 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLM Finetuning for Natural Language to Domain Specific Code Generation in Production
Apr 10, 2026Many applications today use large language models for code generation; however, production systems have strict latency requirements that can be difficult to meet with large models. Small language models with a few billion parameters are resource efficient but may suffer from limited reasoning, hallucinations, or poor retention of longer context. Fine tuning improves task specific accuracy by embedding domain knowledge directly into model weights, reducing reliance on runtime context. We previously implemented a baseline natural language to code generation approach using a retrieval augmented generation pipeline that dynamically selected few shot examples to embed domain specific language context for a large language model. In this study, we evaluate small language models for generating domain specific language from natural language by fine tuning variants of Mistral and other models on a dataset of natural language code pairs. Our results show that the fine-tuned models achieve improved performance and latency on test datasets compared to larger models. We also demonstrate that the trained model can be further fine-tuned for customer specific scenarios without degrading general performance, helping resolve production issues. Load testing followed by production deployment confirmed optimal performance in terms of latency and quality. These findings demonstrate that task specific fine tuning with small language models provides an efficient, faster, and cost-effective alternative to large language models for domain specific language generation.
Conformer with dual-mode chunked attention for joint online and offline ASR
Jun 22, 2022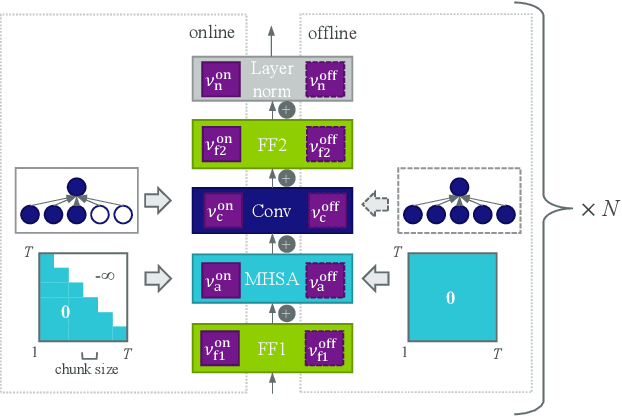
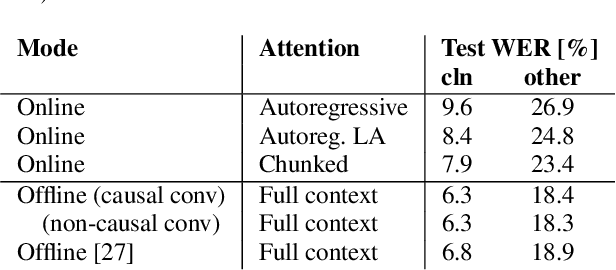
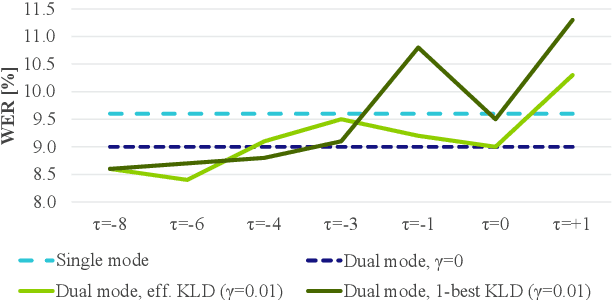
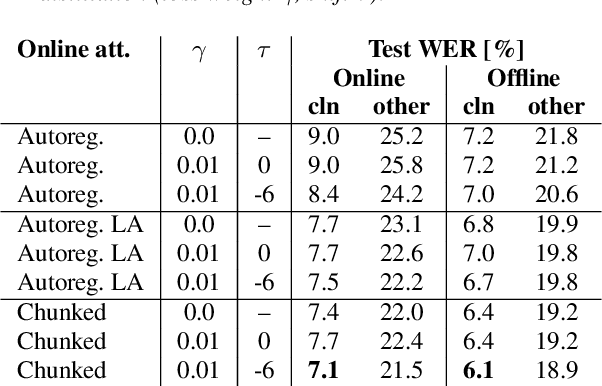
In this paper, we present an in-depth study on online attention mechanisms and distillation techniques for dual-mode (i.e., joint online and offline) ASR using the Conformer Transducer. In the dual-mode Conformer Transducer model, layers can function in online or offline mode while sharing parameters, and in-place knowledge distillation from offline to online mode is applied in training to improve online accuracy. In our study, we first demonstrate accuracy improvements from using chunked attention in the Conformer encoder compared to autoregressive attention with and without lookahead. Furthermore, we explore the efficient KLD and 1-best KLD losses with different shifts between online and offline outputs in the knowledge distillation. Finally, we show that a simplified dual-mode Conformer that only has mode-specific self-attention performs equally well as the one also having mode-specific convolutions and normalization. Our experiments are based on two very different datasets: the Librispeech task and an internal corpus of medical conversations. Results show that the proposed dual-mode system using chunked attention yields 5% and 4% relative WER improvement on the Librispeech and medical tasks, compared to the dual-mode system using autoregressive attention with similar average lookahead.
