 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformer with dual-mode chunked attention for joint online and offline ASR
Jun 22, 2022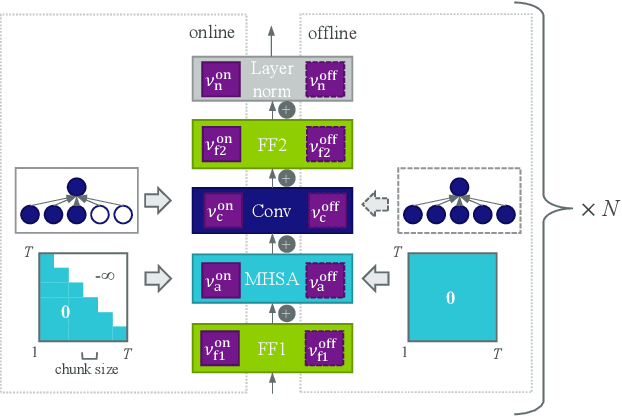
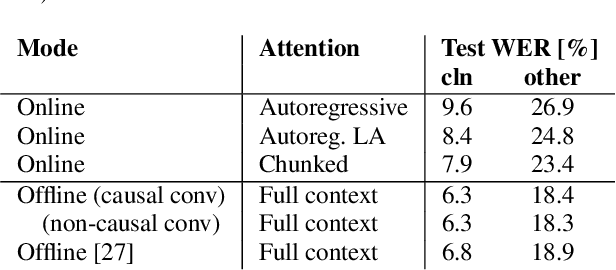
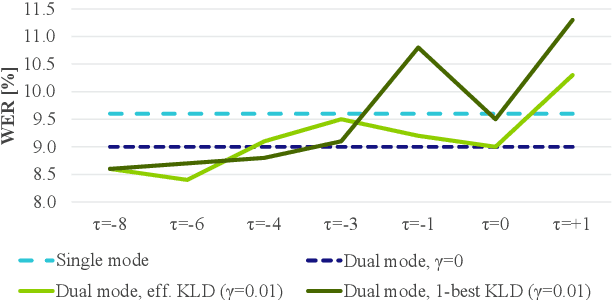
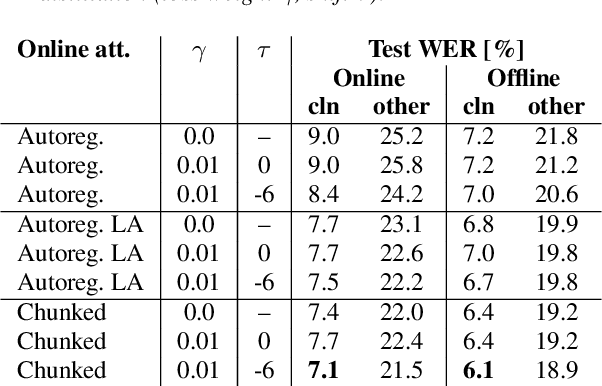
In this paper, we present an in-depth study on online attention mechanisms and distillation techniques for dual-mode (i.e., joint online and offline) ASR using the Conformer Transducer. In the dual-mode Conformer Transducer model, layers can function in online or offline mode while sharing parameters, and in-place knowledge distillation from offline to online mode is applied in training to improve online accuracy. In our study, we first demonstrate accuracy improvements from using chunked attention in the Conformer encoder compared to autoregressive attention with and without lookahead. Furthermore, we explore the efficient KLD and 1-best KLD losses with different shifts between online and offline outputs in the knowledge distillation. Finally, we show that a simplified dual-mode Conformer that only has mode-specific self-attention performs equally well as the one also having mode-specific convolutions and normalization. Our experiments are based on two very different datasets: the Librispeech task and an internal corpus of medical conversations. Results show that the proposed dual-mode system using chunked attention yields 5% and 4% relative WER improvement on the Librispeech and medical tasks, compared to the dual-mode system using autoregressive attention with similar average lookahead.
