 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM for Barcodes: Generating Diverse Synthetic Data for Identity Documents
Paper and Code
Nov 22, 2024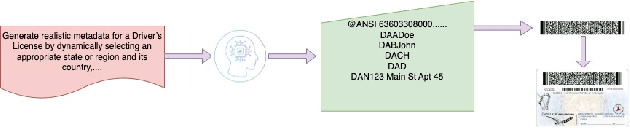

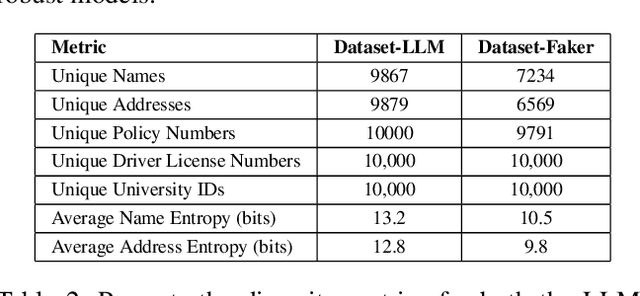
Accurate barcode detection and decoding in Identity documents is crucial for applications like security, healthcare, and education, where reliable data extraction and verification are essential. However, building robust detection models is challenging due to the lack of diverse, realistic datasets an issue often tied to privacy concerns and the wide variety of document formats. Traditional tools like Faker rely on predefined templates, making them less effective for capturing the complexity of real-world identity documents. In this paper, we introduce a new approach to synthetic data generation that uses LLMs to create contextually rich and realistic data without relying on predefined field. Using the vast knowledge LLMs have about different documents and content, our method creates data that reflects the variety found in real identity documents. This data is then encoded into barcode and overlayed on templates for documents such as Driver's licenses, Insurance cards, Student IDs. Our approach simplifies the process of dataset creation, eliminating the need for extensive domain knowledge or predefined fields. Compared to traditional methods like Faker, data generated by LLM demonstrates greater diversity and contextual relevance, leading to improved performance in barcode detection models. This scalable, privacy-first solution is a big step forward in advancing machine learning for automated document processing and identity verification.