ChannelAugment: Improving generalization of multi-channel ASR by training with input channel randomization
Sep 23, 2021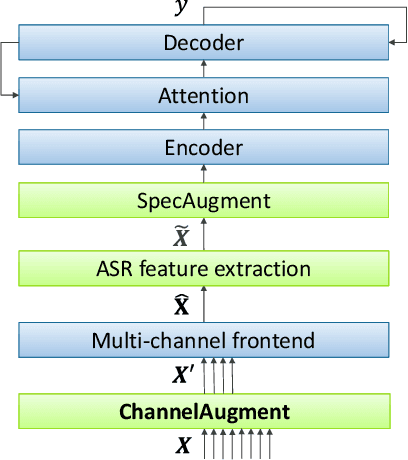
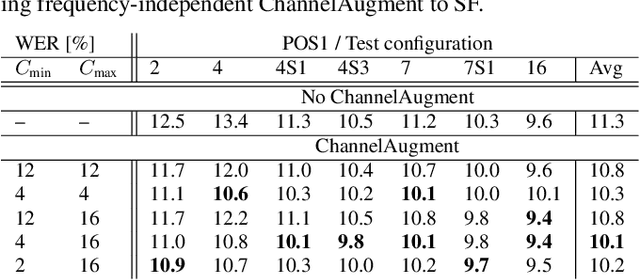
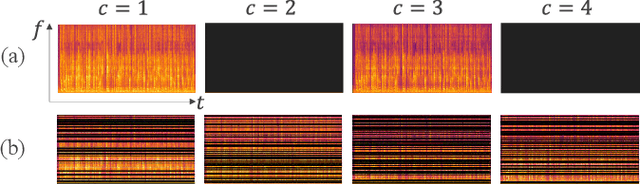
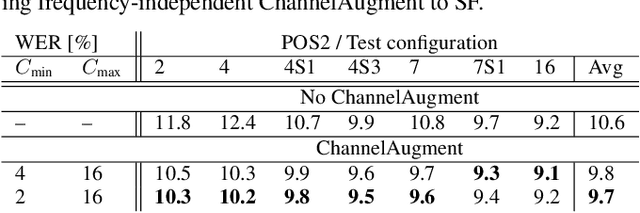
End-to-end (E2E) multi-channel ASR systems show state-of-the-art performance in far-field ASR tasks by joint training of a multi-channel front-end along with the ASR model. The main limitation of such systems is that they are usually trained with data from a fixed array geometry, which can lead to degradation in accuracy when a different array is used in testing. This makes it challenging to deploy these systems in practice, as it is costly to retrain and deploy different models for various array configurations. To address this, we present a simple and effective data augmentation technique, which is based on randomly dropping channels in the multi-channel audio input during training, in order to improve the robustness to various array configurations at test time. We call this technique ChannelAugment, in contrast to SpecAugment (SA) which drops time and/or frequency components of a single channel input audio. We apply ChannelAugment to the Spatial Filtering (SF) and Minimum Variance Distortionless Response (MVDR) neural beamforming approaches. For SF, we observe 10.6% WER improvement across various array configurations employing different numbers of microphones. For MVDR, we achieve a 74% reduction in training time without causing degradation of recognition accuracy.
