 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the Retrieval Component in LLM-Based Question Answering Systems
Jun 10, 2024
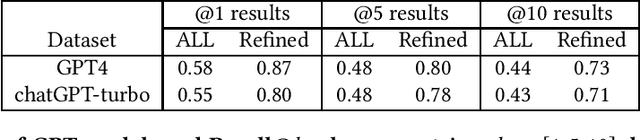
Question answering systems (QA) utilizing Large Language Models (LLMs) heavily depend on the retrieval component to provide them with domain-specific information and reduce the risk of generating inaccurate responses or hallucinations. Although the evaluation of retrievers dates back to the early research in Information Retrieval, assessing their performance within LLM-based chatbots remains a challenge. This study proposes a straightforward baseline for evaluating retrievers in Retrieval-Augmented Generation (RAG)-based chatbots. Our findings demonstrate that this evaluation framework provides a better image of how the retriever performs and is more aligned with the overall performance of the QA system. Although conventional metrics such as precision, recall, and F1 score may not fully capture LLMs' capabilities - as they can yield accurate responses despite imperfect retrievers - our method considers LLMs' strengths to ignore irrelevant contexts, as well as potential errors and hallucinations in their responses.
Improving Neural Machine Translation with Compact Word Embedding Tables
Apr 18, 2021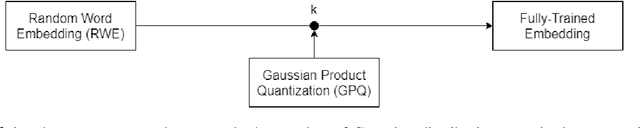
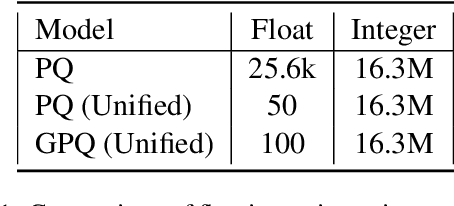

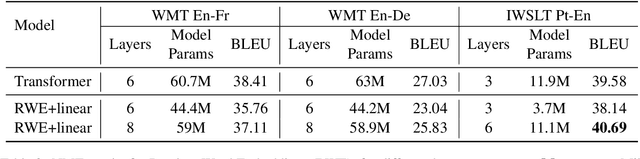
Embedding matrices are key components in neural natural language processing (NLP) models that are responsible to provide numerical representations of input tokens.\footnote{In this paper words and subwords are referred to as \textit{tokens} and the term \textit{embedding} only refers to embeddings of inputs.} In this paper, we analyze the impact and utility of such matrices in the context of neural machine translation (NMT). We show that detracting syntactic and semantic information from word embeddings and running NMT systems with random embeddings is not as damaging as it initially sounds. We also show how incorporating only a limited amount of task-specific knowledge from fully-trained embeddings can boost the performance NMT systems. Our findings demonstrate that in exchange for negligible deterioration in performance, any NMT model can be run with partially random embeddings. Working with such structures means a minimal memory requirement as there is no longer need to store large embedding tables, which is a significant gain in industrial and on-device settings. We evaluated our embeddings in translating {English} into {German} and {French} and achieved a $5.3$x compression rate. Despite having a considerably smaller architecture, our models in some cases are even able to outperform state-of-the-art baselines.
Distilled embedding: non-linear embedding factorization using knowledge distillation
Oct 02, 2019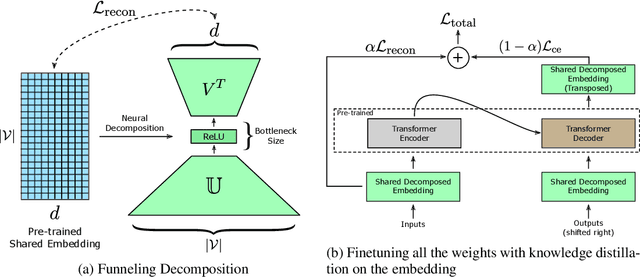
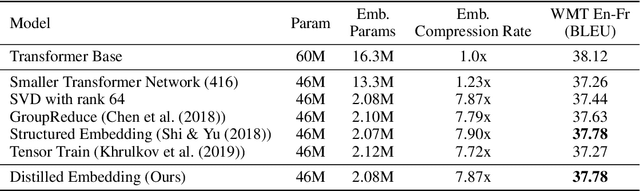
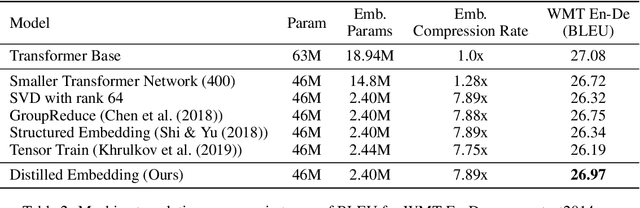
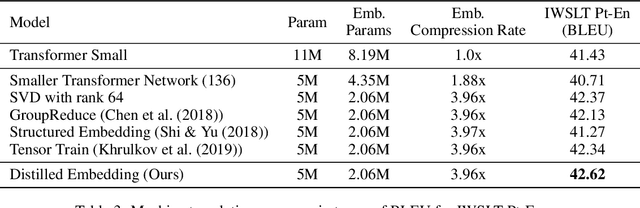
Word-embeddings are a vital component of Natural Language Processing (NLP) systems and have been extensively researched. Better representations of words have come at the cost of huge memory footprints, which has made deploying NLP models on edge-devices challenging due to memory limitations. Compressing embedding matrices without sacrificing model performance is essential for successful commercial edge deployment. In this paper, we propose Distilled Embedding, an (input/output) embedding compression method based on low-rank matrix decomposition with an added non-linearity. First, we initialize the weights of our decomposition by learning to reconstruct the full word-embedding and then fine-tune on the downstream task employing knowledge distillation on the factorized embedding. We conduct extensive experimentation with various compression rates on machine translation, using different data-sets with a shared word-embedding matrix for both embedding and vocabulary projection matrices. We show that the proposed technique outperforms conventional low-rank matrix factorization, and other recently proposed word-embedding matrix compression methods.