 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformal Prediction Sets Can Cause Disparate Impact
Oct 02, 2024Although conformal prediction is a promising method for quantifying the uncertainty of machine learning models, the prediction sets it outputs are not inherently actionable. Many applications require a single output to act on, not several. To overcome this, prediction sets can be provided to a human who then makes an informed decision. In any such system it is crucial to ensure the fairness of outcomes across protected groups, and researchers have proposed that Equalized Coverage be used as the standard for fairness. By conducting experiments with human participants, we demonstrate that providing prediction sets can increase the unfairness of their decisions. Disquietingly, we find that providing sets that satisfy Equalized Coverage actually increases unfairness compared to marginal coverage. Instead of equalizing coverage, we propose to equalize set sizes across groups which empirically leads to more fair outcomes.
Distilled ChatGPT Topic & Sentiment Modeling with Applications in Finance
Mar 04, 2024In this study, ChatGPT is utilized to create streamlined models that generate easily interpretable features. These features are then used to evaluate financial outcomes from earnings calls. We detail a training approach that merges knowledge distillation and transfer learning, resulting in lightweight topic and sentiment classification models without significant loss in accuracy. These models are assessed through a dataset annotated by experts. The paper also delves into two practical case studies, highlighting how the generated features can be effectively utilized in quantitative investing scenarios.
