 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSweEval: Do LLMs Really Swear? A Safety Benchmark for Testing Limits for Enterprise Use
May 22, 2025Enterprise customers are increasingly adopting Large Language Models (LLMs) for critical communication tasks, such as drafting emails, crafting sales pitches, and composing casual messages. Deploying such models across different regions requires them to understand diverse cultural and linguistic contexts and generate safe and respectful responses. For enterprise applications, it is crucial to mitigate reputational risks, maintain trust, and ensure compliance by effectively identifying and handling unsafe or offensive language. To address this, we introduce SweEval, a benchmark simulating real-world scenarios with variations in tone (positive or negative) and context (formal or informal). The prompts explicitly instruct the model to include specific swear words while completing the task. This benchmark evaluates whether LLMs comply with or resist such inappropriate instructions and assesses their alignment with ethical frameworks, cultural nuances, and language comprehension capabilities. In order to advance research in building ethically aligned AI systems for enterprise use and beyond, we release the dataset and code: https://github.com/amitbcp/multilingual_profanity.
Improving Clinical Question Answering with Multi-Task Learning: A Joint Approach for Answer Extraction and Medical Categorization
Feb 18, 2025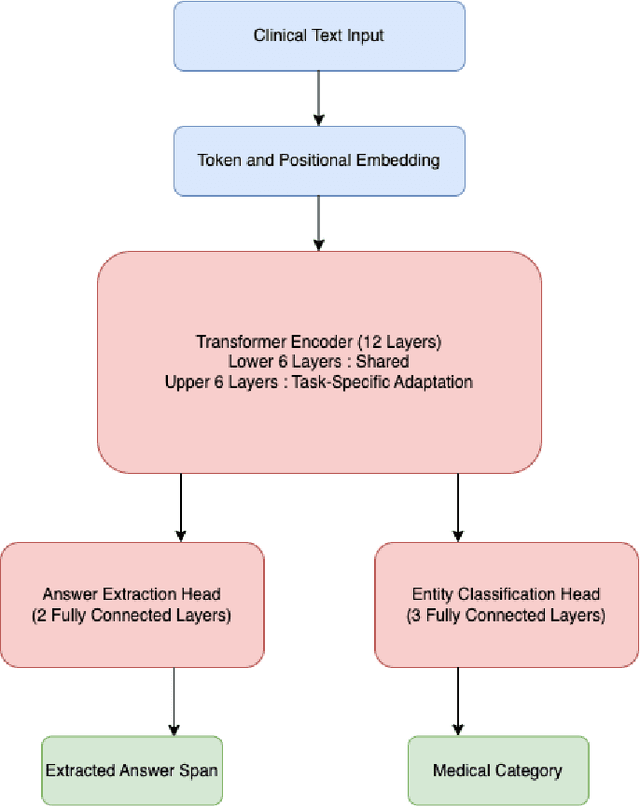
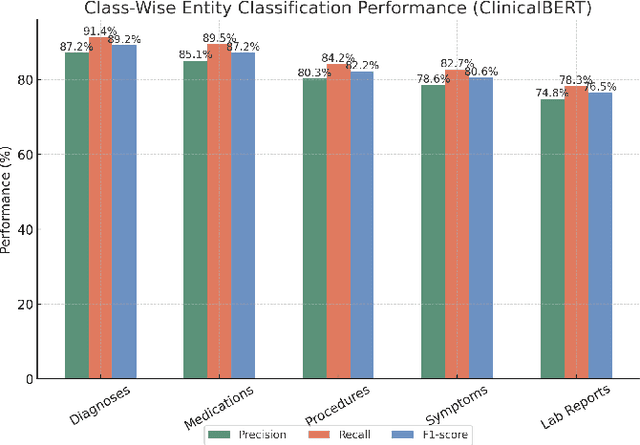
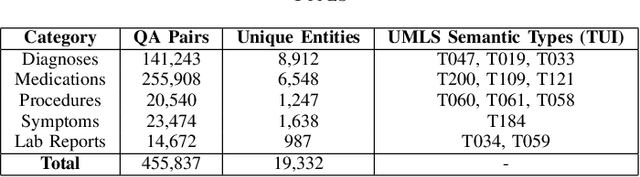

Clinical Question Answering (CQA) plays a crucial role in medical decision-making, enabling physicians to extract relevant information from Electronic Medical Records (EMRs). While transformer-based models such as BERT, BioBERT, and ClinicalBERT have demonstrated state-of-the-art performance in CQA, existing models lack the ability to categorize extracted answers, which is critical for structured retrieval, content filtering, and medical decision support. To address this limitation, we introduce a Multi-Task Learning (MTL) framework that jointly trains CQA models for both answer extraction and medical categorization. In addition to predicting answer spans, our model classifies responses into five standardized medical categories: Diagnosis, Medication, Symptoms, Procedure, and Lab Reports. This categorization enables more structured and interpretable outputs, making clinical QA models more useful in real-world healthcare settings. We evaluate our approach on emrQA, a large-scale dataset for medical question answering. Results show that MTL improves F1-score by 2.2% compared to standard fine-tuning, while achieving 90.7% accuracy in answer categorization. These findings suggest that MTL not only enhances CQA performance but also introduces an effective mechanism for categorization and structured medical information retrieval.
