 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Twin Neural Model for Uplift
May 11, 2021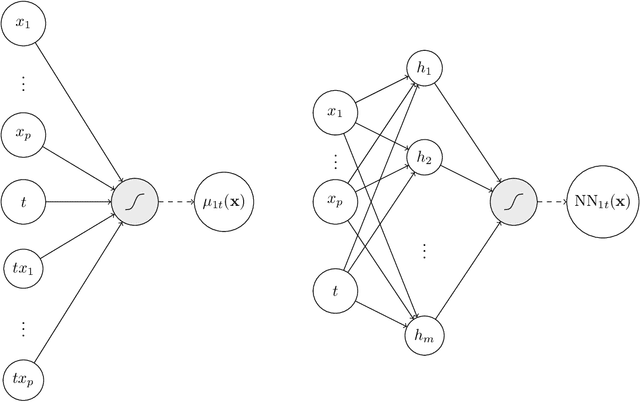
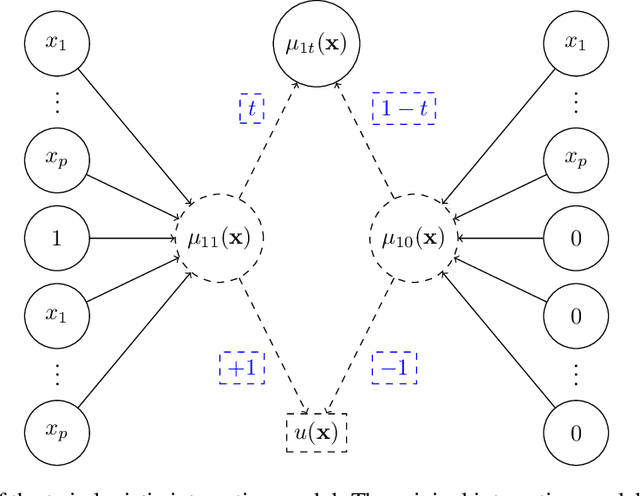
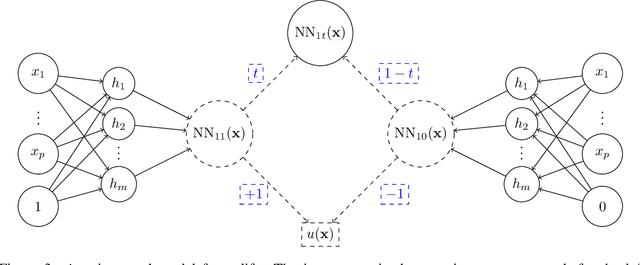
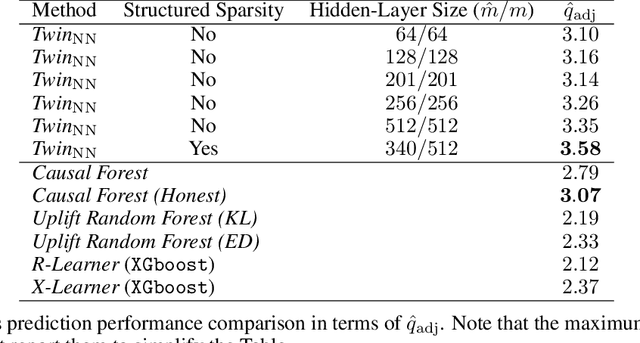
Uplift is a particular case of conditional treatment effect modeling. Such models deal with cause-and-effect inference for a specific factor, such as a marketing intervention or a medical treatment. In practice, these models are built on individual data from randomized clinical trials where the goal is to partition the participants into heterogeneous groups depending on the uplift. Most existing approaches are adaptations of random forests for the uplift case. Several split criteria have been proposed in the literature, all relying on maximizing heterogeneity. However, in practice, these approaches are prone to overfitting. In this work, we bring a new vision to uplift modeling. We propose a new loss function defined by leveraging a connection with the Bayesian interpretation of the relative risk. Our solution is developed for a specific twin neural network architecture allowing to jointly optimize the marginal probabilities of success for treated and control individuals. We show that this model is a generalization of the uplift logistic interaction model. We modify the stochastic gradient descent algorithm to allow for structured sparse solutions. This helps training our uplift models to a great extent. We show our proposed method is competitive with the state-of-the-art in simulation setting and on real data from large scale randomized experiments.
