 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeamTransformer: Microphone Array-based Overlapping Speech Detection
Paper and Code
Sep 09, 2021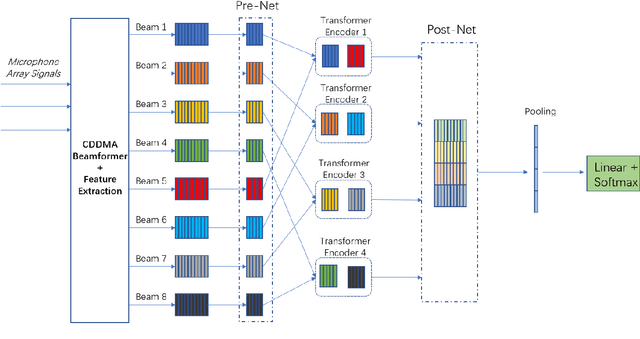

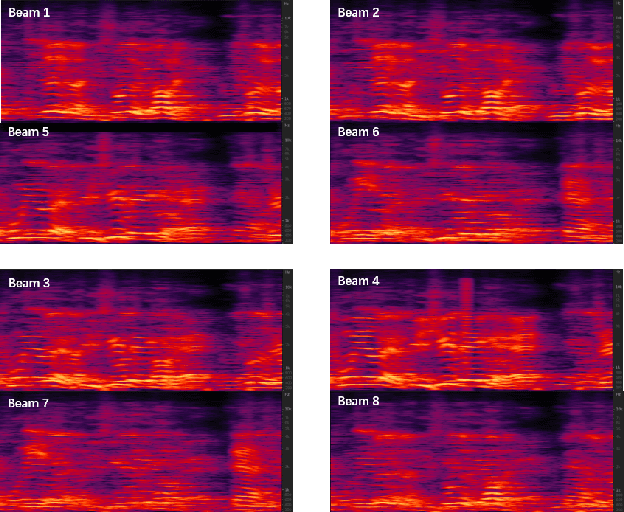
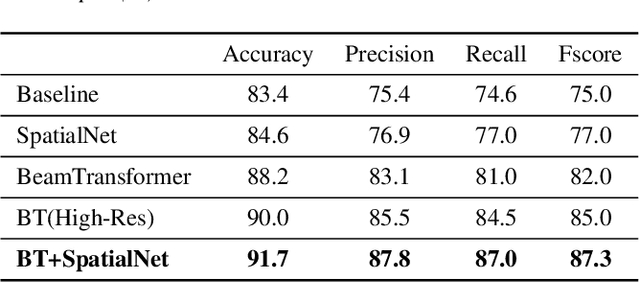
We propose BeamTransformer, an efficient architecture to leverage beamformer's edge in spatial filtering and transformer's capability in context sequence modeling. BeamTransformer seeks to optimize modeling of sequential relationship among signals from different spatial direction. Overlapping speech detection is one of the tasks where such optimization is favorable. In this paper we effectively apply BeamTransformer to detect overlapping segments. Comparing to single-channel approach, BeamTransformer exceeds in learning to identify the relationship among different beam sequences and hence able to make predictions not only from the acoustic signals but also the localization of the source. The results indicate that a successful incorporation of microphone array signals can lead to remarkable gains. Moreover, BeamTransformer takes one step further, as speech from overlapped speakers have been internally separated into different beams.