Dual-Encoder Architecture with Encoder Selection for Joint Close-Talk and Far-Talk Speech Recognition
Sep 17, 2021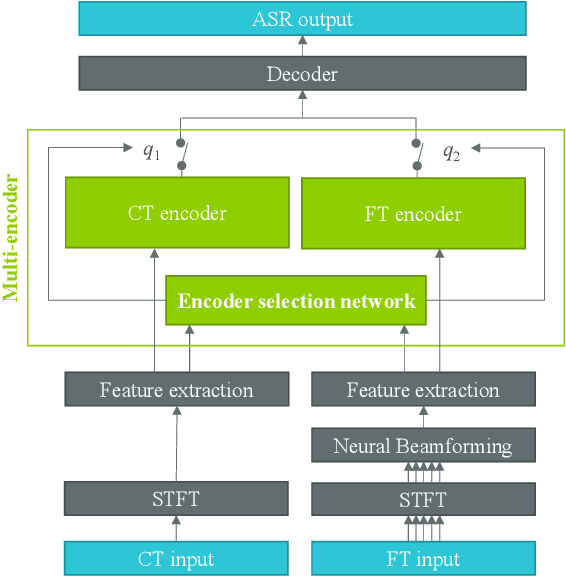

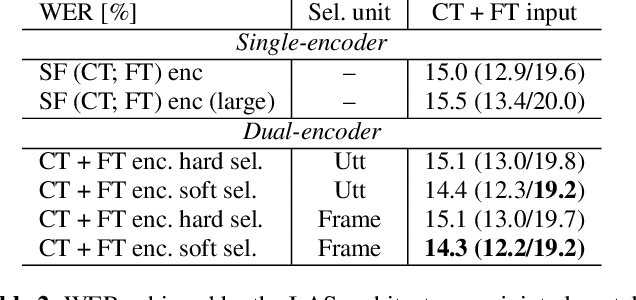
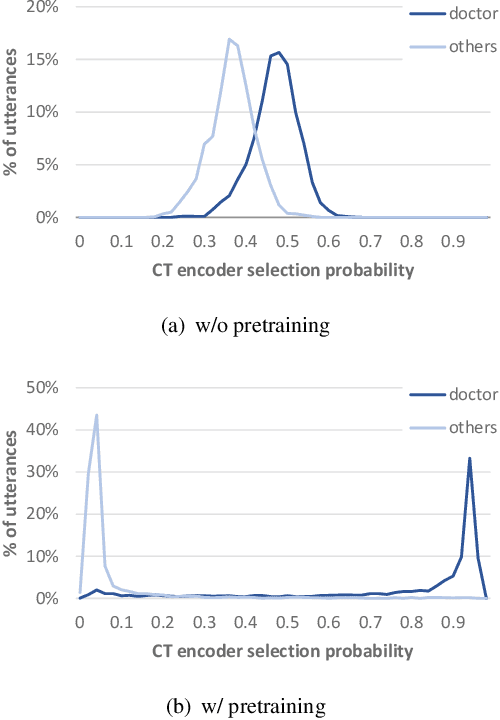
In this paper, we propose a dual-encoder ASR architecture for joint modeling of close-talk (CT) and far-talk (FT) speech, in order to combine the advantages of CT and FT devices for better accuracy. The key idea is to add an encoder selection network to choose the optimal input source (CT or FT) and the corresponding encoder. We use a single-channel encoder for CT speech and a multi-channel encoder with Spatial Filtering neural beamforming for FT speech, which are jointly trained with the encoder selection. We validate our approach on both attention-based and RNN Transducer end-to-end ASR systems. The experiments are done with conversational speech from a medical use case, which is recorded simultaneously with a CT device and a microphone array. Our results show that the proposed dual-encoder architecture obtains up to 9% relative WER reduction when using both CT and FT input, compared to the best single-encoder system trained and tested in matched condition.