 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Retrieval Component in LLM-Based Question Answering Systems
Jun 10, 2024
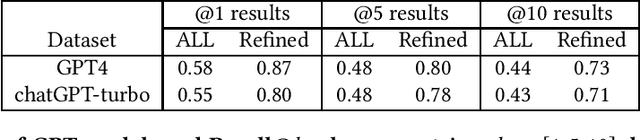
Question answering systems (QA) utilizing Large Language Models (LLMs) heavily depend on the retrieval component to provide them with domain-specific information and reduce the risk of generating inaccurate responses or hallucinations. Although the evaluation of retrievers dates back to the early research in Information Retrieval, assessing their performance within LLM-based chatbots remains a challenge. This study proposes a straightforward baseline for evaluating retrievers in Retrieval-Augmented Generation (RAG)-based chatbots. Our findings demonstrate that this evaluation framework provides a better image of how the retriever performs and is more aligned with the overall performance of the QA system. Although conventional metrics such as precision, recall, and F1 score may not fully capture LLMs' capabilities - as they can yield accurate responses despite imperfect retrievers - our method considers LLMs' strengths to ignore irrelevant contexts, as well as potential errors and hallucinations in their responses.
Handwritten and Printed Text Segmentation: A Signature Case Study
Jul 15, 2023While analyzing scanned documents, handwritten text can overlay printed text. This causes difficulties during the optical character recognition (OCR) and digitization process of documents, and subsequently, hurts downstream NLP tasks. Prior research either focuses only on the binary classification of handwritten text, or performs a three-class segmentation of the document, i.e., recognition of handwritten, printed, and background pixels. This results in the assignment of the handwritten and printed overlapping pixels to only one of the classes, and thus, they are not accounted for in the other class. Thus, in this research, we develop novel approaches for addressing the challenges of handwritten and printed text segmentation with the goal of recovering text in different classes in whole, especially improving the segmentation performance on the overlapping parts. As such, to facilitate with this task, we introduce a new dataset, SignaTR6K, collected from real legal documents, as well as a new model architecture for handwritten and printed text segmentation task. Our best configuration outperforms the prior work on two different datasets by 17.9% and 7.3% on IoU scores.
Active Learning for High-Dimensional Binary Features
Feb 05, 2019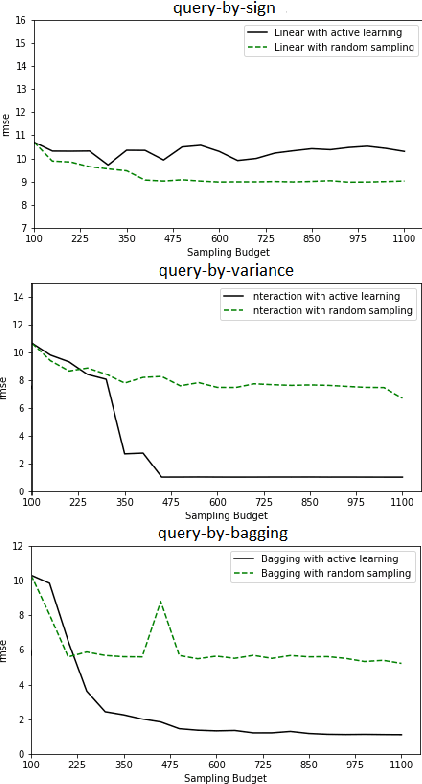
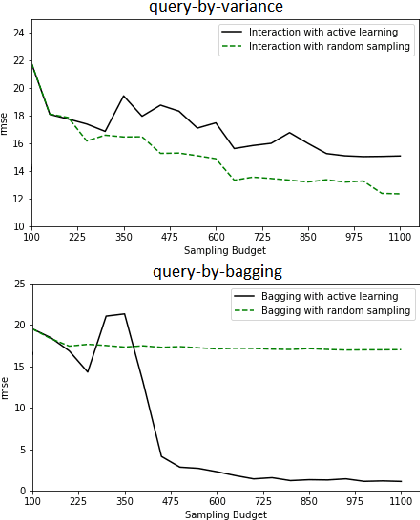
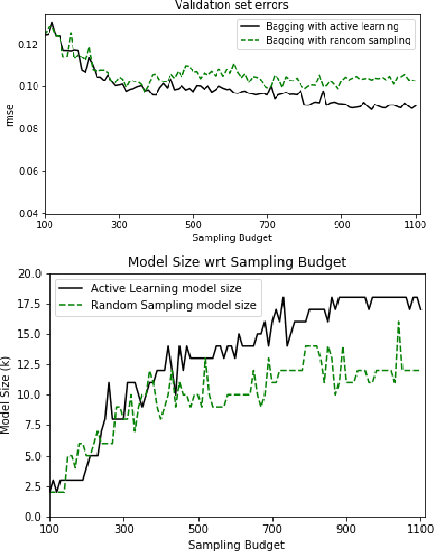
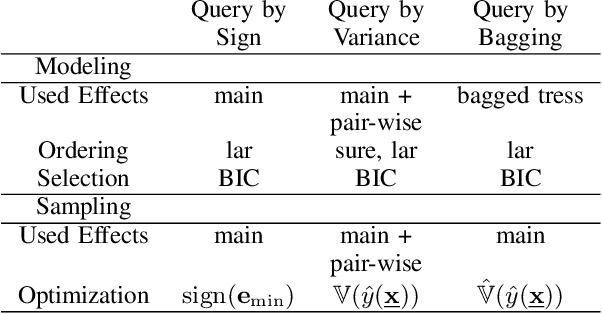
Erbium-doped fiber amplifier (EDFA) is an optical amplifier/repeater device used to boost the intensity of optical signals being carried through a fiber optic communication system. A highly accurate EDFA model is important because of its crucial role in optical network management and optimization. The input channels of an EDFA device are treated as either on or off, hence the input features are binary. Labeled training data is very expensive to collect for EDFA devices, therefore we devise an active learning strategy suitable for binary variables to overcome this issue. We propose to take advantage of sparse linear models to simplify the predictive model. This approach simultaneously improves prediction and accelerates active learning query generation. We show the performance of our proposed active learning strategies on simulated data and real EDFA data.