 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMOVIE: A Mandarin Emotion Speech Dataset with a Simple Emotional Text-to-Speech Model
Paper and Code
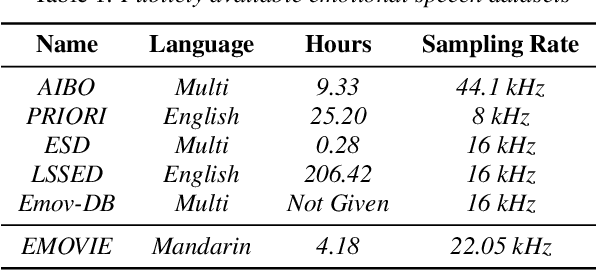
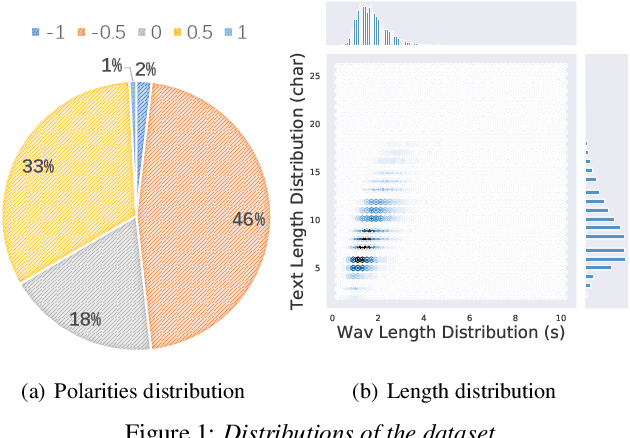

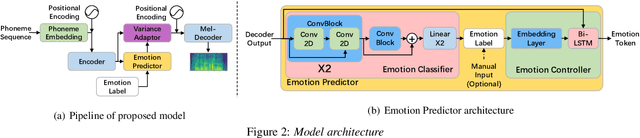
Recently, there has been an increasing interest in neural speech synthesis. While the deep neural network achieves the state-of-the-art result in text-to-speech (TTS) tasks, how to generate a more emotional and more expressive speech is becoming a new challenge to researchers due to the scarcity of high-quality emotion speech dataset and the lack of advanced emotional TTS model. In this paper, we first briefly introduce and publicly release a Mandarin emotion speech dataset including 9,724 samples with audio files and its emotion human-labeled annotation. After that, we propose a simple but efficient architecture for emotional speech synthesis called EMSpeech. Unlike those models which need additional reference audio as input, our model could predict emotion labels just from the input text and generate more expressive speech conditioned on the emotion embedding. In the experiment phase, we first validate the effectiveness of our dataset by an emotion classification task. Then we train our model on the proposed dataset and conduct a series of subjective evaluations. Finally, by showing a comparable performance in the emotional speech synthesis task, we successfully demonstrate the ability of the proposed model.