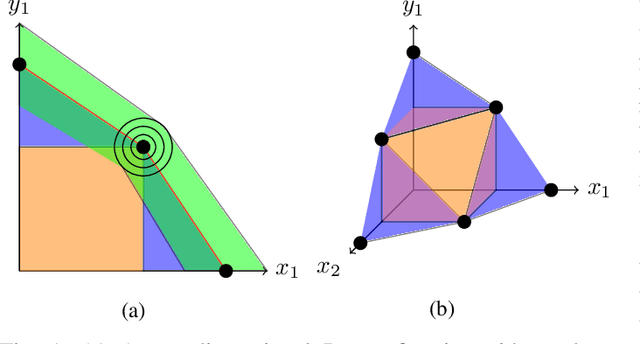
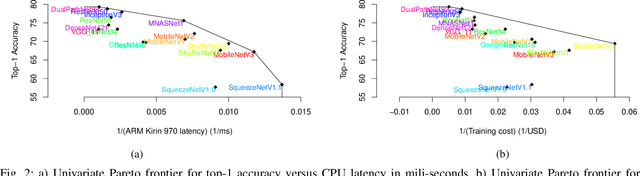
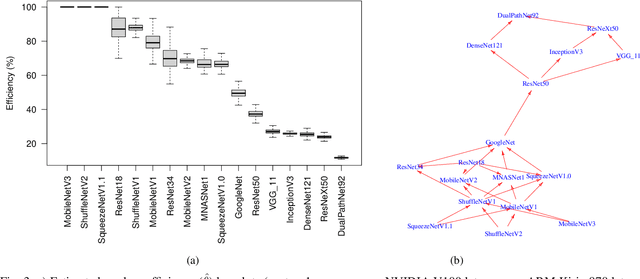

Recent efforts in deep learning show a considerable advancement in redesigning deep learning models for low-resource and edge devices. The performance optimization of deep learning models are conducted either manually or through automatic architecture search, or a combination of both. The throughput and power consumption of deep learning models strongly depend on the target hardware. We propose to use a \emph{multi-dimensional} Pareto frontier to re-define the efficiency measure using a multi-objective optimization, where other variables such as power consumption, latency, and accuracy play a relative role in defining a dominant model. Furthermore, a random version of the multi-dimensional Pareto frontier is introduced to mitigate the uncertainty of accuracy, latency, and throughput variations of deep learning models in different experimental setups. These two breakthroughs provide an objective benchmarking method for a wide range of deep learning models. We run our novel multi-dimensional stochastic relative efficiency on a wide range of deep image classification models trained ImageNet data. Thank to this new approach we combine competing variables with stochastic nature simultaneously in a single relative efficiency measure. This allows to rank deep models that run efficiently on different computing hardware, and combines inference efficiency with training efficiency objectively.