A Twin Neural Model for Uplift
May 11, 2021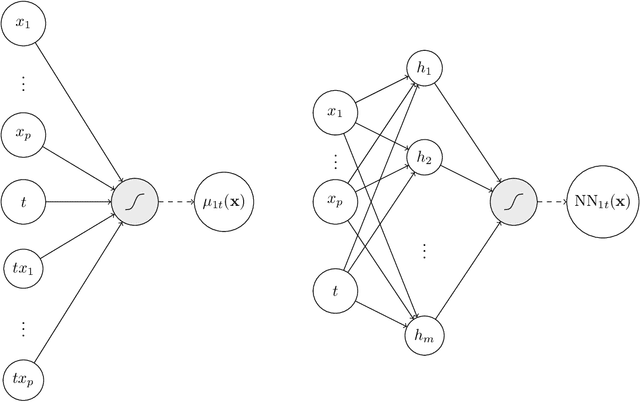
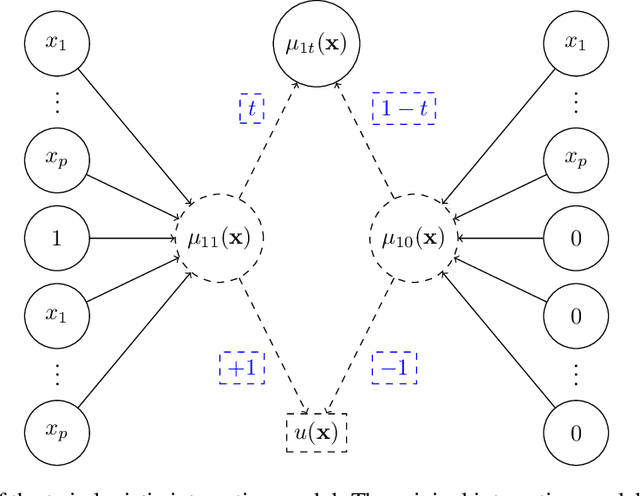
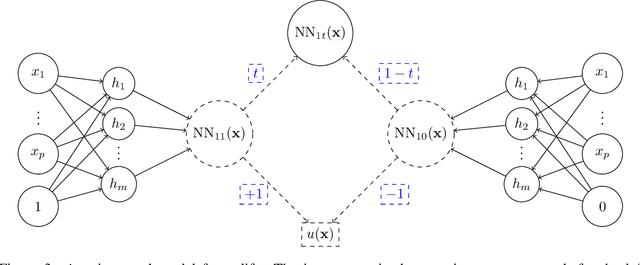
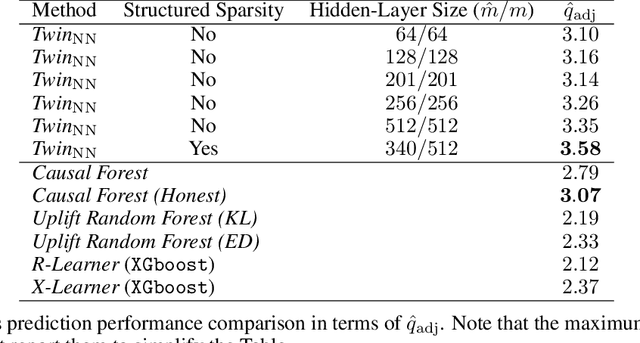
Uplift is a particular case of conditional treatment effect modeling. Such models deal with cause-and-effect inference for a specific factor, such as a marketing intervention or a medical treatment. In practice, these models are built on individual data from randomized clinical trials where the goal is to partition the participants into heterogeneous groups depending on the uplift. Most existing approaches are adaptations of random forests for the uplift case. Several split criteria have been proposed in the literature, all relying on maximizing heterogeneity. However, in practice, these approaches are prone to overfitting. In this work, we bring a new vision to uplift modeling. We propose a new loss function defined by leveraging a connection with the Bayesian interpretation of the relative risk. Our solution is developed for a specific twin neural network architecture allowing to jointly optimize the marginal probabilities of success for treated and control individuals. We show that this model is a generalization of the uplift logistic interaction model. We modify the stochastic gradient descent algorithm to allow for structured sparse solutions. This helps training our uplift models to a great extent. We show our proposed method is competitive with the state-of-the-art in simulation setting and on real data from large scale randomized experiments.
Qini-based Uplift Regression
Nov 28, 2019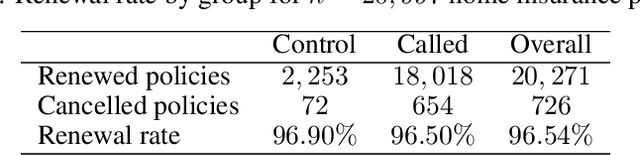
