 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Ordinality in Text Classification: A Comparative Study of Explicit and Implicit Techniques
May 20, 2024
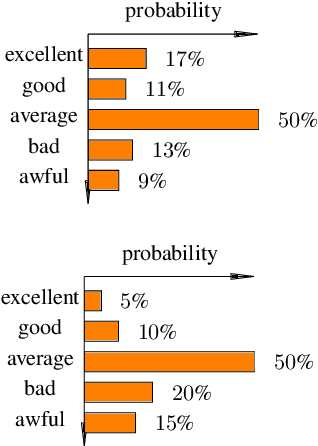
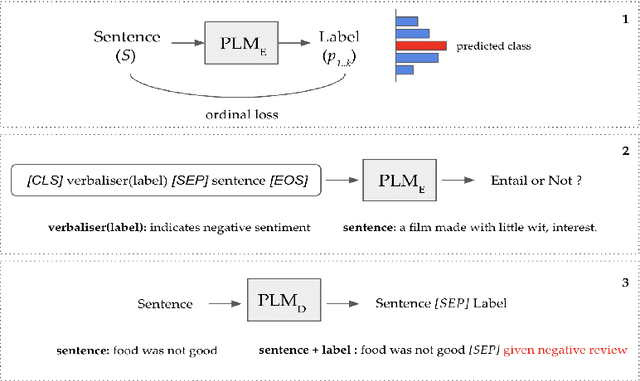

Ordinal Classification (OC) is a widely encountered challenge in Natural Language Processing (NLP), with applications in various domains such as sentiment analysis, rating prediction, and more. Previous approaches to tackle OC have primarily focused on modifying existing or creating novel loss functions that \textbf{explicitly} account for the ordinal nature of labels. However, with the advent of Pretrained Language Models (PLMs), it became possible to tackle ordinality through the \textbf{implicit} semantics of the labels as well. This paper provides a comprehensive theoretical and empirical examination of both these approaches. Furthermore, we also offer strategic recommendations regarding the most effective approach to adopt based on specific settings.
How Robust are LLMs to In-Context Majority Label Bias?
Dec 27, 2023In the In-Context Learning (ICL) setup, various forms of label biases can manifest. One such manifestation is majority label bias, which arises when the distribution of labeled examples in the in-context samples is skewed towards one or more specific classes making Large Language Models (LLMs) more prone to predict those labels. Such discrepancies can arise from various factors, including logistical constraints, inherent biases in data collection methods, limited access to diverse data sources, etc. which are unavoidable in a real-world industry setup. In this work, we study the robustness of in-context learning in LLMs to shifts that occur due to majority label bias within the purview of text classification tasks. Prior works have shown that in-context learning with LLMs is susceptible to such biases. In our study, we go one level deeper and show that the robustness boundary varies widely for different models and tasks, with certain LLMs being highly robust (~90%) to majority label bias. Additionally, our findings also highlight the impact of model size and the richness of instructional prompts contributing towards model robustness. We restrict our study to only publicly available open-source models to ensure transparency and reproducibility.
Tackling Concept Shift in Text Classification using Entailment-style Modeling
Nov 06, 2023Pre-trained language models (PLMs) have seen tremendous success in text classification (TC) problems in the context of Natural Language Processing (NLP). In many real-world text classification tasks, the class definitions being learned do not remain constant but rather change with time - this is known as Concept Shift. Most techniques for handling concept shift rely on retraining the old classifiers with the newly labelled data. However, given the amount of training data required to fine-tune large DL models for the new concepts, the associated labelling costs can be prohibitively expensive and time consuming. In this work, we propose a reformulation, converting vanilla classification into an entailment-style problem that requires significantly less data to re-train the text classifier to adapt to new concepts. We demonstrate the effectiveness of our proposed method on both real world & synthetic datasets achieving absolute F1 gains upto 7% and 40% respectively in few-shot settings. Further, upon deployment, our solution also helped save 75% of labeling costs overall.