 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Encoder Architecture with Encoder Selection for Joint Close-Talk and Far-Talk Speech Recognition
Sep 17, 2021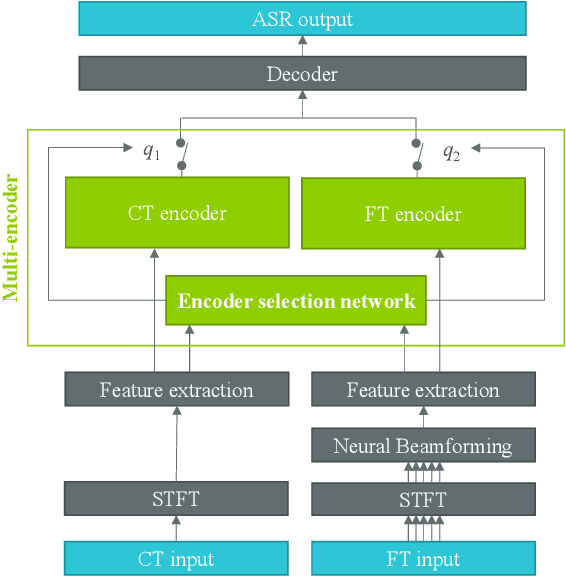

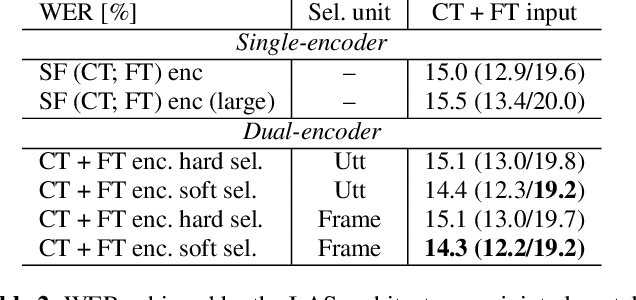
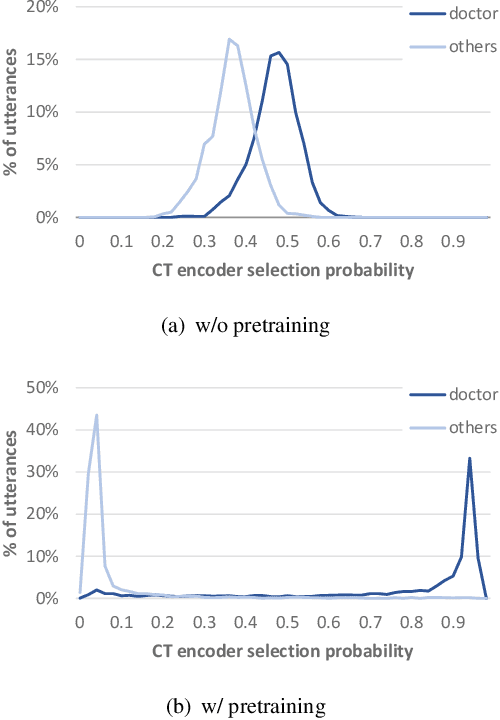
In this paper, we propose a dual-encoder ASR architecture for joint modeling of close-talk (CT) and far-talk (FT) speech, in order to combine the advantages of CT and FT devices for better accuracy. The key idea is to add an encoder selection network to choose the optimal input source (CT or FT) and the corresponding encoder. We use a single-channel encoder for CT speech and a multi-channel encoder with Spatial Filtering neural beamforming for FT speech, which are jointly trained with the encoder selection. We validate our approach on both attention-based and RNN Transducer end-to-end ASR systems. The experiments are done with conversational speech from a medical use case, which is recorded simultaneously with a CT device and a microphone array. Our results show that the proposed dual-encoder architecture obtains up to 9% relative WER reduction when using both CT and FT input, compared to the best single-encoder system trained and tested in matched condition.
