 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Based Robust Product Classification in Commerce and Compliance
Aug 11, 2024Product classification is a crucial task in international trade, as compliance regulations are verified and taxes and duties are applied based on product categories. Manual classification of products is time-consuming and error-prone, and the sheer volume of products imported and exported renders the manual process infeasible. Consequently, e-commerce platforms and enterprises involved in international trade have turned to automatic product classification using machine learning. However, current approaches do not consider the real-world challenges associated with product classification, such as very abbreviated and incomplete product descriptions. In addition, recent advancements in generative Large Language Models (LLMs) and their reasoning capabilities are mainly untapped in product classification and e-commerce. In this research, we explore the real-life challenges of industrial classification and we propose data perturbations that allow for realistic data simulation. Furthermore, we employ LLM-based product classification to improve the robustness of the prediction in presence of incomplete data. Our research shows that LLMs with in-context learning outperform the supervised approaches in the clean-data scenario. Additionally, we illustrate that LLMs are significantly more robust than the supervised approaches when data attacks are present.
Reinforcement Learning Problem Solving with Large Language Models
Apr 29, 2024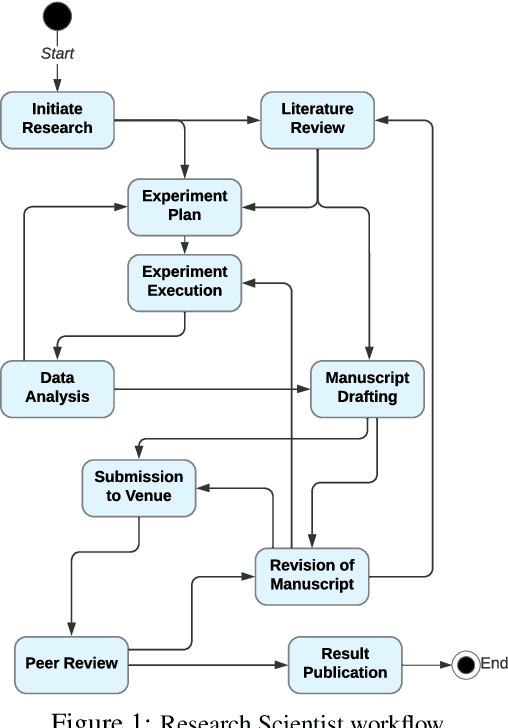
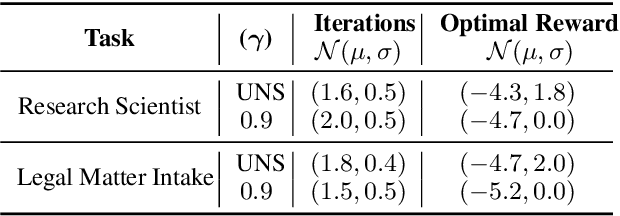
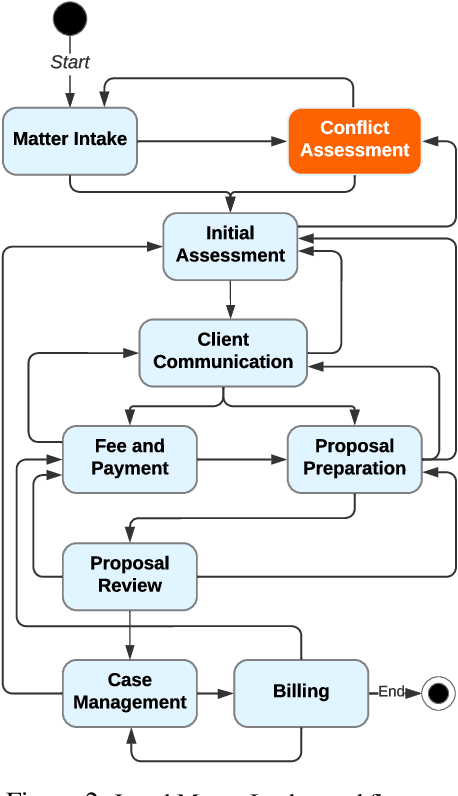
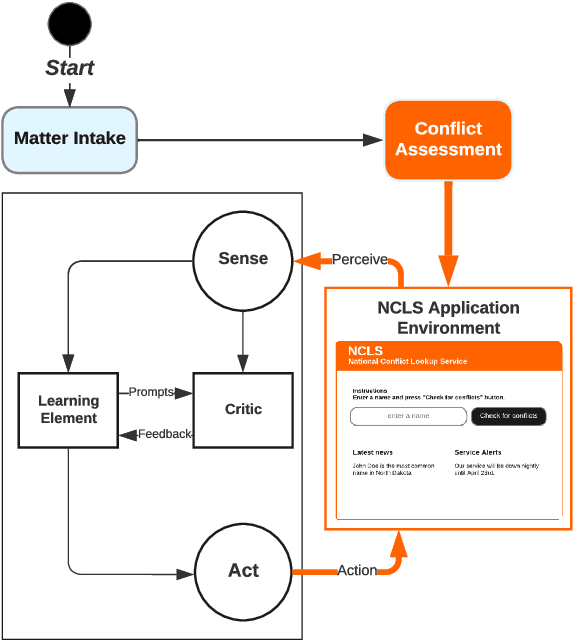
Large Language Models (LLMs) encapsulate an extensive amount of world knowledge, and this has enabled their application in various domains to improve the performance of a variety of Natural Language Processing (NLP) tasks. This has also facilitated a more accessible paradigm of conversation-based interactions between humans and AI systems to solve intended problems. However, one interesting avenue that shows untapped potential is the use of LLMs as Reinforcement Learning (RL) agents to enable conversational RL problem solving. Therefore, in this study, we explore the concept of formulating Markov Decision Process-based RL problems as LLM prompting tasks. We demonstrate how LLMs can be iteratively prompted to learn and optimize policies for specific RL tasks. In addition, we leverage the introduced prompting technique for episode simulation and Q-Learning, facilitated by LLMs. We then show the practicality of our approach through two detailed case studies for "Research Scientist" and "Legal Matter Intake" workflows.