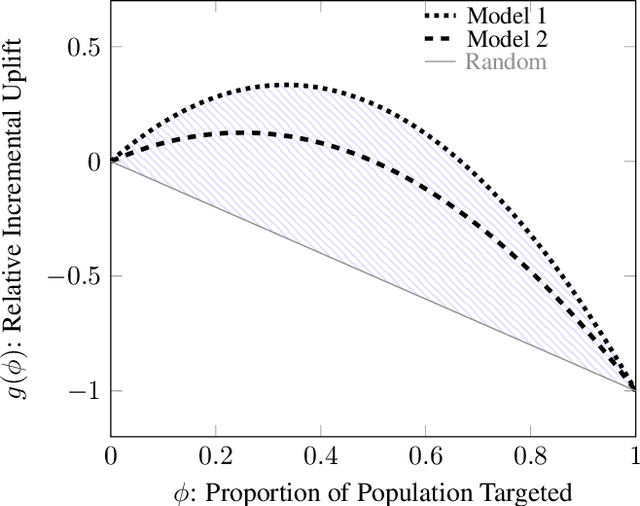
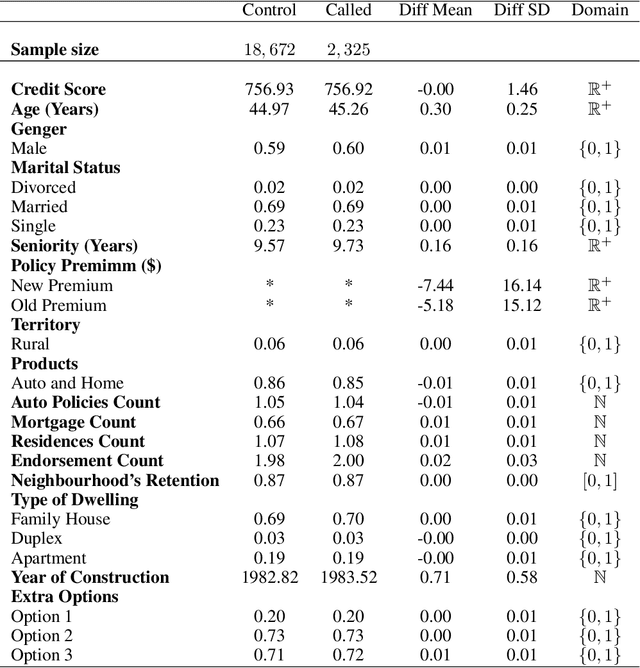
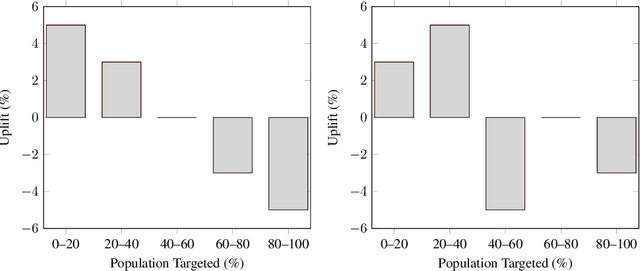
Uplift models provide a solution to the problem of isolating the marketing effect of a campaign. For customer churn reduction, uplift models are used to identify the customers who are likely to respond positively to a retention activity only if targeted, and to avoid wasting resources on customers that are very likely to switch to another company. We introduce a Qini-based uplift regression model to analyze a large insurance company's retention marketing campaign. Our approach is based on logistic regression models. We show that a Qini-optimized uplift model acts as a regularizing factor for uplift, much as a penalized likelihood model does for regression. This results in interpretable parsimonious models with few relevant explanatory variables. Our results show that performing Qini-based variable selection significantly improves the uplift models performance.
How Does Batch Normalization Help Binary Training?
Oct 10, 2019

Binary Neural Networks (BNNs) are difficult to train, and suffer from drop of accuracy. It appears in practice that BNNs fail to train in the absence of Batch Normalization (BatchNorm) layer. We find the main role of BatchNorm is to avoid exploding gradients in the case of BNNs. This finding suggests that the common initialization methods developed for full-precision networks are irrelevant to BNNs. We build a theoretical study on the role of BatchNorm in binary training, backed up by numerical experiments.
Active Learning for High-Dimensional Binary Features
Feb 05, 2019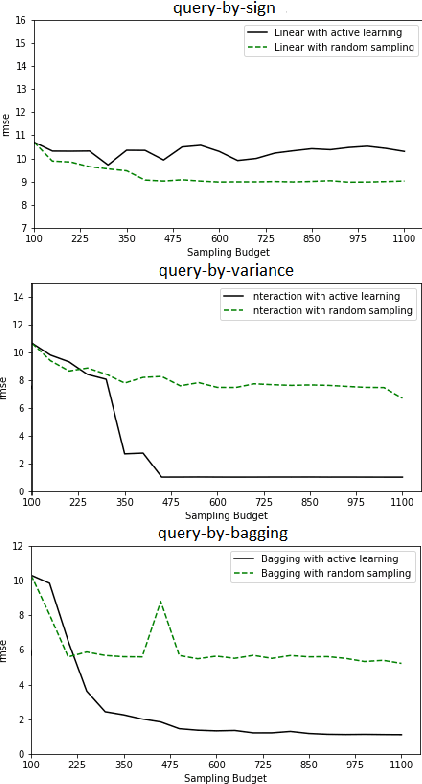
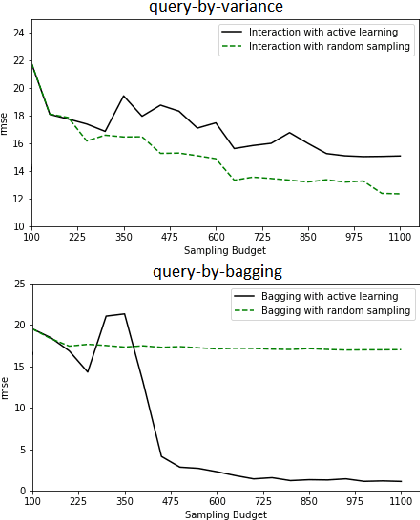
