 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative or Discriminative? Revisiting Text Classification in the Era of Transformers
Jun 13, 2025The comparison between discriminative and generative classifiers has intrigued researchers since Efron's seminal analysis of logistic regression versus discriminant analysis. While early theoretical work established that generative classifiers exhibit lower sample complexity but higher asymptotic error in simple linear settings, these trade-offs remain unexplored in the transformer era. We present the first comprehensive evaluation of modern generative and discriminative architectures - Auto-regressive modeling, Masked Language Modeling, Discrete Diffusion, and Encoders for text classification. Our study reveals that the classical 'two regimes' phenomenon manifests distinctly across different architectures and training paradigms. Beyond accuracy, we analyze sample efficiency, calibration, noise robustness, and ordinality across diverse scenarios. Our findings offer practical guidance for selecting the most suitable modeling approach based on real-world constraints such as latency and data limitations.
CXMArena: Unified Dataset to benchmark performance in realistic CXM Scenarios
May 14, 2025Large Language Models (LLMs) hold immense potential for revolutionizing Customer Experience Management (CXM), particularly in contact center operations. However, evaluating their practical utility in complex operational environments is hindered by data scarcity (due to privacy concerns) and the limitations of current benchmarks. Existing benchmarks often lack realism, failing to incorporate deep knowledge base (KB) integration, real-world noise, or critical operational tasks beyond conversational fluency. To bridge this gap, we introduce CXMArena, a novel, large-scale synthetic benchmark dataset specifically designed for evaluating AI in operational CXM contexts. Given the diversity in possible contact center features, we have developed a scalable LLM-powered pipeline that simulates the brand's CXM entities that form the foundation of our datasets-such as knowledge articles including product specifications, issue taxonomies, and contact center conversations. The entities closely represent real-world distribution because of controlled noise injection (informed by domain experts) and rigorous automated validation. Building on this, we release CXMArena, which provides dedicated benchmarks targeting five important operational tasks: Knowledge Base Refinement, Intent Prediction, Agent Quality Adherence, Article Search, and Multi-turn RAG with Integrated Tools. Our baseline experiments underscore the benchmark's difficulty: even state of the art embedding and generation models achieve only 68% accuracy on article search, while standard embedding methods yield a low F1 score of 0.3 for knowledge base refinement, highlighting significant challenges for current models necessitating complex pipelines and solutions over conventional techniques.
LLM for Barcodes: Generating Diverse Synthetic Data for Identity Documents
Nov 22, 2024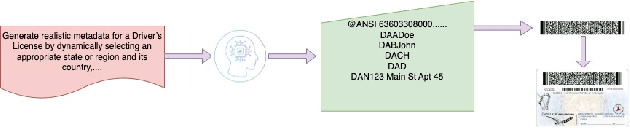

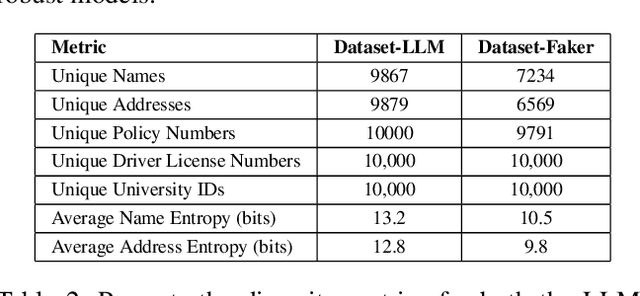
Accurate barcode detection and decoding in Identity documents is crucial for applications like security, healthcare, and education, where reliable data extraction and verification are essential. However, building robust detection models is challenging due to the lack of diverse, realistic datasets an issue often tied to privacy concerns and the wide variety of document formats. Traditional tools like Faker rely on predefined templates, making them less effective for capturing the complexity of real-world identity documents. In this paper, we introduce a new approach to synthetic data generation that uses LLMs to create contextually rich and realistic data without relying on predefined field. Using the vast knowledge LLMs have about different documents and content, our method creates data that reflects the variety found in real identity documents. This data is then encoded into barcode and overlayed on templates for documents such as Driver's licenses, Insurance cards, Student IDs. Our approach simplifies the process of dataset creation, eliminating the need for extensive domain knowledge or predefined fields. Compared to traditional methods like Faker, data generated by LLM demonstrates greater diversity and contextual relevance, leading to improved performance in barcode detection models. This scalable, privacy-first solution is a big step forward in advancing machine learning for automated document processing and identity verification.
Exploring Ordinality in Text Classification: A Comparative Study of Explicit and Implicit Techniques
May 20, 2024
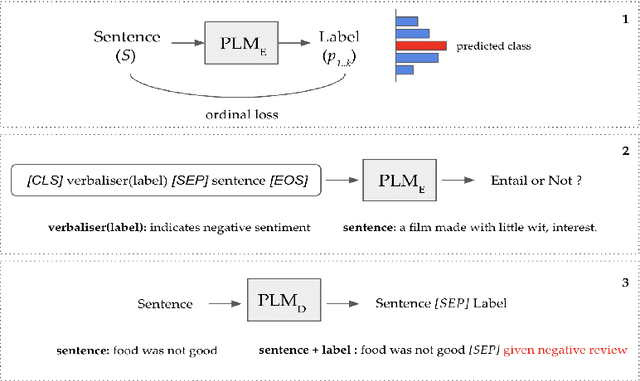

Ordinal Classification (OC) is a widely encountered challenge in Natural Language Processing (NLP), with applications in various domains such as sentiment analysis, rating prediction, and more. Previous approaches to tackle OC have primarily focused on modifying existing or creating novel loss functions that \textbf{explicitly} account for the ordinal nature of labels. However, with the advent of Pretrained Language Models (PLMs), it became possible to tackle ordinality through the \textbf{implicit} semantics of the labels as well. This paper provides a comprehensive theoretical and empirical examination of both these approaches. Furthermore, we also offer strategic recommendations regarding the most effective approach to adopt based on specific settings.