Determinantal consensus clustering
Feb 07, 2021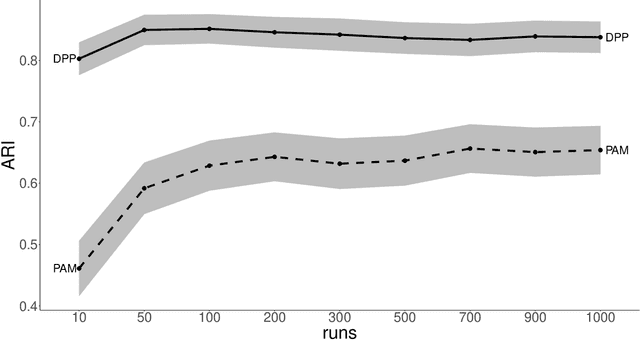
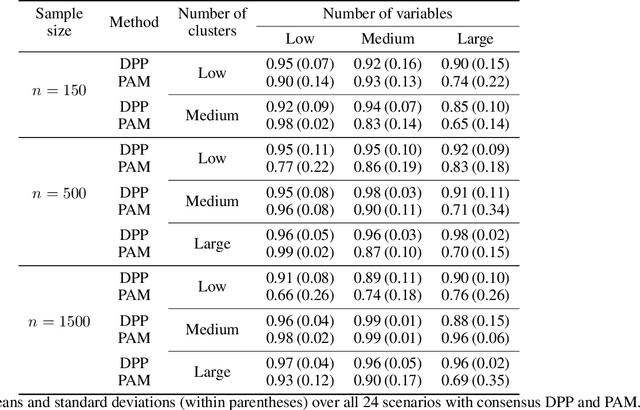
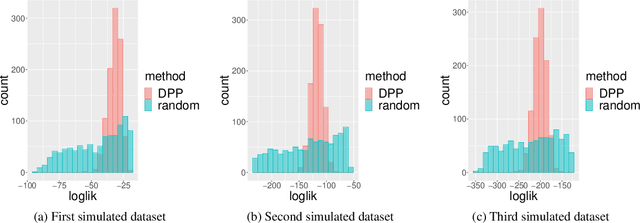
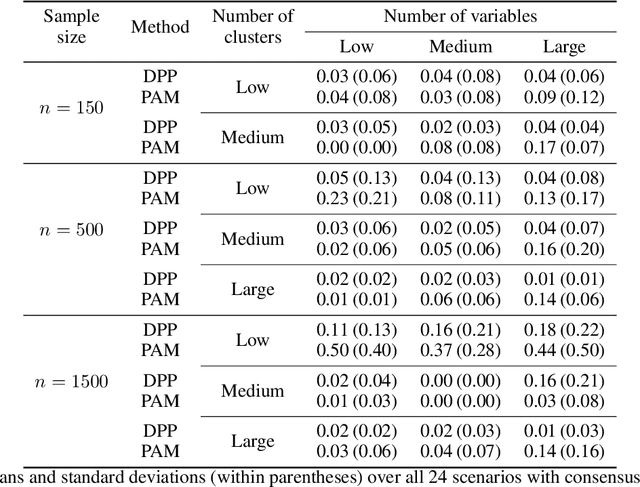
Random restart of a given algorithm produces many partitions to yield a consensus clustering. Ensemble methods such as consensus clustering have been recognized as more robust approaches for data clustering than single clustering algorithms. We propose the use of determinantal point processes or DPP for the random restart of clustering algorithms based on initial sets of center points, such as k-medoids or k-means. The relation between DPP and kernel-based methods makes DPPs suitable to describe and quantify similarity between objects. DPPs favor diversity of the center points within subsets. So, subsets with more similar points have less chances of being generated than subsets with very distinct points. The current and most popular sampling technique is sampling center points uniformly at random. We show through extensive simulations that, contrary to DPP, this technique fails both to ensure diversity, and to obtain a good coverage of all data facets. These two properties of DPP are key to make DPPs achieve good performance with small ensembles. Simulations with artificial datasets and applications to real datasets show that determinantal consensus clustering outperform classical algorithms such as k-medoids and k-means consensus clusterings which are based on uniform random sampling of center points.
