 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNDF+: Joint Neural Directional Filtering and Diffuse Sound Extraction
May 07, 2026Recently, neural directional filtering (NDF) has been introduced as a flexible approach for reconstructing a virtual directional microphone (VDM) with a desired directivity pattern for spatial sound capture. Building on this idea, we propose NDF+, which enables joint neural directional filtering and diffuse sound extraction. NDF+ reformulates VDM estimation into two coupled subtasks: dereverberated VDM reconstruction and diffuse sound extraction. This reformulation enables NDF+ to manipulate diffuse components in the final reconstructed VDM output. We evaluated NDF+ under reverberant conditions and compared it with representative conventional baselines. Results show that NDF+ consistently outperforms the baselines on both subtasks, while maintaining VDM reconstruction quality comparable to that of the original single-task NDF model. These findings indicate that NDF+ introduces an additional degree of freedom for diffuse sound control in the VDM reconstruction. In a stereo recording application, NDF+ provides controllable inter-channel level differences between left and right channels by adjusting the estimated diffuse component.
Neural Directional Filtering Using a Compact Microphone Array
Nov 18, 2025Beamforming with desired directivity patterns using compact microphone arrays is essential in many audio applications. Directivity patterns achievable using traditional beamformers depend on the number of microphones and the array aperture. Generally, their effectiveness degrades for compact arrays. To overcome these limitations, we propose a neural directional filtering (NDF) approach that leverages deep neural networks to enable sound capture with a predefined directivity pattern. The NDF computes a single-channel complex mask from the microphone array signals, which is then applied to a reference microphone to produce an output that approximates a virtual directional microphone with the desired directivity pattern. We introduce training strategies and propose data-dependent metrics to evaluate the directivity pattern and directivity factor. We show that the proposed method: i) achieves a frequency-invariant directivity pattern even above the spatial aliasing frequency, ii) can approximate diverse and higher-order patterns, iii) can steer the pattern in different directions, and iv) generalizes to unseen conditions. Lastly, experimental comparisons demonstrate superior performance over conventional beamforming and parametric approaches.
Summary On The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Grand Challenge
Feb 08, 2022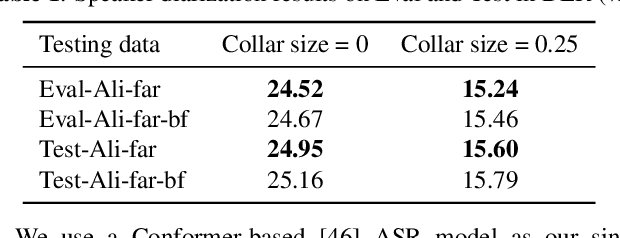
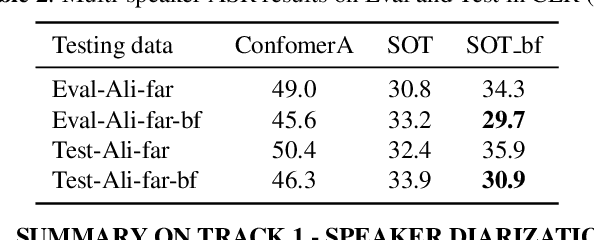
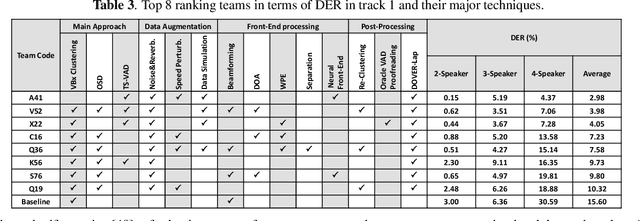
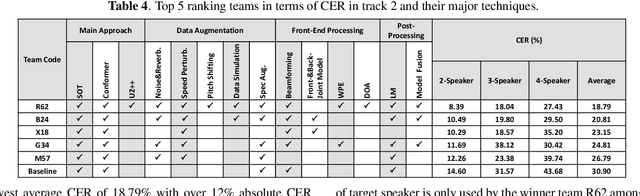
The ICASSP 2022 Multi-channel Multi-party Meeting Transcription Grand Challenge (M2MeT) focuses on one of the most valuable and the most challenging scenarios of speech technologies. The M2MeT challenge has particularly set up two tracks, speaker diarization (track 1) and multi-speaker automatic speech recognition (ASR) (track 2). Along with the challenge, we released 120 hours of real-recorded Mandarin meeting speech data with manual annotation, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. We briefly describe the released dataset, track setups, baselines and summarize the challenge results and major techniques used in the submissions.
Speaker Embedding-aware Neural Diarization for Flexible Number of Speakers with Textual Information
Nov 28, 2021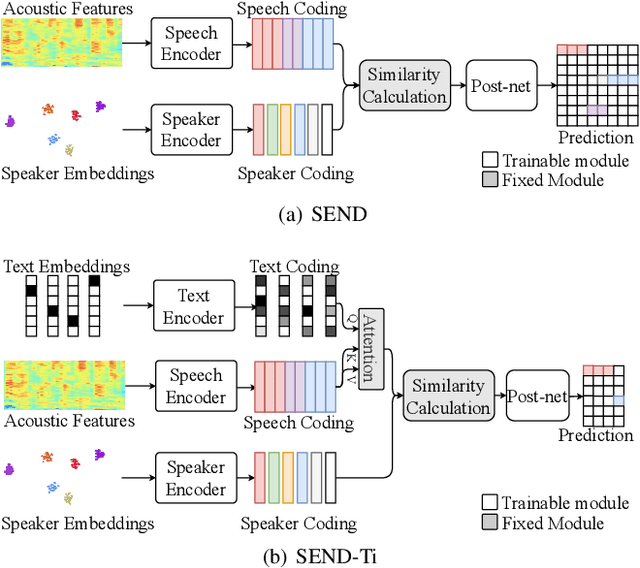

