 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Density Ratio for Language Model Biasing of Sequence to Sequence ASR Systems
Jun 29, 2022
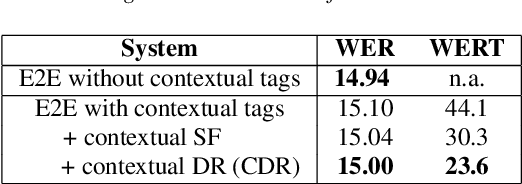

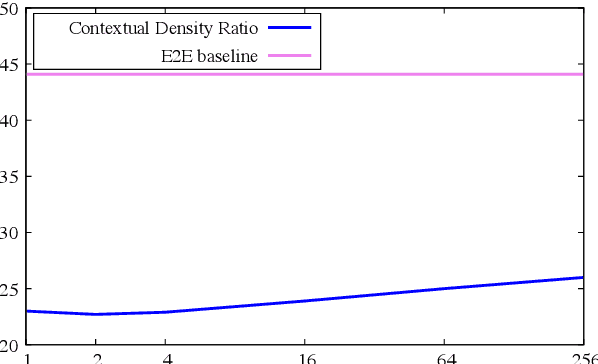
End-2-end (E2E) models have become increasingly popular in some ASR tasks because of their performance and advantages. These E2E models directly approximate the posterior distribution of tokens given the acoustic inputs. Consequently, the E2E systems implicitly define a language model (LM) over the output tokens, which makes the exploitation of independently trained language models less straightforward than in conventional ASR systems. This makes it difficult to dynamically adapt E2E ASR system to contextual profiles for better recognizing special words such as named entities. In this work, we propose a contextual density ratio approach for both training a contextual aware E2E model and adapting the language model to named entities. We apply the aforementioned technique to an E2E ASR system, which transcribes doctor and patient conversations, for better adapting the E2E system to the names in the conversations. Our proposed technique achieves a relative improvement of up to 46.5% on the names over an E2E baseline without degrading the overall recognition accuracy of the whole test set. Moreover, it also surpasses a contextual shallow fusion baseline by 22.1 % relative.
* Interspeech 2021 (draft)
On the Prediction Network Architecture in RNN-T for ASR
Jun 29, 2022
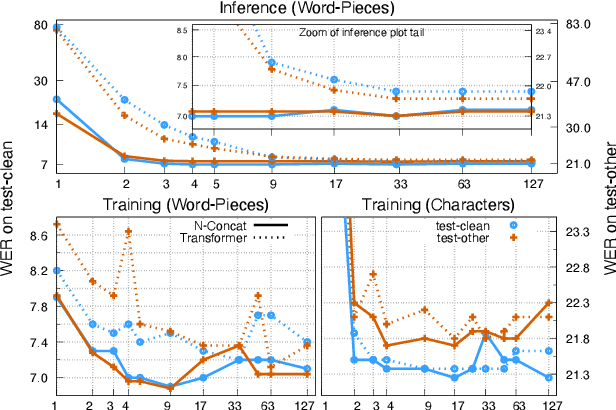
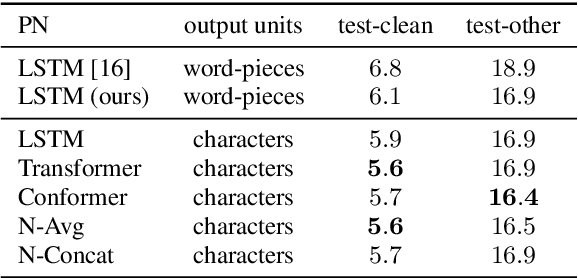

RNN-T models have gained popularity in the literature and in commercial systems because of their competitiveness and capability of operating in online streaming mode. In this work, we conduct an extensive study comparing several prediction network architectures for both monotonic and original RNN-T models. We compare 4 types of prediction networks based on a common state-of-the-art Conformer encoder and report results obtained on Librispeech and an internal medical conversation data set. Our study covers both offline batch-mode and online streaming scenarios. In contrast to some previous works, our results show that Transformer does not always outperform LSTM when used as prediction network along with Conformer encoder. Inspired by our scoreboard, we propose a new simple prediction network architecture, N-Concat, that outperforms the others in our on-line streaming benchmark. Transformer and n-gram reduced architectures perform very similarly yet with some important distinct behaviour in terms of previous context. Overall we obtained up to 4.1 % relative WER improvement compared to our LSTM baseline, while reducing prediction network parameters by nearly an order of magnitude (8.4 times).
Dialogos: a Robust System for Human-Machine Spoken Dialogue on the Telephone
Dec 20, 1996
This paper presents Dialogos, a real-time system for human-machine spoken dialogue on the telephone in task-oriented domains. The system has been tested in a large trial with inexperienced users and it has proved robust enough to allow spontaneous interactions both to users which get good recognition performance and to the ones which get lower scores. The robust behavior of the system has been achieved by combining the use of specific language models during the recognition phase of analysis, the tolerance toward spontaneous speech phenomena, the activity of a robust parser, and the use of pragmatic-based dialogue knowledge. This integration of the different modules allows to deal with partial or total breakdowns of the different levels of analysis. We report the field trial data of the system and the evaluation results of the overall system and of the submodules.