 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Retrieval Component in LLM-Based Question Answering Systems
Paper and Code
Jun 10, 2024
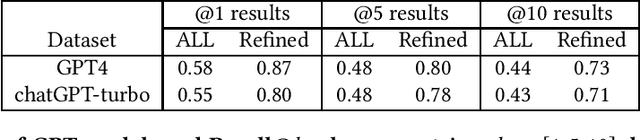
Question answering systems (QA) utilizing Large Language Models (LLMs) heavily depend on the retrieval component to provide them with domain-specific information and reduce the risk of generating inaccurate responses or hallucinations. Although the evaluation of retrievers dates back to the early research in Information Retrieval, assessing their performance within LLM-based chatbots remains a challenge. This study proposes a straightforward baseline for evaluating retrievers in Retrieval-Augmented Generation (RAG)-based chatbots. Our findings demonstrate that this evaluation framework provides a better image of how the retriever performs and is more aligned with the overall performance of the QA system. Although conventional metrics such as precision, recall, and F1 score may not fully capture LLMs' capabilities - as they can yield accurate responses despite imperfect retrievers - our method considers LLMs' strengths to ignore irrelevant contexts, as well as potential errors and hallucinations in their responses.