Handwritten and Printed Text Segmentation: A Signature Case Study
Jul 15, 2023While analyzing scanned documents, handwritten text can overlay printed text. This causes difficulties during the optical character recognition (OCR) and digitization process of documents, and subsequently, hurts downstream NLP tasks. Prior research either focuses only on the binary classification of handwritten text, or performs a three-class segmentation of the document, i.e., recognition of handwritten, printed, and background pixels. This results in the assignment of the handwritten and printed overlapping pixels to only one of the classes, and thus, they are not accounted for in the other class. Thus, in this research, we develop novel approaches for addressing the challenges of handwritten and printed text segmentation with the goal of recovering text in different classes in whole, especially improving the segmentation performance on the overlapping parts. As such, to facilitate with this task, we introduce a new dataset, SignaTR6K, collected from real legal documents, as well as a new model architecture for handwritten and printed text segmentation task. Our best configuration outperforms the prior work on two different datasets by 17.9% and 7.3% on IoU scores.
Borrowing from Similar Code: A Deep Learning NLP-Based Approach for Log Statement Automation
Dec 02, 2021
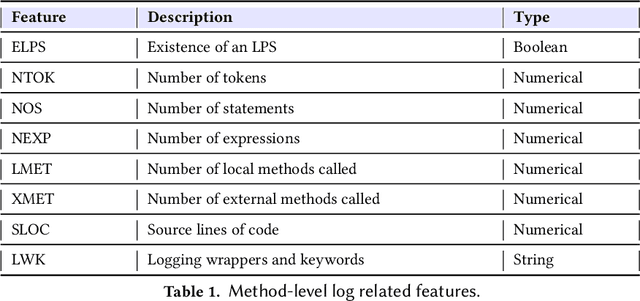
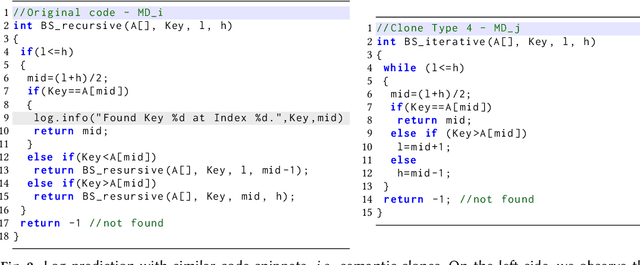
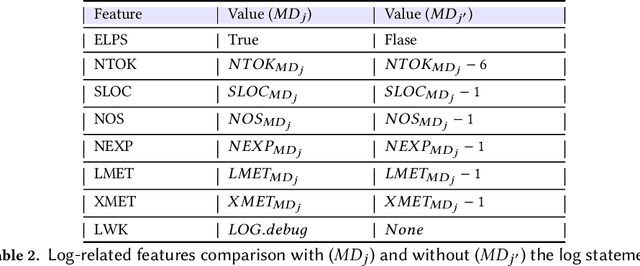
Software developers embed logging statements inside the source code as an imperative duty in modern software development as log files are necessary for tracking down runtime system issues and troubleshooting system management tasks. However, the current logging process is mostly manual, and thus, proper placement and content of logging statements remain as challenges. To overcome these challenges, methods that aim to automate log placement and predict its content, i.e., 'where and what to log', are of high interest. Thus, we focus on predicting the location (i.e., where) and description (i.e., what) for log statements by utilizing source code clones and natural language processing (NLP), as these approaches provide additional context and advantage for log prediction. Specifically, we guide our research with three research questions (RQs): (RQ1) how similar code snippets, i.e., code clones, can be leveraged for log statements prediction? (RQ2) how the approach can be extended to automate log statements' descriptions? and (RQ3) how effective the proposed methods are for log location and description prediction? To pursue our RQs, we perform an experimental study on seven open-source Java projects. We introduce an updated and improved log-aware code-clone detection method to predict the location of logging statements (RQ1). Then, we incorporate natural language processing (NLP) and deep learning methods to automate the log statements' description prediction (RQ2). Our analysis shows that our hybrid NLP and code-clone detection approach (NLP CC'd) outperforms conventional clone detectors in finding log statement locations on average by 15.60% and achieves 40.86% higher performance on BLEU and ROUGE scores for predicting the description of logging statements when compared to prior research (RQ3).