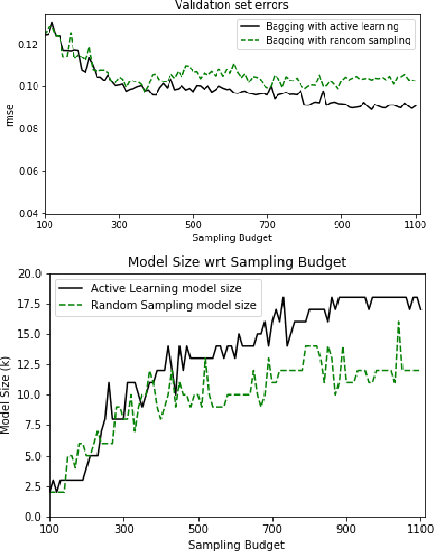
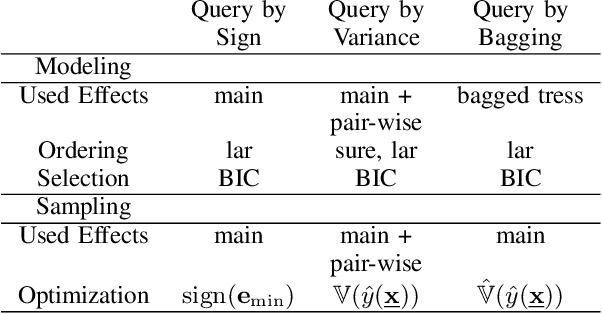
Erbium-doped fiber amplifier (EDFA) is an optical amplifier/repeater device used to boost the intensity of optical signals being carried through a fiber optic communication system. A highly accurate EDFA model is important because of its crucial role in optical network management and optimization. The input channels of an EDFA device are treated as either on or off, hence the input features are binary. Labeled training data is very expensive to collect for EDFA devices, therefore we devise an active learning strategy suitable for binary variables to overcome this issue. We propose to take advantage of sparse linear models to simplify the predictive model. This approach simultaneously improves prediction and accelerates active learning query generation. We show the performance of our proposed active learning strategies on simulated data and real EDFA data.
Foothill: A Quasiconvex Regularization Function
Jan 18, 2019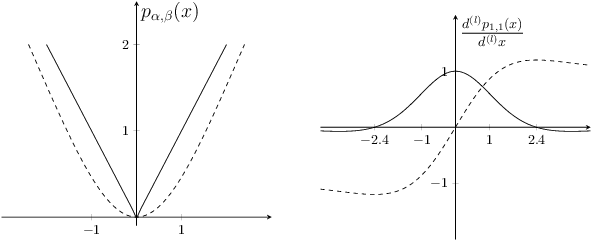

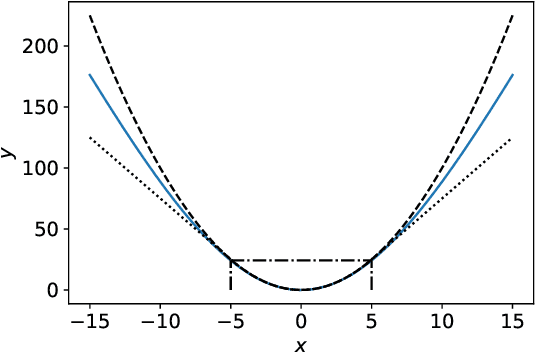
Deep neural networks (DNNs) have demonstrated success for many supervised learning tasks, ranging from voice recognition, object detection, to image classification. However, their increasing complexity yields poor generalization error. Adding noise to the input data or using a concrete regularization function helps to improve generalization. Here we introduce foothill function, an infinitely differentiable quasiconvex function. This regularizer is flexible enough to deform towards $L_1$ and $L_2$ penalties. Foothill can be used as a loss, as a regularizer, or as a binary quantizer.