CILDA: Contrastive Data Augmentation using Intermediate Layer Knowledge Distillation
Apr 15, 2022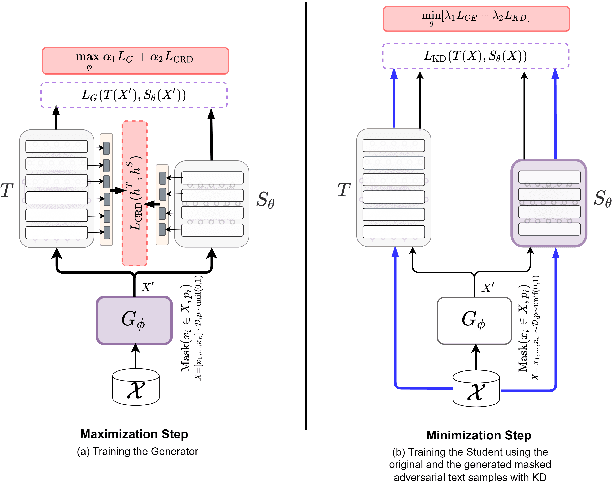
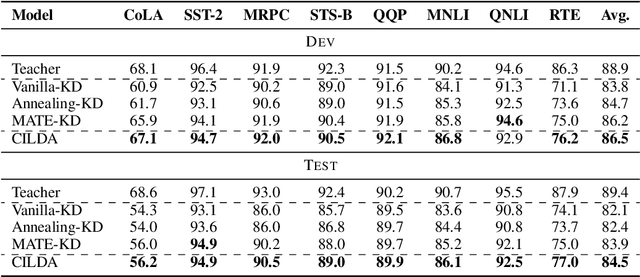
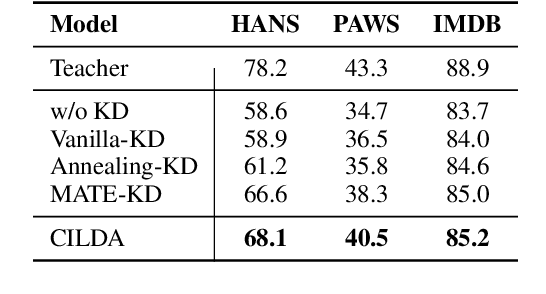
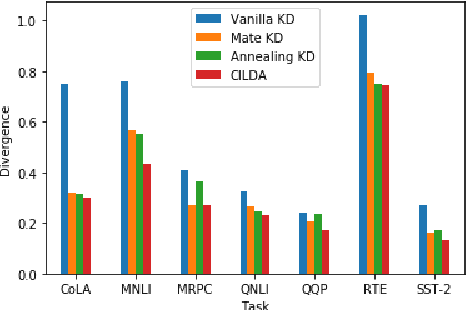
Knowledge distillation (KD) is an efficient framework for compressing large-scale pre-trained language models. Recent years have seen a surge of research aiming to improve KD by leveraging Contrastive Learning, Intermediate Layer Distillation, Data Augmentation, and Adversarial Training. In this work, we propose a learning based data augmentation technique tailored for knowledge distillation, called CILDA. To the best of our knowledge, this is the first time that intermediate layer representations of the main task are used in improving the quality of augmented samples. More precisely, we introduce an augmentation technique for KD based on intermediate layer matching using contrastive loss to improve masked adversarial data augmentation. CILDA outperforms existing state-of-the-art KD approaches on the GLUE benchmark, as well as in an out-of-domain evaluation.