A Comprehensive Survey of Logging in Software: From Logging Statements Automation to Log Mining and Analysis
Oct 24, 2021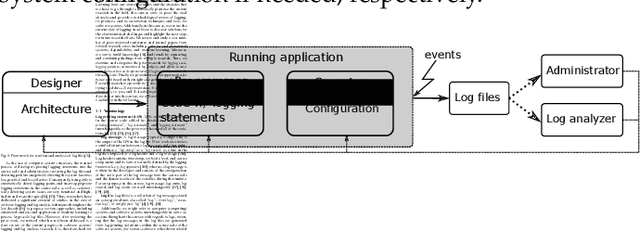

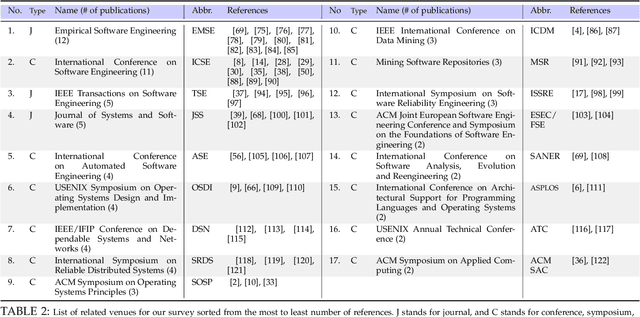

Logs are widely used to record runtime information of software systems, such as the timestamp and the importance of an event, the unique ID of the source of the log, and a part of the state of a task's execution. The rich information of logs enables system developers (and operators) to monitor the runtime behaviors of their systems and further track down system problems and perform analysis on log data in production settings. However, the prior research on utilizing logs is scattered and that limits the ability of new researchers in this field to quickly get to the speed and hampers currently active researchers to advance this field further. Therefore, this paper surveys and provides a systematic literature review of the contemporary logging practices and log statements' mining and monitoring techniques and their applications such as in system failure detection and diagnosis. We study a large number of conference and journal papers that appeared on top-level peer-reviewed venues. Additionally, we draw high-level trends of ongoing research and categorize publications into subdivisions. In the end, and based on our holistic observations during this survey, we provide a set of challenges and opportunities that will lead the researchers in academia and industry in moving the field forward.
Leveraging Code Clones and Natural Language Processing for Log Statement Prediction
Sep 08, 2021
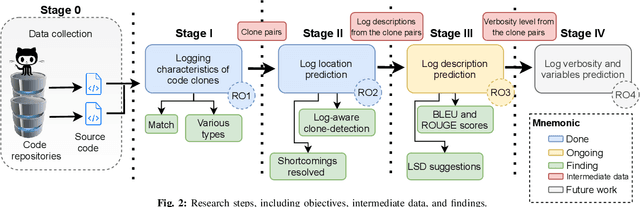
Software developers embed logging statements inside the source code as an imperative duty in modern software development as log files are necessary for tracking down runtime system issues and troubleshooting system management tasks. Prior research has emphasized the importance of logging statements in the operation and debugging of software systems. However, the current logging process is mostly manual and ad hoc, and thus, proper placement and content of logging statements remain as challenges. To overcome these challenges, methods that aim to automate log placement and log content, i.e., 'where, what, and how to log', are of high interest. Thus, we propose to accomplish the goal of this research, that is "to predict the log statements by utilizing source code clones and natural language processing (NLP)", as these approaches provide additional context and advantage for log prediction. We pursue the following four research objectives: (RO1) investigate whether source code clones can be leveraged for log statement location prediction, (RO2) propose a clone-based approach for log statement prediction, (RO3) predict log statement's description with code-clone and NLP models, and (RO4) examine approaches to automatically predict additional details of the log statement, such as its verbosity level and variables. For this purpose, we perform an experimental analysis on seven open-source java projects, extract their method-level code clones, investigate their attributes, and utilize them for log location and description prediction. Our work demonstrates the effectiveness of log-aware clone detection for automated log location and description prediction and outperforms the prior work.