BNN+: Improved Binary Network Training
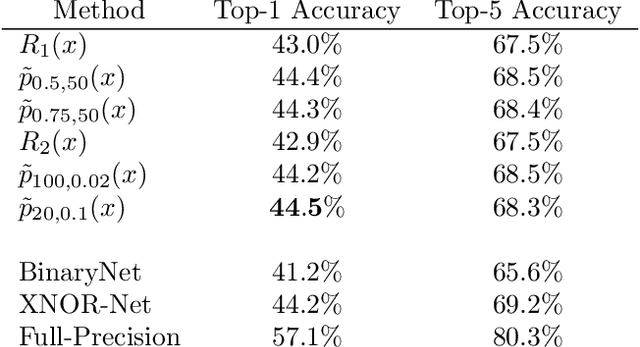
Dec 31, 2018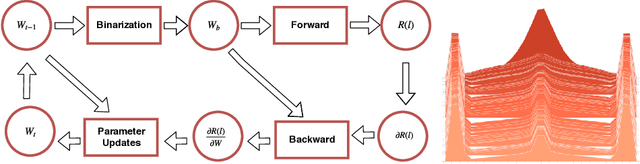
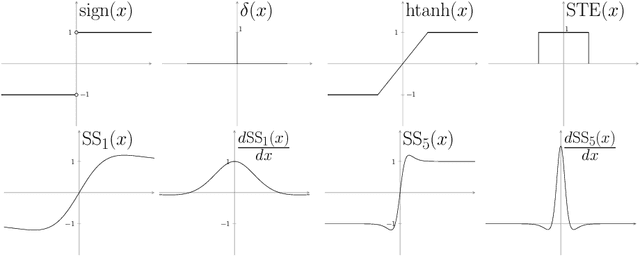
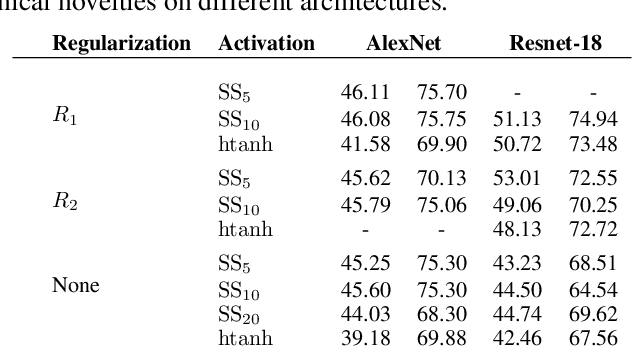
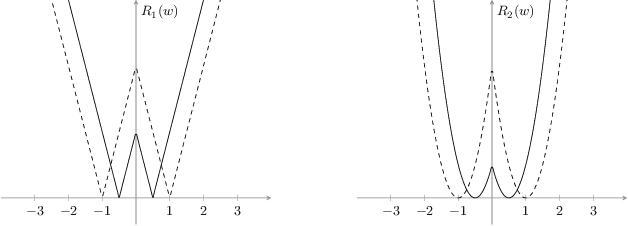
Deep neural networks (DNN) are widely used in many applications. However, their deployment on edge devices has been difficult because they are resource hungry. Binary neural networks (BNN) help to alleviate the prohibitive resource requirements of DNN, where both activations and weights are limited to $1$-bit. We propose an improved binary training method (BNN+), by introducing a regularization function that encourages training weights around binary values. In addition to this, to enhance model performance we add trainable scaling factors to our regularization functions. Furthermore, we use an improved approximation of the derivative of the sign activation function in the backward computation. These additions are based on linear operations that are easily implementable into the binary training framework. We show experimental results on CIFAR-10 obtaining an accuracy of $86.7\%$, on AlexNet and $91.3\%$ with VGG network. On ImageNet, our method also outperforms the traditional BNN method and XNOR-net, using AlexNet by a margin of $4\%$ and $2\%$ top-$1$ accuracy respectively.