 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingGAN: Generative Adversarial Network For High-Fidelity Singing Voice Generation
Paper and Code
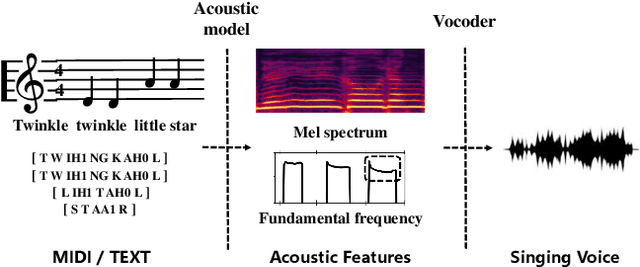

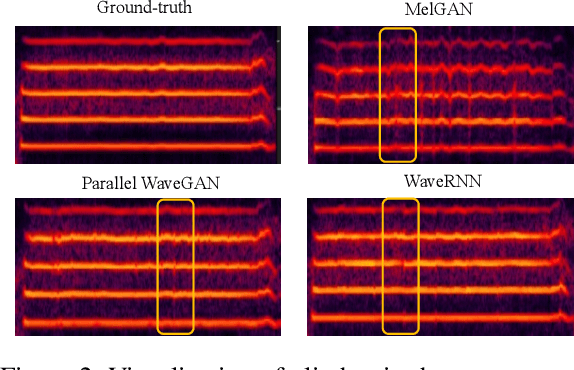

High-fidelity singing voice synthesis is challenging for neural vocoders due to extremely long continuous pronunciation, high sampling rate and strong expressiveness. Existing neural vocoders designed for text-to-speech cannot directly be applied to singing voice synthesis because they result in glitches in the generated spectrogram and poor high-frequency reconstruction. To tackle the difficulty of singing modeling, in this paper, we propose SingGAN, a singing voice vocoder with generative adversarial network. Specifically, 1) SingGAN uses source excitation to alleviate the glitch problem in the spectrogram; and 2) SingGAN adopts multi-band discriminators and introduces frequency-domain loss and sub-band feature matching loss to supervise high-frequency reconstruction. To our knowledge, SingGAN is the first vocoder designed towards high-fidelity multi-speaker singing voice synthesis. Experimental results show that SingGAN synthesizes singing voices with much higher quality (0.41 MOS gains) over the previous method. Further experiments show that combined with FastSpeech~2 as an acoustic model, SingGAN achieves high robustness in the singing voice synthesis pipeline and also performs well in speech synthesis.