 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSweEval: Do LLMs Really Swear? A Safety Benchmark for Testing Limits for Enterprise Use
May 22, 2025Enterprise customers are increasingly adopting Large Language Models (LLMs) for critical communication tasks, such as drafting emails, crafting sales pitches, and composing casual messages. Deploying such models across different regions requires them to understand diverse cultural and linguistic contexts and generate safe and respectful responses. For enterprise applications, it is crucial to mitigate reputational risks, maintain trust, and ensure compliance by effectively identifying and handling unsafe or offensive language. To address this, we introduce SweEval, a benchmark simulating real-world scenarios with variations in tone (positive or negative) and context (formal or informal). The prompts explicitly instruct the model to include specific swear words while completing the task. This benchmark evaluates whether LLMs comply with or resist such inappropriate instructions and assesses their alignment with ethical frameworks, cultural nuances, and language comprehension capabilities. In order to advance research in building ethically aligned AI systems for enterprise use and beyond, we release the dataset and code: https://github.com/amitbcp/multilingual_profanity.
Crowdsource, Crawl, or Generate? Creating SEA-VL, a Multicultural Vision-Language Dataset for Southeast Asia
Mar 10, 2025



Southeast Asia (SEA) is a region of extraordinary linguistic and cultural diversity, yet it remains significantly underrepresented in vision-language (VL) research. This often results in artificial intelligence (AI) models that fail to capture SEA cultural nuances. To fill this gap, we present SEA-VL, an open-source initiative dedicated to developing high-quality, culturally relevant data for SEA languages. By involving contributors from SEA countries, SEA-VL aims to ensure better cultural relevance and diversity, fostering greater inclusivity of underrepresented languages in VL research. Beyond crowdsourcing, our initiative goes one step further in the exploration of the automatic collection of culturally relevant images through crawling and image generation. First, we find that image crawling achieves approximately ~85% cultural relevance while being more cost- and time-efficient than crowdsourcing. Second, despite the substantial progress in generative vision models, synthetic images remain unreliable in accurately reflecting SEA cultures. The generated images often fail to reflect the nuanced traditions and cultural contexts of the region. Collectively, we gather 1.28M SEA culturally-relevant images, more than 50 times larger than other existing datasets. Through SEA-VL, we aim to bridge the representation gap in SEA, fostering the development of more inclusive AI systems that authentically represent diverse cultures across SEA.
MVTamperBench: Evaluating Robustness of Vision-Language Models
Dec 27, 2024Recent advancements in Vision-Language Models (VLMs) have enabled significant progress in complex video understanding tasks. However, their robustness to real-world manipulations remains underexplored, limiting their reliability in critical applications. To address this gap, we introduce MVTamperBench, a comprehensive benchmark designed to evaluate VLM's resilience to video tampering effects, including rotation, dropping, masking, substitution, and repetition. By systematically assessing state-of-the-art models, MVTamperBench reveals substantial variability in robustness, with models like InternVL2-8B achieving high performance, while others, such as Llama-VILA1.5-8B, exhibit severe vulnerabilities. To foster broader adoption and reproducibility, MVTamperBench is integrated into VLMEvalKit, a modular evaluation toolkit, enabling streamlined testing and facilitating advancements in model robustness. Our benchmark represents a critical step towards developing tamper-resilient VLMs, ensuring their dependability in real-world scenarios. Project Page: https://amitbcp.github.io/MVTamperBench/
GReFEL: Geometry-Aware Reliable Facial Expression Learning under Bias and Imbalanced Data Distribution
Oct 21, 2024Reliable facial expression learning (FEL) involves the effective learning of distinctive facial expression characteristics for more reliable, unbiased and accurate predictions in real-life settings. However, current systems struggle with FEL tasks because of the variance in people's facial expressions due to their unique facial structures, movements, tones, and demographics. Biased and imbalanced datasets compound this challenge, leading to wrong and biased prediction labels. To tackle these, we introduce GReFEL, leveraging Vision Transformers and a facial geometry-aware anchor-based reliability balancing module to combat imbalanced data distributions, bias, and uncertainty in facial expression learning. Integrating local and global data with anchors that learn different facial data points and structural features, our approach adjusts biased and mislabeled emotions caused by intra-class disparity, inter-class similarity, and scale sensitivity, resulting in comprehensive, accurate, and reliable facial expression predictions. Our model outperforms current state-of-the-art methodologies, as demonstrated by extensive experiments on various datasets.
Exploring Bengali Religious Dialect Biases in Large Language Models with Evaluation Perspectives
Jul 25, 2024