RAIL-KD: RAndom Intermediate Layer Mapping for Knowledge Distillation
Oct 01, 2021
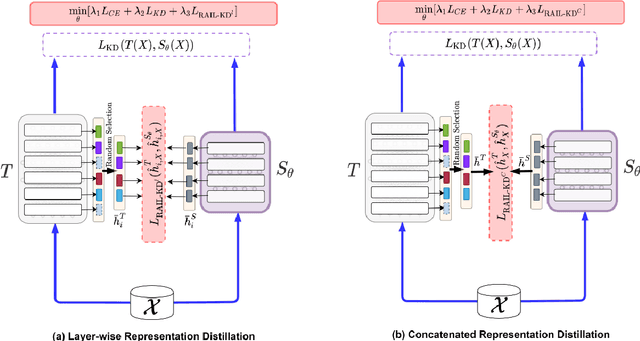
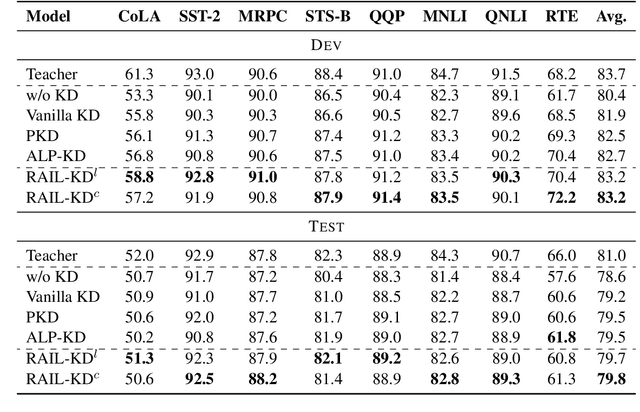
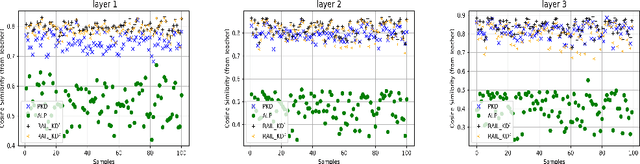
Intermediate layer knowledge distillation (KD) can improve the standard KD technique (which only targets the output of teacher and student models) especially over large pre-trained language models. However, intermediate layer distillation suffers from excessive computational burdens and engineering efforts required for setting up a proper layer mapping. To address these problems, we propose a RAndom Intermediate Layer Knowledge Distillation (RAIL-KD) approach in which, intermediate layers from the teacher model are selected randomly to be distilled into the intermediate layers of the student model. This randomized selection enforce that: all teacher layers are taken into account in the training process, while reducing the computational cost of intermediate layer distillation. Also, we show that it act as a regularizer for improving the generalizability of the student model. We perform extensive experiments on GLUE tasks as well as on out-of-domain test sets. We show that our proposed RAIL-KD approach outperforms other state-of-the-art intermediate layer KD methods considerably in both performance and training-time.
Transformer-based ASR Incorporating Time-reduction Layer and Fine-tuning with Self-Knowledge Distillation
Mar 17, 2021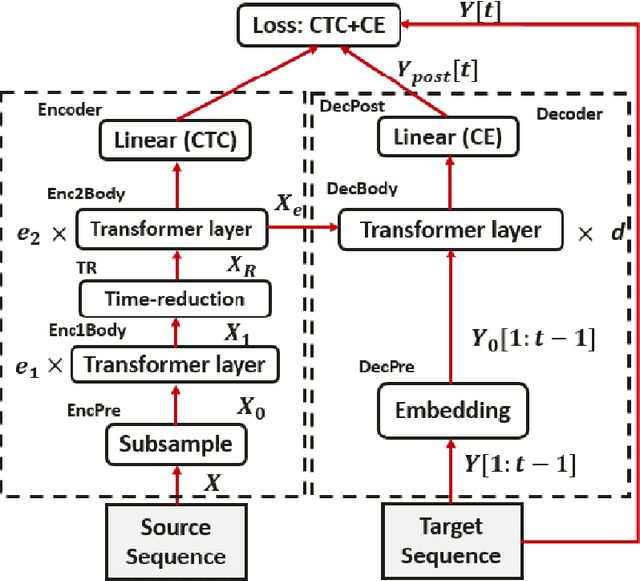
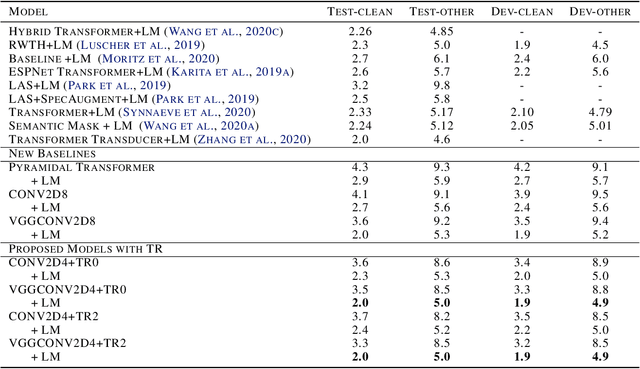
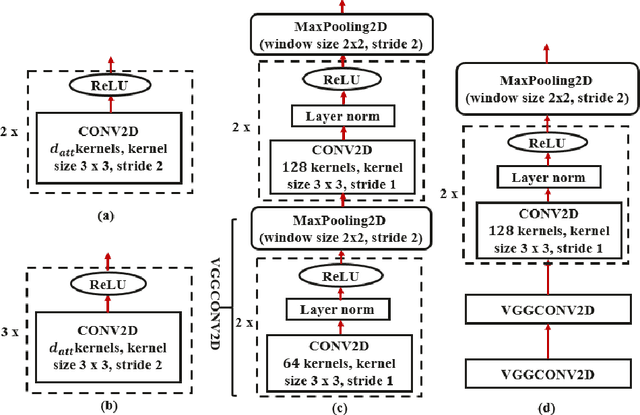
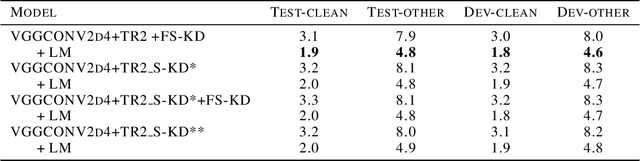
End-to-end automatic speech recognition (ASR), unlike conventional ASR, does not have modules to learn the semantic representation from speech encoder. Moreover, the higher frame-rate of speech representation prevents the model to learn the semantic representation properly. Therefore, the models that are constructed by the lower frame-rate of speech encoder lead to better performance. For Transformer-based