 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilled ChatGPT Topic & Sentiment Modeling with Applications in Finance
Mar 04, 2024In this study, ChatGPT is utilized to create streamlined models that generate easily interpretable features. These features are then used to evaluate financial outcomes from earnings calls. We detail a training approach that merges knowledge distillation and transfer learning, resulting in lightweight topic and sentiment classification models without significant loss in accuracy. These models are assessed through a dataset annotated by experts. The paper also delves into two practical case studies, highlighting how the generated features can be effectively utilized in quantitative investing scenarios.
A Twin Neural Model for Uplift
May 11, 2021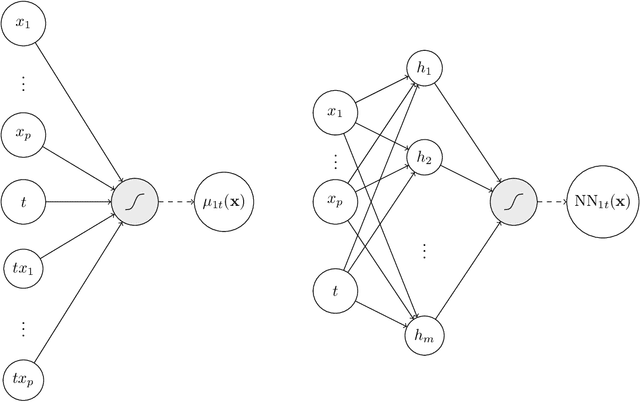
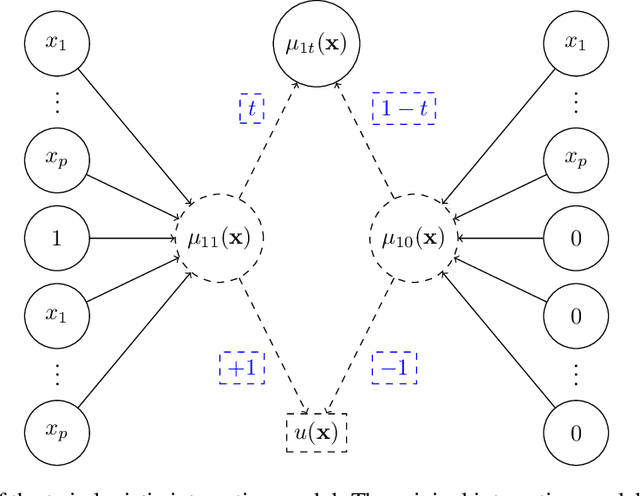
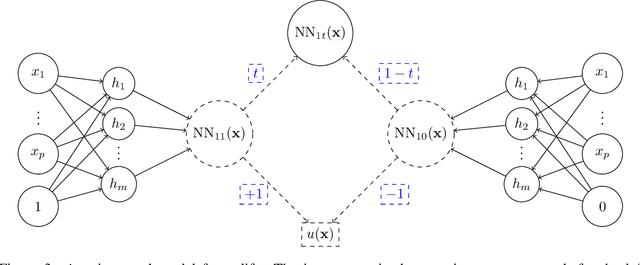
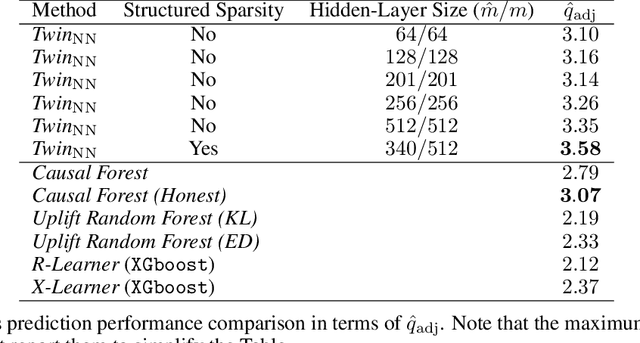
Uplift is a particular case of conditional treatment effect modeling. Such models deal with cause-and-effect inference for a specific factor, such as a marketing intervention or a medical treatment. In practice, these models are built on individual data from randomized clinical trials where the goal is to partition the participants into heterogeneous groups depending on the uplift. Most existing approaches are adaptations of random forests for the uplift case. Several split criteria have been proposed in the literature, all relying on maximizing heterogeneity. However, in practice, these approaches are prone to overfitting. In this work, we bring a new vision to uplift modeling. We propose a new loss function defined by leveraging a connection with the Bayesian interpretation of the relative risk. Our solution is developed for a specific twin neural network architecture allowing to jointly optimize the marginal probabilities of success for treated and control individuals. We show that this model is a generalization of the uplift logistic interaction model. We modify the stochastic gradient descent algorithm to allow for structured sparse solutions. This helps training our uplift models to a great extent. We show our proposed method is competitive with the state-of-the-art in simulation setting and on real data from large scale randomized experiments.
