 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBorrowing from Similar Code: A Deep Learning NLP-Based Approach for Log Statement Automation
Paper and Code
Dec 02, 2021
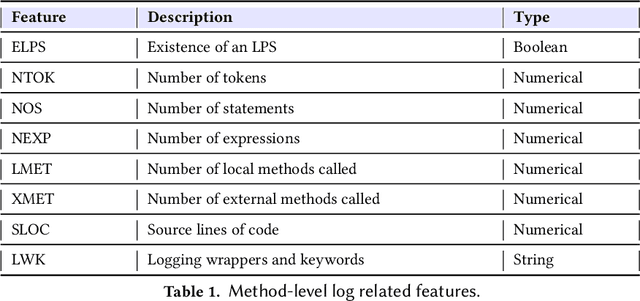
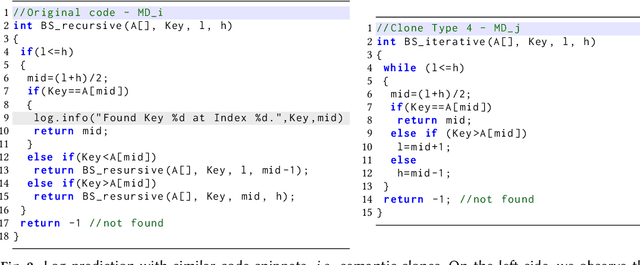
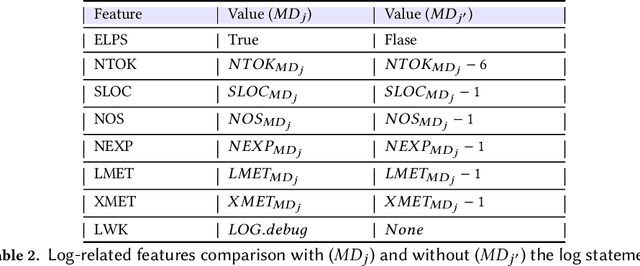
Software developers embed logging statements inside the source code as an imperative duty in modern software development as log files are necessary for tracking down runtime system issues and troubleshooting system management tasks. However, the current logging process is mostly manual, and thus, proper placement and content of logging statements remain as challenges. To overcome these challenges, methods that aim to automate log placement and predict its content, i.e., 'where and what to log', are of high interest. Thus, we focus on predicting the location (i.e., where) and description (i.e., what) for log statements by utilizing source code clones and natural language processing (NLP), as these approaches provide additional context and advantage for log prediction. Specifically, we guide our research with three research questions (RQs): (RQ1) how similar code snippets, i.e., code clones, can be leveraged for log statements prediction? (RQ2) how the approach can be extended to automate log statements' descriptions? and (RQ3) how effective the proposed methods are for log location and description prediction? To pursue our RQs, we perform an experimental study on seven open-source Java projects. We introduce an updated and improved log-aware code-clone detection method to predict the location of logging statements (RQ1). Then, we incorporate natural language processing (NLP) and deep learning methods to automate the log statements' description prediction (RQ2). Our analysis shows that our hybrid NLP and code-clone detection approach (NLP CC'd) outperforms conventional clone detectors in finding log statement locations on average by 15.60% and achieves 40.86% higher performance on BLEU and ROUGE scores for predicting the description of logging statements when compared to prior research (RQ3).