ASR, the lower frame-rate is not only important for learning better semantic representation but also for reducing the computational complexity due to the self-attention mechanism which has O(n^2) order of complexity in both training and inference. In this paper, we propose a Transformer-based ASR model with the time reduction layer, in which we incorporate time reduction layer inside transformer encoder layers in addition to traditional sub-sampling methods to input features that further reduce the frame-rate. This can help in reducing the computational cost of the self-attention process for training and inference with performance improvement. Moreover, we introduce a fine-tuning approach for pre-trained ASR models using self-knowledge distillation (S-KD) which further improves the performance of our ASR model. Experiments on LibriSpeech datasets show that our proposed methods outperform all other Transformer-based ASR systems. Furthermore, with language model (LM) fusion, we achieve new state-of-the-art word error rate (WER) results for Transformer-based ASR models with just 30 million parameters trained without any external data.
Fine-tuning of Pre-trained End-to-end Speech Recognition with Generative Adversarial Networks
Mar 10, 2021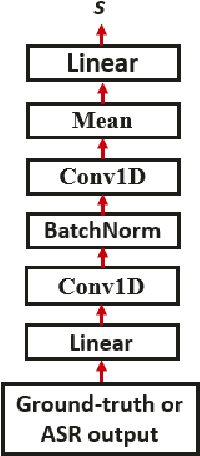
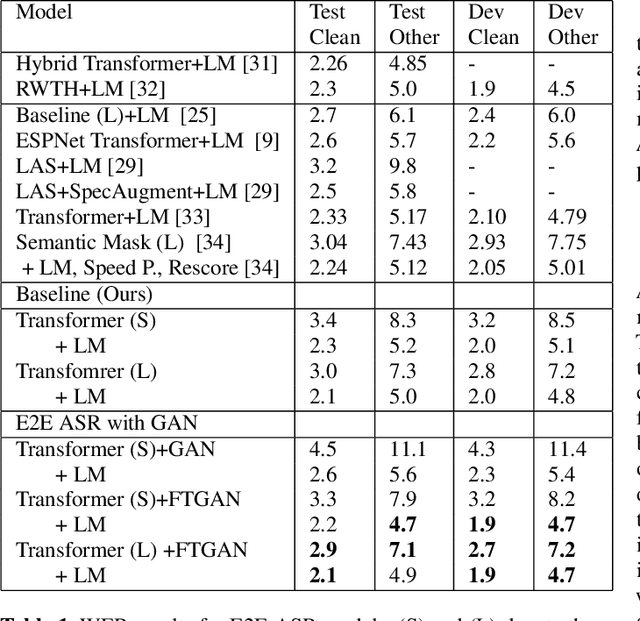
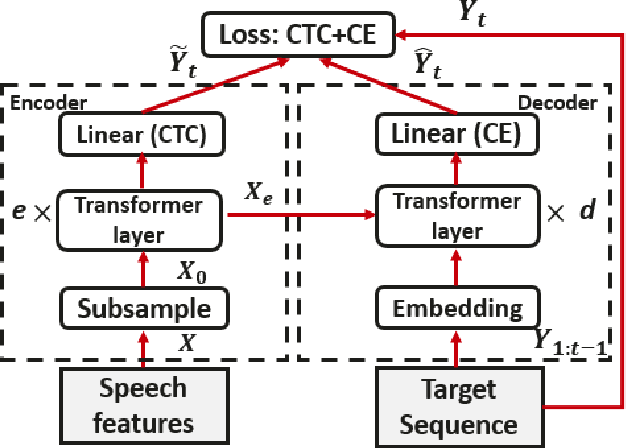
Adversarial training of end-to-end (E2E) ASR systems using generative adversarial networks (GAN) has recently been explored for low-resource ASR corpora. GANs help to learn the true data representation through a two-player min-max game. However, training an E2E ASR model using a large ASR corpus with a GAN framework has never been explored, because it might take excessively long time due to high-variance gradient updates and face convergence issues. In this paper, we introduce a novel framework for fine-tuning a pre-trained ASR model using the GAN objective where the ASR model acts as a generator and a discriminator tries to distinguish the