Qini-based Uplift Regression
Nov 28, 2019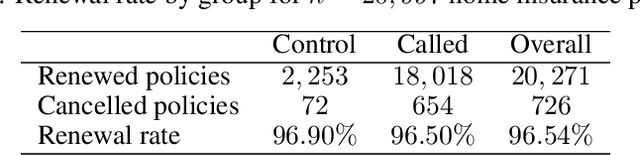
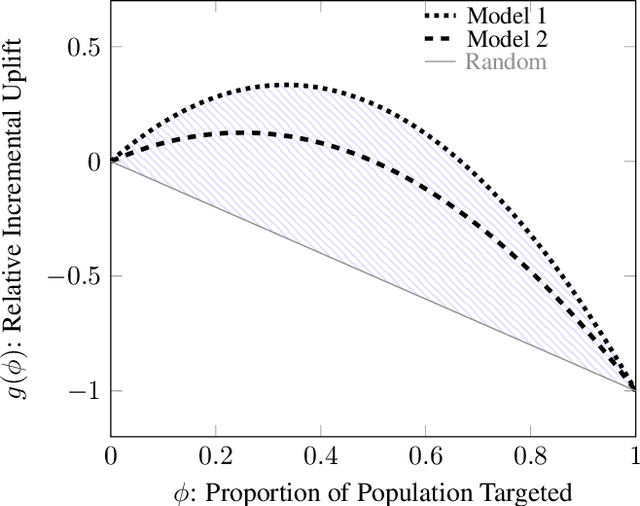
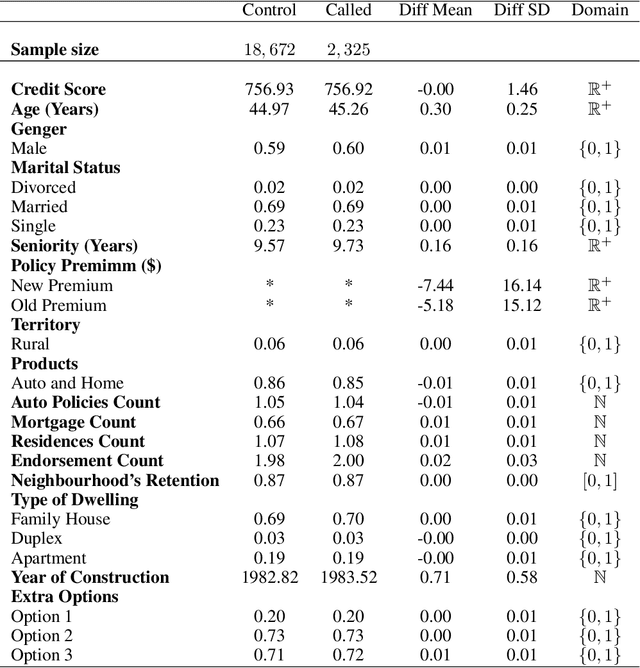
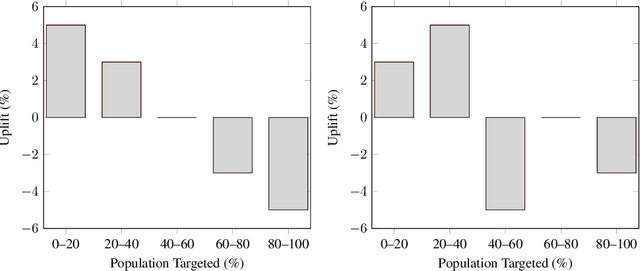
Uplift models provide a solution to the problem of isolating the marketing effect of a campaign. For customer churn reduction, uplift models are used to identify the customers who are likely to respond positively to a retention activity only if targeted, and to avoid wasting resources on customers that are very likely to switch to another company. We introduce a Qini-based uplift regression model to analyze a large insurance company's retention marketing campaign. Our approach is based on logistic regression models. We show that a Qini-optimized uplift model acts as a regularizing factor for uplift, much as a penalized likelihood model does for regression. This results in interpretable parsimonious models with few relevant explanatory variables. Our results show that performing Qini-based variable selection significantly improves the uplift models performance.