 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Top-k ListNet
Nov 01, 2015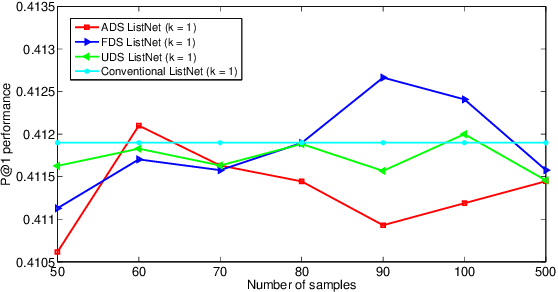
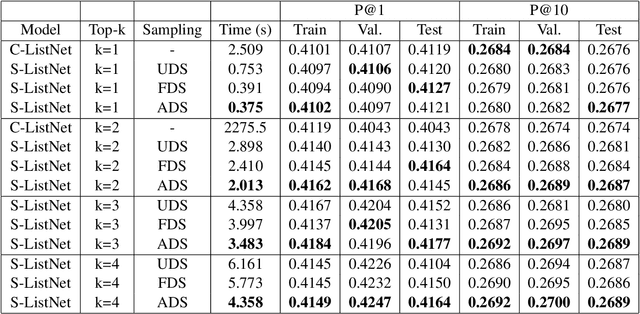
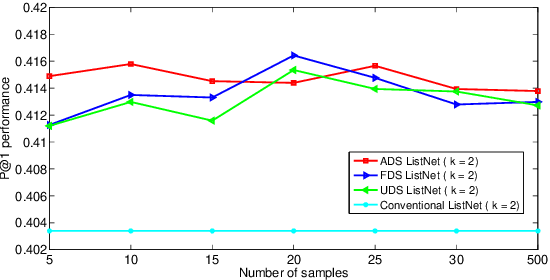
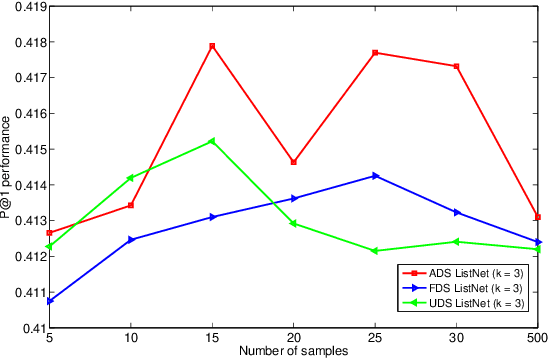
ListNet is a well-known listwise learning to rank model and has gained much attention in recent years. A particular problem of ListNet, however, is the high computation complexity in model training, mainly due to the large number of object permutations involved in computing the gradients. This paper proposes a stochastic ListNet approach which computes the gradient within a bounded permutation subset. It significantly reduces the computation complexity of model training and allows extension to Top-k models, which is impossible with the conventional implementation based on full-set permutations. Meanwhile, the new approach utilizes partial ranking information of human labels, which helps improve model quality. Our experiments demonstrated that the stochastic ListNet method indeed leads to better ranking performance and speeds up the model training remarkably.
Knowledge Transfer Pre-training
Jun 07, 2015


Pre-training is crucial for learning deep neural networks. Most of existing pre-training methods train simple models (e.g., restricted Boltzmann machines) and then stack them layer by layer to form the deep structure. This layer-wise pre-training has found strong theoretical foundation and broad empirical support. However, it is not easy to employ such method to pre-train models without a clear multi-layer structure,e.g., recurrent neural networks (RNNs). This paper presents a new pre-training approach based on knowledge transfer learning. In contrast to the layer-wise approach which trains model components incrementally, the new approach trains the entire model as a whole but with an easier objective function. This is achieved by utilizing soft targets produced by a prior trained model (teacher model). Compared to the conventional layer-wise methods, this new method does not care about the model structure, so can be used to pre-train very complex models. Experiments on a speech recognition task demonstrated that with this approach, complex RNNs can be well trained with a weaker deep neural network (DNN) model. Furthermore, the new method can be combined with conventional layer-wise pre-training to deliver additional gains.