While Large Language Models (LLM) have created a massive technological impact in the past decade, allowing for human-enabled applications, they can produce output that contains stereotypes and biases, especially when using low-resource languages. This can be of great ethical concern when dealing with sensitive topics such as religion. As a means toward making LLMS more fair, we explore bias from a religious perspective in Bengali, focusing specifically on two main religious dialects: Hindu and Muslim-majority dialects. Here, we perform different experiments and audit showing the comparative analysis of different sentences using three commonly used LLMs: ChatGPT, Gemini, and Microsoft Copilot, pertaining to the Hindu and Muslim dialects of specific words and showcasing which ones catch the social biases and which do not. Furthermore, we analyze our findings and relate them to potential reasons and evaluation perspectives, considering their global impact with over 300 million speakers worldwide. With this work, we hope to establish the rigor for creating more fairness in LLMs, as these are widely used as creative writing agents.
BanglaAutoKG: Automatic Bangla Knowledge Graph Construction with Semantic Neural Graph Filtering
Apr 05, 2024Knowledge Graphs (KGs) have proven essential in information processing and reasoning applications because they link related entities and give context-rich information, supporting efficient information retrieval and knowledge discovery; presenting information flow in a very effective manner. Despite being widely used globally, Bangla is relatively underrepresented in KGs due to a lack of comprehensive datasets, encoders, NER (named entity recognition) models, POS (part-of-speech) taggers, and lemmatizers, hindering efficient information processing and reasoning applications in the language. Addressing the KG scarcity in Bengali, we propose BanglaAutoKG, a pioneering framework that is able to automatically construct Bengali KGs from any Bangla text. We utilize multilingual LLMs to understand various languages and correlate entities and relations universally. By employing a translation dictionary to identify English equivalents and extracting word features from pre-trained BERT models, we construct the foundational KG. To reduce noise and align word embeddings with our goal, we employ graph-based polynomial filters. Lastly, we implement a GNN-based semantic filter, which elevates contextual understanding and trims unnecessary edges, culminating in the formation of the definitive KG. Empirical findings and case studies demonstrate the universal effectiveness of our model, capable of autonomously constructing semantically enriched KGs from any text.
CADGL: Context-Aware Deep Graph Learning for Predicting Drug-Drug Interactions
Mar 27, 2024



Examining Drug-Drug Interactions (DDIs) is a pivotal element in the process of drug development. DDIs occur when one drug's properties are affected by the inclusion of other drugs. Detecting favorable DDIs has the potential to pave the way for creating and advancing innovative medications applicable in practical settings. However, existing DDI prediction models continue to face challenges related to generalization in extreme cases, robust feature extraction, and real-life application possibilities. We aim to address these challenges by leveraging the effectiveness of context-aware deep graph learning by introducing a novel framework named CADGL. Based on a customized variational graph autoencoder (VGAE), we capture critical structural and physio-chemical information using two context preprocessors for feature extraction from two different perspectives: local neighborhood and molecular context, in a heterogeneous graphical structure. Our customized VGAE consists of a graph encoder, a latent information encoder, and an MLP decoder. CADGL surpasses other state-of-the-art DDI prediction models, excelling in predicting clinically valuable novel DDIs, supported by rigorous case studies.
ARBEx: Attentive Feature Extraction with Reliability Balancing for Robust Facial Expression Learning
May 02, 2023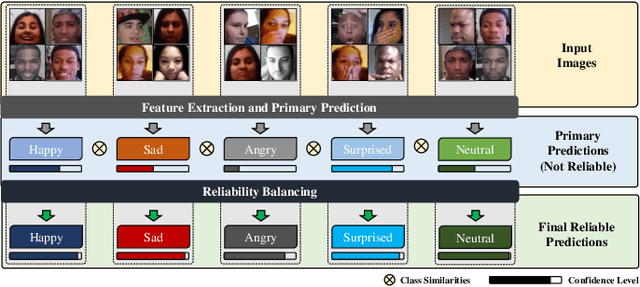



In this paper, we introduce a framework ARBEx, a novel attentive feature extraction framework driven by Vision Transformer with reliability balancing to cope against poor class distributions, bias, and uncertainty in the facial expression learning (FEL) task. We reinforce several data pre-processing and refinement methods along with a window-based cross-attention ViT to squeeze the best of the data. We also employ learnable anchor points in the embedding space with label distributions and multi-head self-attention mechanism to optimize performance against weak predictions with reliability balancing, which is a strategy that leverages anchor points, attention scores, and confidence values to enhance the resilience of label predictions. To ensure correct label classification and improve the models' discriminative power, we introduce anchor loss, which encourages large margins between anchor points. Additionally, the multi-head self-attention mechanism, which is also trainable, plays an integral role in identifying accurate labels. This approach provides critical elements for improving the reliability of predictions and has a substantial positive effect on final prediction capabilities. Our adaptive model can be integrated with any deep neural network to forestall challenges in various recognition tasks. Our strategy outperforms current state-of-the-art methodologies, according to extensive experiments conducted in a variety of contexts.