 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Ternary Quantization
Sep 26, 2019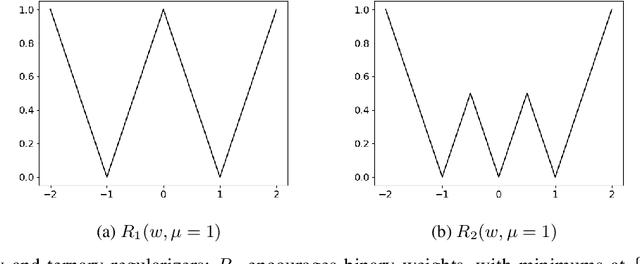
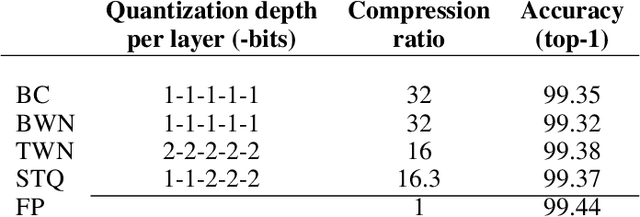
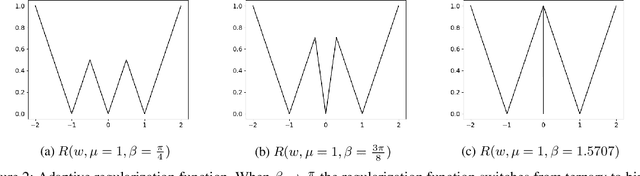

Neural network models are resource hungry. Low bit quantization such as binary and ternary quantization is a common approach to alleviate this resource requirements. Ternary quantization provides a more flexible model and often beats binary quantization in terms of accuracy, but doubles memory and increases computation cost. Mixed quantization depth models, on another hand, allows a trade-off between accuracy and memory footprint. In such models, quantization depth is often chosen manually (which is a tiring task), or is tuned using a separate optimization routine (which requires training a quantized network multiple times). Here, we propose Smart Ternary Quantization (STQ) in which we modify the quantization depth directly through an adaptive regularization function, so that we train a model only once. This method jumps between binary and ternary quantization while training. We show its application on image classification.