How Robust are LLMs to In-Context Majority Label Bias?
Dec 27, 2023In the In-Context Learning (ICL) setup, various forms of label biases can manifest. One such manifestation is majority label bias, which arises when the distribution of labeled examples in the in-context samples is skewed towards one or more specific classes making Large Language Models (LLMs) more prone to predict those labels. Such discrepancies can arise from various factors, including logistical constraints, inherent biases in data collection methods, limited access to diverse data sources, etc. which are unavoidable in a real-world industry setup. In this work, we study the robustness of in-context learning in LLMs to shifts that occur due to majority label bias within the purview of text classification tasks. Prior works have shown that in-context learning with LLMs is susceptible to such biases. In our study, we go one level deeper and show that the robustness boundary varies widely for different models and tasks, with certain LLMs being highly robust (~90%) to majority label bias. Additionally, our findings also highlight the impact of model size and the richness of instructional prompts contributing towards model robustness. We restrict our study to only publicly available open-source models to ensure transparency and reproducibility.
Tackling Concept Shift in Text Classification using Entailment-style Modeling
Nov 06, 2023Pre-trained language models (PLMs) have seen tremendous success in text classification (TC) problems in the context of Natural Language Processing (NLP). In many real-world text classification tasks, the class definitions being learned do not remain constant but rather change with time - this is known as Concept Shift. Most techniques for handling concept shift rely on retraining the old classifiers with the newly labelled data. However, given the amount of training data required to fine-tune large DL models for the new concepts, the associated labelling costs can be prohibitively expensive and time consuming. In this work, we propose a reformulation, converting vanilla classification into an entailment-style problem that requires significantly less data to re-train the text classifier to adapt to new concepts. We demonstrate the effectiveness of our proposed method on both real world & synthetic datasets achieving absolute F1 gains upto 7% and 40% respectively in few-shot settings. Further, upon deployment, our solution also helped save 75% of labeling costs overall.
ADARES: Adaptive Resource Management for Virtual Machines
Dec 06, 2018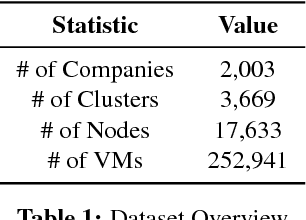
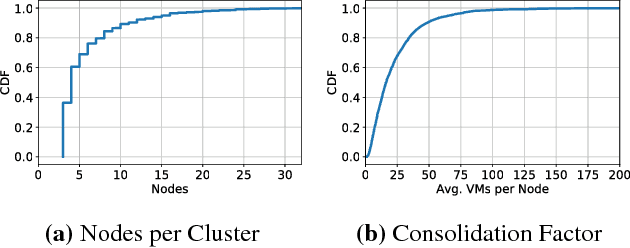
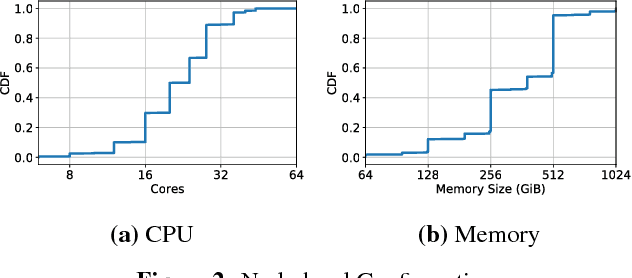
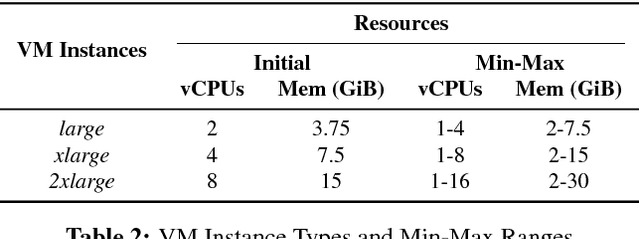
Virtual execution environments allow for consolidation of multiple applications onto the same physical server, thereby enabling more efficient use of server resources. However, users often statically configure the resources of virtual machines through guesswork, resulting in either insufficient resource allocations that hinder VM performance, or excessive allocations that waste precious data center resources. In this paper, we first characterize real-world resource allocation and utilization of VMs through the analysis of an extensive dataset, consisting of more than 250k VMs from over 3.6k private enterprise clusters. Our large-scale analysis confirms that VMs are often misconfigured, either overprovisioned or underprovisioned, and that this problem is pervasive across a wide range of private clusters. We then propose ADARES, an adaptive system that dynamically adjusts VM resources using machine learning techniques. In particular, ADARES leverages the contextual bandits framework to effectively manage the adaptations. Our system exploits easily collectible data, at the cluster, node, and VM levels, to make more sensible allocation decisions, and uses transfer learning to safely explore the configurations space and speed up training. Our empirical evaluation shows that ADARES can significantly improve system utilization without sacrificing performance. For instance, when compared to threshold and prediction-based baselines, it achieves more predictable VM-level performance and also reduces the amount of virtual CPUs and memory provisioned by up to 35% and 60% respectively for synthetic workloads on real clusters.