 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Ordinality in Text Classification: A Comparative Study of Explicit and Implicit Techniques
May 20, 2024
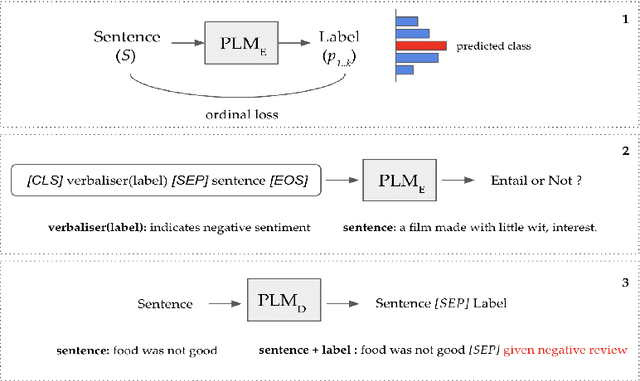

Ordinal Classification (OC) is a widely encountered challenge in Natural Language Processing (NLP), with applications in various domains such as sentiment analysis, rating prediction, and more. Previous approaches to tackle OC have primarily focused on modifying existing or creating novel loss functions that \textbf{explicitly} account for the ordinal nature of labels. However, with the advent of Pretrained Language Models (PLMs), it became possible to tackle ordinality through the \textbf{implicit} semantics of the labels as well. This paper provides a comprehensive theoretical and empirical examination of both these approaches. Furthermore, we also offer strategic recommendations regarding the most effective approach to adopt based on specific settings.