ASR output from the real data. Since the ASR model is pre-trained, we hypothesize that the ASR model output (soft distribution vectors) helps to get higher scores from the discriminator and makes the task of the discriminator harder within our GAN framework, which in turn improves the performance of the ASR model in the fine-tuning stage. Here, the pre-trained ASR model is fine-tuned adversarially against the discriminator using an additional adversarial loss. Experiments on full LibriSpeech dataset show that our proposed approach outperforms baselines and conventional GAN-based adversarial models.
Distilled embedding: non-linear embedding factorization using knowledge distillation
Oct 02, 2019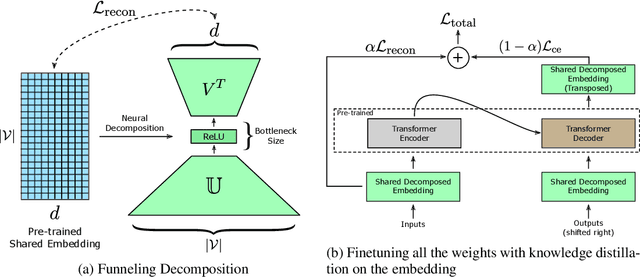
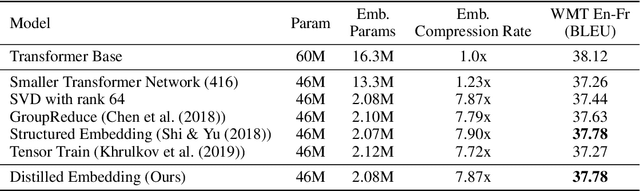
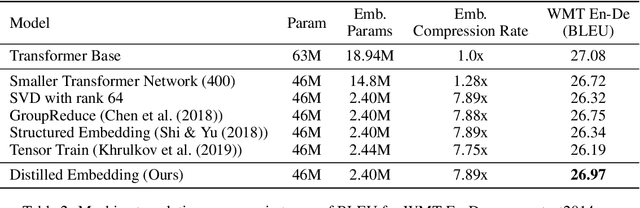
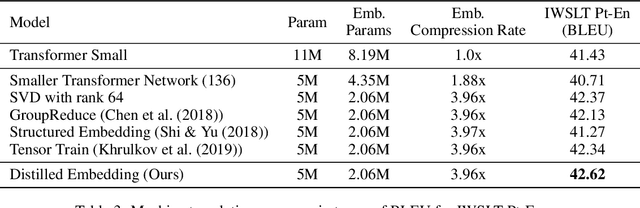
Word-embeddings are a vital component of Natural Language Processing (NLP) systems and have been extensively researched. Better representations of words have come at the cost of huge memory footprints, which has made deploying NLP models on edge-devices challenging due to memory limitations. Compressing embedding matrices without sacrificing model performance is essential for successful commercial edge deployment. In this paper, we propose Distilled Embedding, an (input/output) embedding compression method based on low-rank matrix decomposition with an added non-linearity. First, we initialize the weights of our decomposition by learning to reconstruct the full word-embedding and then fine-tune on the downstream task employing knowledge distillation on the factorized embedding. We conduct extensive experimentation with various compression rates on machine translation, using different data-sets with a shared word-embedding matrix for both embedding and vocabulary projection matrices. We show that the proposed technique outperforms conventional low-rank matrix factorization, and other recently proposed word-embedding matrix compression methods.