Tensor train decompositions on recurrent networks
Jun 09, 2020


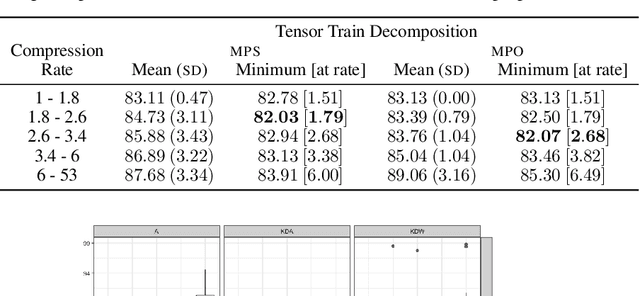
Recurrent neural networks (RNN) such as long-short-term memory (LSTM) networks are essential in a multitude of daily live tasks such as speech, language, video, and multimodal learning. The shift from cloud to edge computation intensifies the need to contain the growth of RNN parameters. Current research on RNN shows that despite the performance obtained on convolutional neural networks (CNN), keeping a good performance in compressed RNNs is still a challenge. Most of the literature on compression focuses on CNNs using matrix product (MPO) operator tensor trains. However, matrix product state (MPS) tensor trains have more attractive features than MPOs, in terms of storage reduction and computing time at inference. We show that MPS tensor trains should be at the forefront of LSTM network compression through a theoretical analysis and practical experiments on NLP task.
Qini-based Uplift Regression
Nov 28, 2019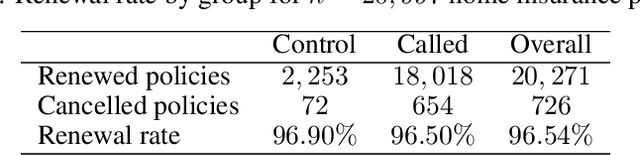
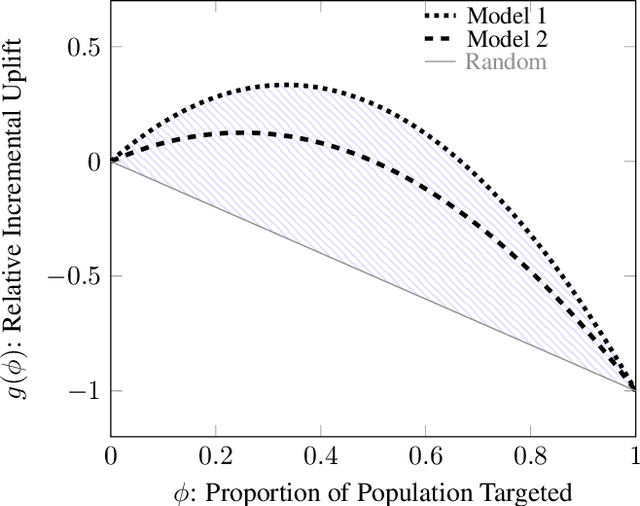
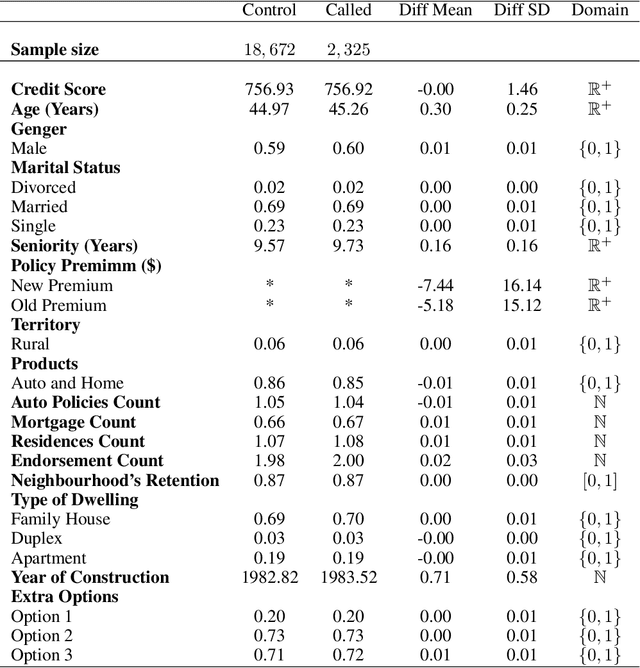
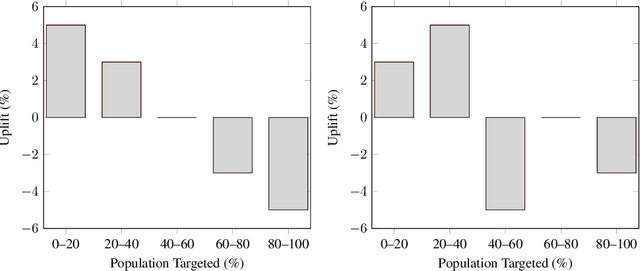
Uplift models provide a solution to the problem of isolating the marketing effect of a campaign. For customer churn reduction, uplift models are used to identify the customers who are likely to respond positively to