 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Rich Get Richer: Disparate Impact of Semi-Supervised Learning
Paper and Code
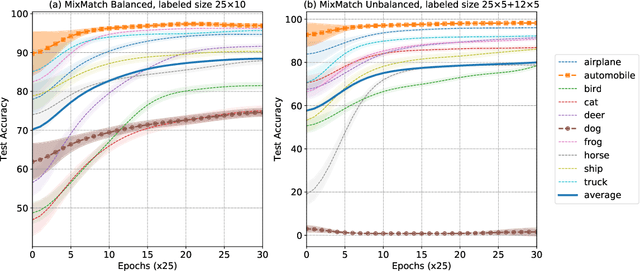

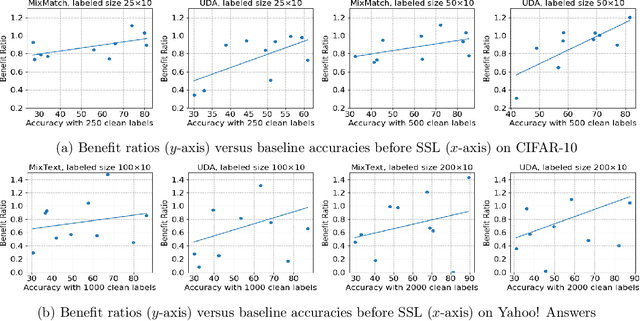

Semi-supervised learning (SSL) has demonstrated its potential to improve the model accuracy for a variety of learning tasks when the high-quality supervised data is severely limited. Although it is often established that the average accuracy for the entire population of data is improved, it is unclear how SSL fares with different sub-populations. Understanding the above question has substantial fairness implications when these different sub-populations are defined by the demographic groups we aim to treat fairly. In this paper, we reveal the disparate impacts of deploying SSL: the sub-population who has a higher baseline accuracy without using SSL (the ``rich" sub-population) tends to benefit more from SSL; while the sub-population who suffers from a low baseline accuracy (the ``poor" sub-population) might even observe a performance drop after adding the SSL module. We theoretically and empirically establish the above observation for a broad family of SSL algorithms, which either explicitly or implicitly use an auxiliary ``pseudo-label". Our experiments on a set of image and text classification tasks confirm our claims. We discuss how this disparate impact can be mitigated and hope that our paper will alarm the potential pitfall of using SSL and encourage a multifaceted evaluation of future SSL algorithms. Code is available at github.com/UCSC-REAL/Disparate-SSL.