 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Information and Specific Language Models for Spoken Language Understanding
Nov 19, 1997



In this paper we explain how contextual expectations are generated and used in the task-oriented spoken language understanding system Dialogos. The hard task of recognizing spontaneous speech on the telephone may greatly benefit from the use of specific language models during the recognition of callers' utterances. By 'specific language models' we mean a set of language models that are trained on contextually appropriated data, and that are used during different states of the dialogue on the basis of the information sent to the acoustic level by the dialogue management module. In this paper we describe how the specific language models are obtained on the basis of contextual information. The experimental result we report show that recognition and understanding performance are improved thanks to the use of specific language models.
* 6 pages, Latex, uses aclap.sty
Dialogos: a Robust System for Human-Machine Spoken Dialogue on the Telephone
Dec 20, 1996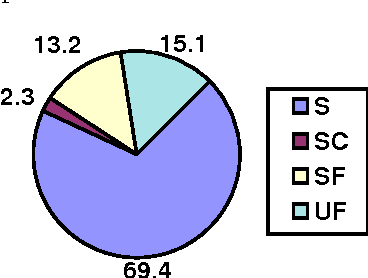
This paper presents Dialogos, a real-time system for human-machine spoken dialogue on the telephone in task-oriented domains. The system has been tested in a large trial with inexperienced users and it has proved robust enough to allow spontaneous interactions both to users which get good recognition performance and to the ones which get lower scores. The robust behavior of the system has been achieved by combining the use of specific language models during the recognition phase of analysis, the tolerance toward spontaneous speech phenomena, the activity of a robust parser, and the use of pragmatic-based dialogue knowledge. This integration of the different modules allows to deal with partial or total breakdowns of the different levels of analysis. We report the field trial data of the system and the evaluation results of the overall system and of the submodules.
Metrics for Evaluating Dialogue Strategies in a Spoken Language System
Dec 17, 1996

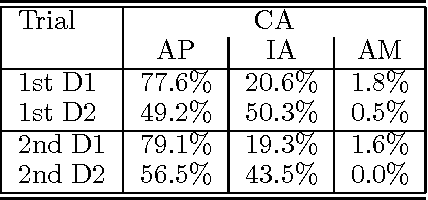
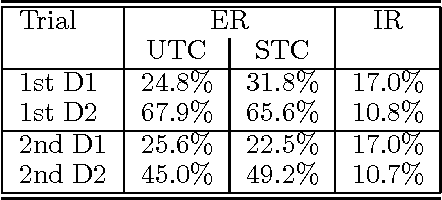
In this paper, we describe a set of metrics for the evaluation of different dialogue management strategies in an implemented real-time spoken language system. The set of metrics we propose offers useful insights in evaluating how particular choices in the dialogue management can affect the overall quality of the man-machine dialogue. The evaluation makes use of established metrics: the transaction success, the contextual appropriateness of system answers, the calculation of normal and correction turns in a dialogue. We also define a new metric, the implicit recovery, which allows to measure the ability of a dialogue manager to deal with errors by different levels of analysis. We report evaluation data from several experiments, and we compare two different approaches to dialogue repair strategies using the set of metrics we argue for.