a retention activity only if targeted, and to avoid wasting resources on customers that are very likely to switch to another company. We introduce a Qini-based uplift regression model to analyze a large insurance company's retention marketing campaign. Our approach is based on logistic regression models. We show that a Qini-optimized uplift model acts as a regularizing factor for uplift, much as a penalized likelihood model does for regression. This results in interpretable parsimonious models with few relevant explanatory variables. Our results show that performing Qini-based variable selection significantly improves the uplift models performance.
Fast spatial inference in the homogeneous Ising model
Feb 01, 2018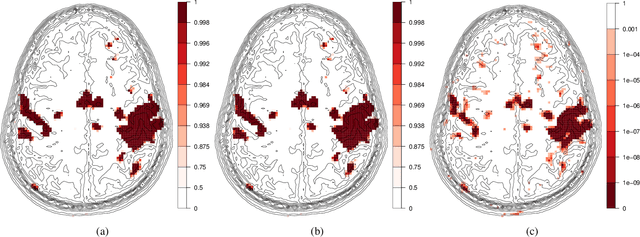
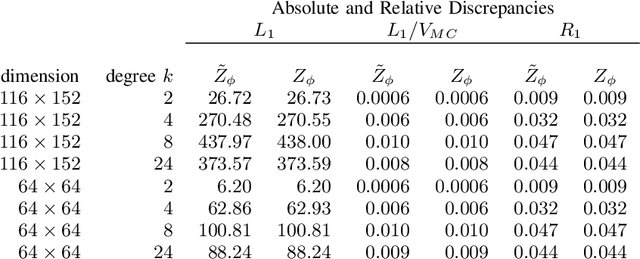
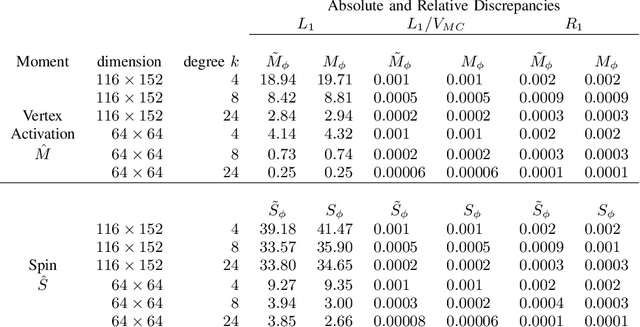
The Ising model is important in statistical modeling and inference in many applications, however its normalizing constant, mean number of active vertices and mean spin interaction are intractable. We provide accurate approximations that make it possible to calculate these quantities numerically. Simulation studies indicate good performance when compared to Markov Chain Monte Carlo methods and at a tiny fraction of the time. The methodology is also used to perform Bayesian inference in a functional Magnetic Resonance Imaging activation detection experiment.