MVTamperBench: Evaluating Robustness of Vision-Language Models
Dec 27, 2024Recent advancements in Vision-Language Models (VLMs) have enabled significant progress in complex video understanding tasks. However, their robustness to real-world manipulations remains underexplored, limiting their reliability in critical applications. To address this gap, we introduce MVTamperBench, a comprehensive benchmark designed to evaluate VLM's resilience to video tampering effects, including rotation, dropping, masking, substitution, and repetition. By systematically assessing state-of-the-art models, MVTamperBench reveals substantial variability in robustness, with models like InternVL2-8B achieving high performance, while others, such as Llama-VILA1.5-8B, exhibit severe vulnerabilities. To foster broader adoption and reproducibility, MVTamperBench is integrated into VLMEvalKit, a modular evaluation toolkit, enabling streamlined testing and facilitating advancements in model robustness. Our benchmark represents a critical step towards developing tamper-resilient VLMs, ensuring their dependability in real-world scenarios. Project Page: https://amitbcp.github.io/MVTamperBench/
Survey of Large Multimodal Model Datasets, Application Categories and Taxonomy
Dec 23, 2024Multimodal learning, a rapidly evolving field in artificial intelligence, seeks to construct more versatile and robust systems by integrating and analyzing diverse types of data, including text, images, audio, and video. Inspired by the human ability to assimilate information through many senses, this method enables applications such as text-to-video conversion, visual question answering, and image captioning. Recent developments in datasets that support multimodal language models (MLLMs) are highlighted in this overview. Large-scale multimodal datasets are essential because they allow for thorough testing and training of these models. With an emphasis on their contributions to the discipline, the study examines a variety of datasets, including those for training, domain-specific tasks, and real-world applications. It also emphasizes how crucial benchmark datasets are for assessing models' performance in a range of scenarios, scalability, and applicability. Since multimodal learning is always changing, overcoming these obstacles will help AI research and applications reach new heights.
Enhancing Document AI Data Generation Through Graph-Based Synthetic Layouts
Nov 27, 2024The development of robust Document AI models has been constrained by limited access to high-quality, labeled datasets, primarily due to data privacy concerns, scarcity, and the high cost of manual annotation. Traditional methods of synthetic data generation, such as text and image augmentation, have proven effective for increasing data diversity but often fail to capture the complex layout structures present in real world documents. This paper proposes a novel approach to synthetic document layout generation using Graph Neural Networks (GNNs). By representing document elements (e.g., text blocks, images, tables) as nodes in a graph and their spatial relationships as edges, GNNs are trained to generate realistic and diverse document layouts. This method leverages graph-based learning to ensure structural coherence and semantic consistency, addressing the limitations of traditional augmentation techniques. The proposed framework is evaluated on tasks such as document classification, named entity recognition (NER), and information extraction, demonstrating significant performance improvements. Furthermore, we address the computational challenges of GNN based synthetic data generation and propose solutions to mitigate domain adaptation issues between synthetic and real-world datasets. Our experimental results show that graph-augmented document layouts outperform existing augmentation techniques, offering a scalable and flexible solution for training Document AI models.
* Published in IJERT, Volume 13, Issue 10 (October 2024)
LLM for Barcodes: Generating Diverse Synthetic Data for Identity Documents
Nov 22, 2024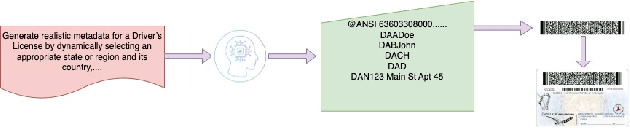

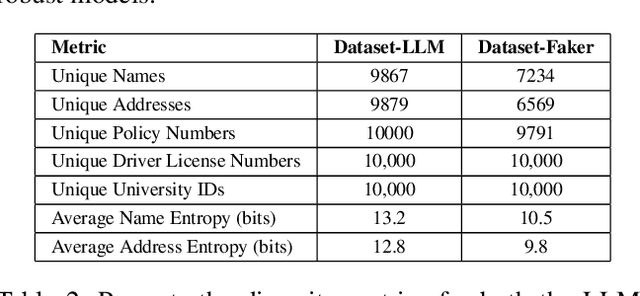
Accurate barcode detection and decoding in Identity documents is crucial for applications like security, healthcare, and education, where reliable data extraction and verification are essential. However, building robust detection models is challenging due to the lack of diverse, realistic datasets an issue often tied to privacy concerns and the wide variety of document formats. Traditional tools like Faker rely on predefined templates, making them less effective for capturing the complexity of real-world identity documents. In this paper, we introduce a new approach to synthetic data generation that uses LLMs to create contextually rich and realistic data without relying on predefined field. Using the vast knowledge LLMs have about different documents and content, our method creates data that reflects the variety found in real identity documents. This data is then encoded into barcode and overlayed on templates for documents such as Driver's licenses, Insurance cards, Student IDs. Our approach simplifies the process of dataset creation, eliminating the need for extensive domain knowledge or predefined fields. Compared to traditional methods like Faker, data generated by LLM demonstrates greater diversity and contextual relevance, leading to improved performance in barcode detection models. This scalable, privacy-first solution is a big step forward in advancing machine learning for automated document processing and identity verification.