Semi-Supervised Learning with Data Augmentation for End-to-End ASR
Jul 27, 2020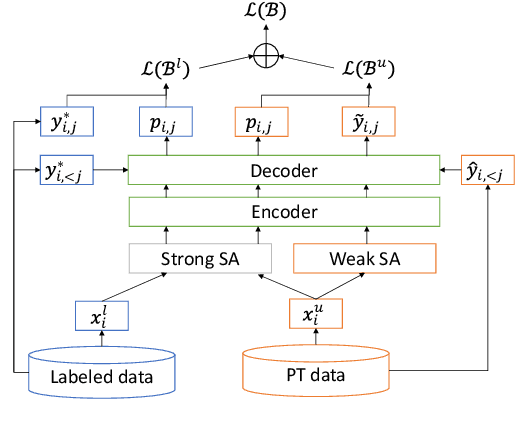

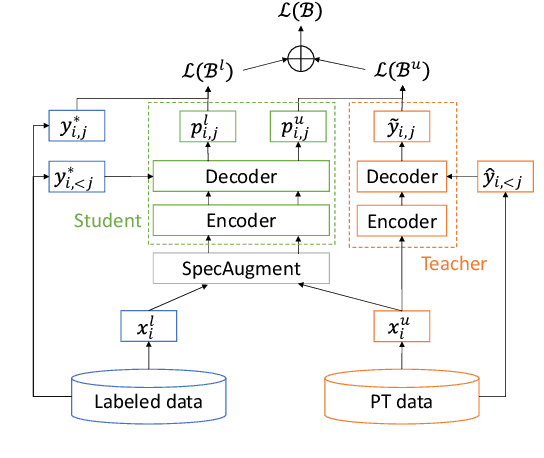
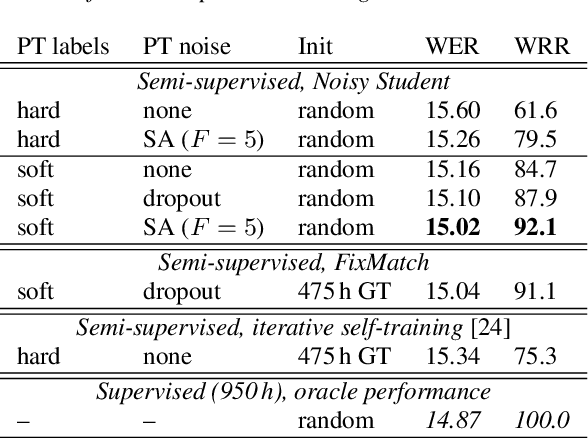
In this paper, we apply Semi-Supervised Learning (SSL) along with Data Augmentation (DA) for improving the accuracy of End-to-End ASR. We focus on the consistency regularization principle, which has been successfully applied to image classification tasks, and present sequence-to-sequence (seq2seq) versions of the FixMatch and Noisy Student algorithms. Specifically, we generate the pseudo labels for the unlabeled data on-the-fly with a seq2seq model after perturbing the input features with DA. We also propose soft label variants of both algorithms to cope with pseudo label errors, showing further performance improvements. We conduct SSL experiments on a conversational speech data set with 1.9kh manually transcribed training data, using only 25% of the original labels (475h labeled data). In the result, the Noisy Student algorithm with soft labels and consistency regularization achieves 10.4% word error rate (WER) reduction when adding 475h of unlabeled data, corresponding to a recovery rate of 92%. Furthermore, when iteratively adding 950h more unlabeled data, our best SSL performance is within 5% WER increase compared to using the full labeled training set (recovery rate: 78%).
Dialogos: a Robust System for Human-Machine Spoken Dialogue on the Telephone
Dec 20, 1996
This paper presents Dialogos, a real-time system for human-machine spoken dialogue on the telephone in task-oriented domains. The system has been tested in a large trial with inexperienced users and it has proved robust enough to allow spontaneous interactions both to users which get good recognition performance and to the ones which get lower scores. The robust behavior of the system has been achieved by combining the use of specific language models during the recognition phase of analysis, the tolerance toward spontaneous speech phenomena, the activity of a robust parser, and the use of pragmatic-based dialogue knowledge. This integration of the different modules allows to deal with partial or total breakdowns of the different levels of analysis. We report the field trial data of the system and the evaluation results of the overall system and of the submodules.