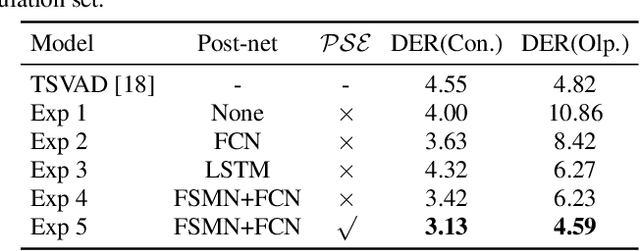

Overlapping speech diarization is always treated as a multi-label classification problem. In this paper, we reformulate this task as a single-label prediction problem by encoding the multi-speaker labels with power set. Specifically, we propose the speaker embedding-aware neural diarization (SEND) method, which predicts the power set encoded labels according to the similarities between speech features and given speaker embeddings. Our method is further extended and integrated with downstream tasks by utilizing the textual information, which has not been well studied in previous literature. The experimental results show that our method achieves lower diarization error rate than the target-speaker voice activity detection. When textual information is involved, the diarization errors can be further reduced. For the real meeting scenario, our method can achieve 34.11% relative improvement compared with the Bayesian hidden Markov model based clustering algorithm.
M2MeT: The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Challenge
Oct 14, 2021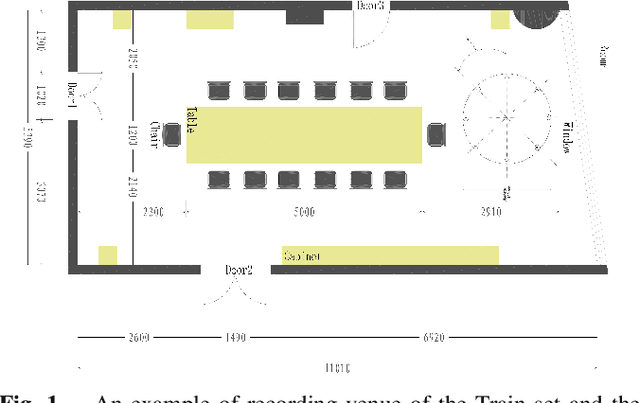
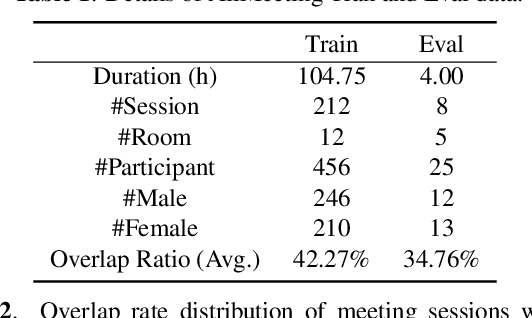
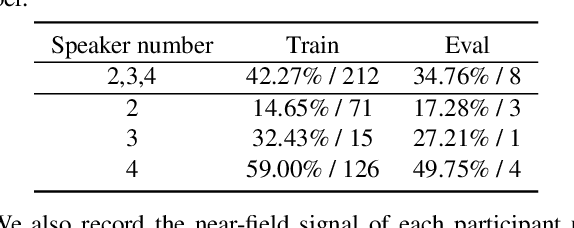
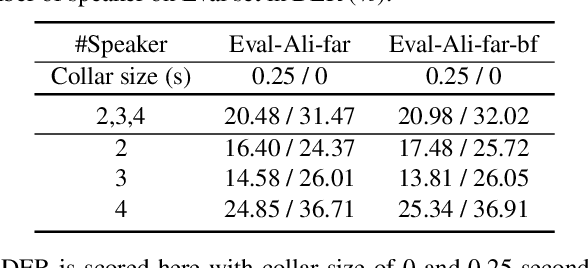
Recent development of speech signal processing, such as speech recognition, speaker diarization, etc., has inspired numerous applications of speech technologies. The meeting scenario is one of the most valuable and, at the same time, most challenging scenarios for speech technologies. Speaker diarization and multi-speaker automatic speech recognition in meeting scenarios have attracted increasing attention. However, the lack of large public real meeting data has been a major obstacle for advancement of the field. Therefore, we release the \emph{AliMeeting} corpus, which consists of 120 hours of real recorded Mandarin meeting data, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. Moreover, we will launch the Multi-channel Multi-party Meeting Transcription Challenge (M2MeT), as an ICASSP2022 Signal Processing Grand Challenge. The challenge consists of two tracks, namely speaker diarization and multi-speaker ASR. In this paper we provide a detailed introduction of the dateset, rules, evaluation methods and baseline systems, aiming to further promote reproducible research in this field.
BeamTransformer: Microphone Array-based Overlapping Speech Detection
Sep 09, 2021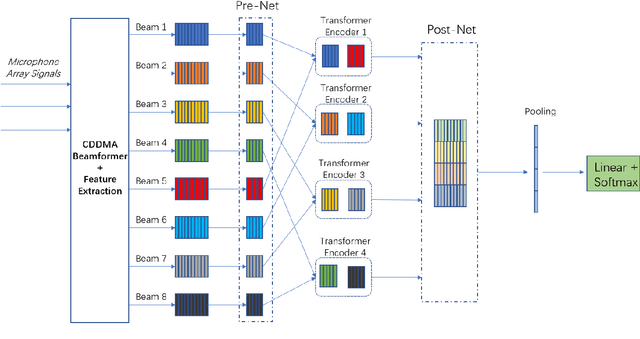

