 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBorrowing from Similar Code: A Deep Learning NLP-Based Approach for Log Statement Automation
Dec 02, 2021
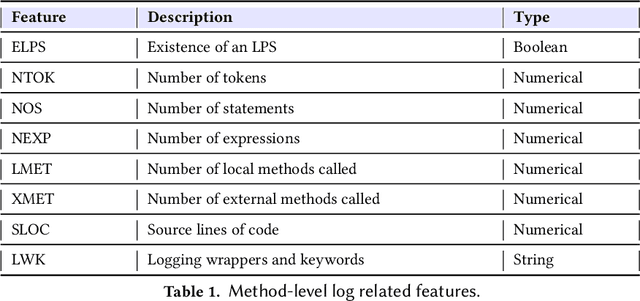
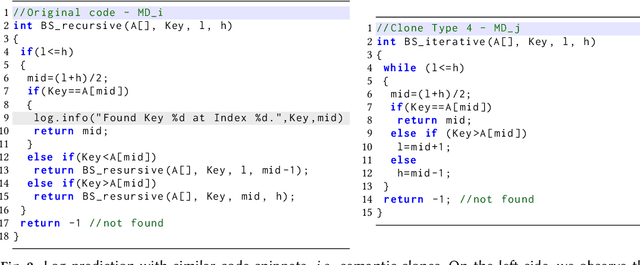
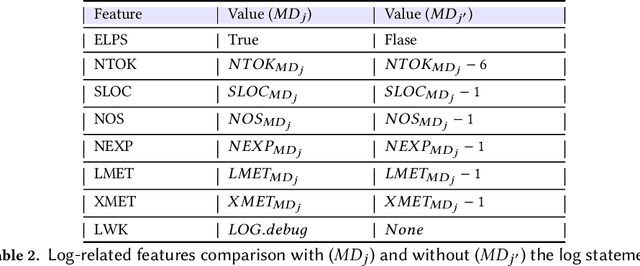
Software developers embed logging statements inside the source code as an imperative duty in modern software development as log files are necessary for tracking down runtime system issues and troubleshooting system management tasks. However, the current logging process is mostly manual, and thus, proper placement and content of logging statements remain as challenges. To overcome these challenges, methods that aim to automate log placement and predict its content, i.e., 'where and what to log', are of high interest. Thus, we focus on predicting the location (i.e., where) and description (i.e., what) for log statements by utilizing source code clones and natural language processing (NLP), as these approaches provide additional context and advantage for log prediction. Specifically, we guide our research with three research questions (RQs): (RQ1) how similar code snippets, i.e., code clones, can be leveraged for log statements prediction? (RQ2) how the approach can be extended to automate log statements' descriptions? and (RQ3) how effective the proposed methods are for log location and description prediction? To pursue our RQs, we perform an experimental study on seven open-source Java projects. We introduce an updated and improved log-aware code-clone detection method to predict the location of logging statements (RQ1). Then, we incorporate natural language processing (NLP) and deep learning methods to automate the log statements' description prediction (RQ2). Our analysis shows that our hybrid NLP and code-clone detection approach (NLP CC'd) outperforms conventional clone detectors in finding log statement locations on average by 15.60% and achieves 40.86% higher performance on BLEU and ROUGE scores for predicting the description of logging statements when compared to prior research (RQ3).
A Comprehensive Survey of Logging in Software: From Logging Statements Automation to Log Mining and Analysis
Oct 24, 2021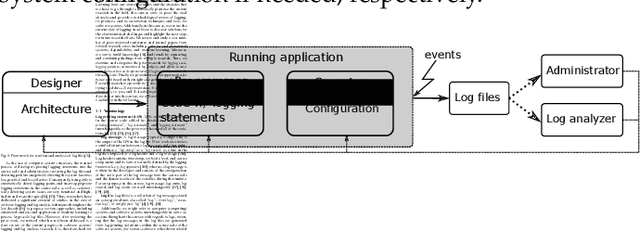

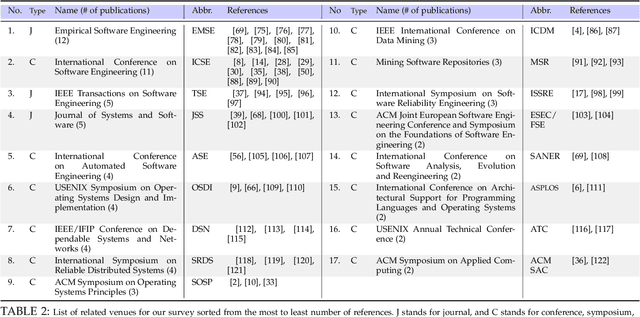

Logs are widely used to record runtime information of software systems, such as the timestamp and the importance of an event, the unique ID of the source of the log, and a part of the state of a task's execution. The rich information of logs enables system developers (and operators) to monitor the runtime behaviors of their systems and further track down system problems and perform analysis on log data in production settings. However, the prior research on utilizing logs is scattered and that limits the ability of new researchers in this field to quickly get to the speed and hampers currently active researchers to advance this field further. Therefore, this paper surveys and provides a systematic literature review of the contemporary logging practices and log statements' mining and monitoring techniques and their applications such as in system failure detection and diagnosis. We study a large number of conference and journal papers that appeared on top-level peer-reviewed venues. Additionally, we draw high-level trends of ongoing research and categorize publications into subdivisions. In the end, and based on our holistic observations during this survey, we provide a set of challenges and opportunities that will lead the researchers in academia and industry in moving the field forward.
Predicting student performance using data from an auto-grading system
Feb 02, 2021



As online auto-grading systems appear, information obtained from those systems can potentially enable researchers to create predictive models to predict student behaviour and performances. In the University of Waterloo, the ECE 150 (Fundamentals of Programming) Instructional Team wants to get an insight into how to allocate the limited teaching resources better to achieve improved educational outcomes. Currently, the Instructional Team allocates tutoring time in a reactive basis. They help students "as-requested". This approach serves those students with the wherewithal to request help; however, many of the students who are struggling do not reach out for assistance. Therefore, we, as the Research Team, want to explore if we can determine students which need help by looking into the data from our auto-grading system, Marmoset. In this paper, we conducted experiments building decision-tree and linear-regression models with various features extracted from the Marmoset auto-grading system, including passing rate, testcase outcomes, number of submissions and submission time intervals (the time interval between the student's first reasonable submission and the deadline). For each feature, we interpreted the result at the confusion matrix level. Specifically for poor-performance students, we show that the linear-regression model using submission time intervals performs the best among all models in terms of Precision and F-Measure. We also show that for students who are misclassified into poor-performance students, they have the lowest actual grades in the linear-regression model among all models. In addition, we show that for the midterm, the submission time interval of the last assignment before the midterm predicts the midterm performance the most. However, for the final exam, the midterm performance contributes the most on the final exam performance.