Conformal Prediction Sets Can Cause Disparate Impact
Oct 02, 2024Although conformal prediction is a promising method for quantifying the uncertainty of machine learning models, the prediction sets it outputs are not inherently actionable. Many applications require a single output to act on, not several. To overcome this, prediction sets can be provided to a human who then makes an informed decision. In any such system it is crucial to ensure the fairness of outcomes across protected groups, and researchers have proposed that Equalized Coverage be used as the standard for fairness. By conducting experiments with human participants, we demonstrate that providing prediction sets can increase the unfairness of their decisions. Disquietingly, we find that providing sets that satisfy Equalized Coverage actually increases unfairness compared to marginal coverage. Instead of equalizing coverage, we propose to equalize set sizes across groups which empirically leads to more fair outcomes.
Conformal Prediction Sets Improve Human Decision Making
Feb 01, 2024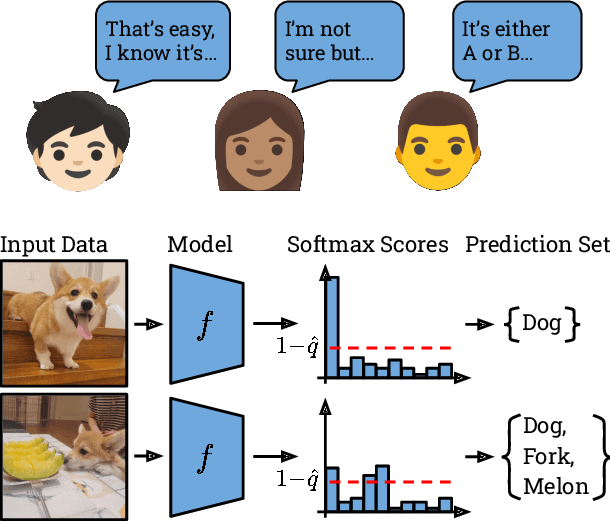
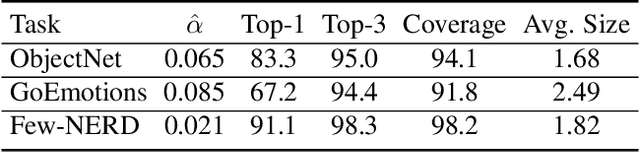
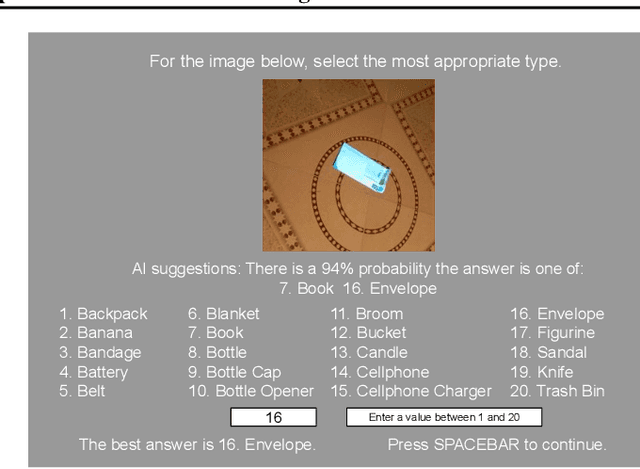

In response to everyday queries, humans explicitly signal uncertainty and offer alternative answers when they are unsure. Machine learning models that output calibrated prediction sets through conformal prediction mimic this human behaviour; larger sets signal greater uncertainty while providing alternatives. In this work, we study the usefulness of conformal prediction sets as an aid for human decision making by conducting a pre-registered randomized controlled trial with conformal prediction sets provided to human subjects. With statistical significance, we find that when humans are given conformal prediction sets their accuracy on tasks improves compared to fixed-size prediction sets with the same coverage guarantee. The results show that quantifying model uncertainty with conformal prediction is helpful for human-in-the-loop decision making and human-AI teams.