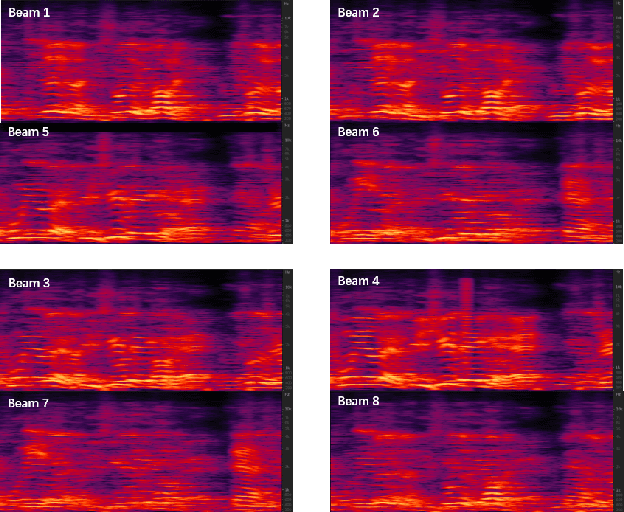
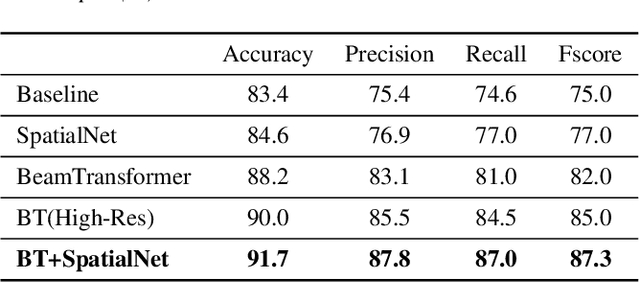
We propose BeamTransformer, an efficient architecture to leverage beamformer's edge in spatial filtering and transformer's capability in context sequence modeling. BeamTransformer seeks to optimize modeling of sequential relationship among signals from different spatial direction. Overlapping speech detection is one of the tasks where such optimization is favorable. In this paper we effectively apply BeamTransformer to detect overlapping segments. Comparing to single-channel approach, BeamTransformer exceeds in learning to identify the relationship among different beam sequences and hence able to make predictions not only from the acoustic signals but also the localization of the source. The results indicate that a successful incorporation of microphone array signals can lead to remarkable gains. Moreover, BeamTransformer takes one step further, as speech from overlapped speakers have been internally separated into different beams.
A Real-time Speaker Diarization System Based on Spatial Spectrum
Jul 20, 2021

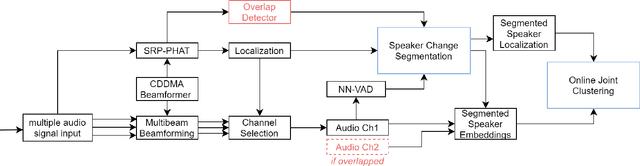

In this paper we describe a speaker diarization system that enables localization and identification of all speakers present in a conversation or meeting. We propose a novel systematic approach to tackle several long-standing challenges in speaker diarization tasks: (1) to segment and separate overlapping speech from two speakers; (2) to estimate the number of speakers when participants may enter or leave the conversation at any time; (3) to provide accurate speaker identification on short text-independent utterances; (4) to track down speakers movement during the conversation; (5) to detect speaker change incidence real-time. First, a differential directional microphone array-based approach is exploited to capture the target speakers' voice in far-field adverse environment. Second, an online speaker-location joint clustering approach is proposed to keep track of speaker location. Third, an instant speaker number detector is developed to trigger the mechanism that separates overlapped speech. The results suggest that our system effectively incorporates spatial information and achieves significant gains.