 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2MeT: The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Challenge
Paper and Code
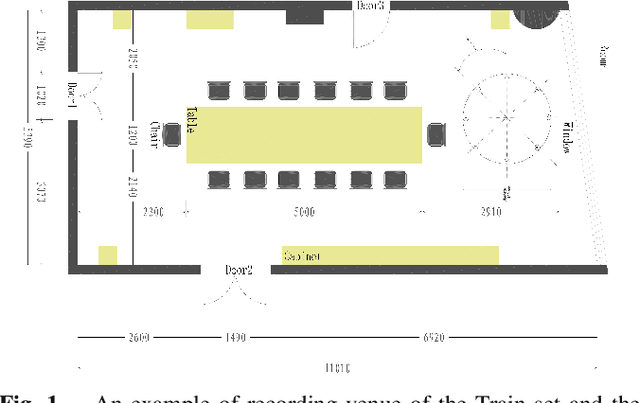
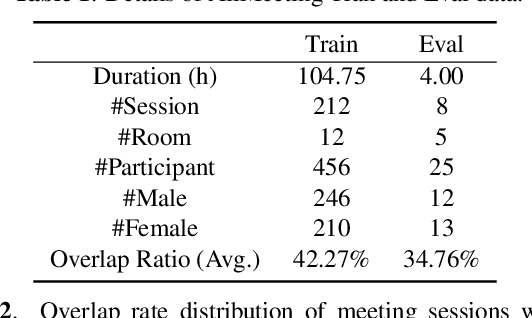
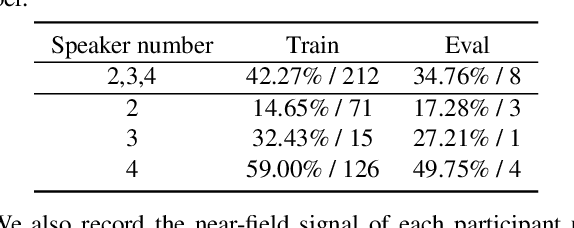
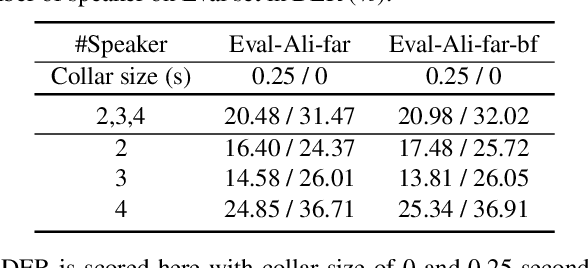
Recent development of speech signal processing, such as speech recognition, speaker diarization, etc., has inspired numerous applications of speech technologies. The meeting scenario is one of the most valuable and, at the same time, most challenging scenarios for speech technologies. Speaker diarization and multi-speaker automatic speech recognition in meeting scenarios have attracted increasing attention. However, the lack of large public real meeting data has been a major obstacle for advancement of the field. Therefore, we release the \emph{AliMeeting} corpus, which consists of 120 hours of real recorded Mandarin meeting data, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. Moreover, we will launch the Multi-channel Multi-party Meeting Transcription Challenge (M2MeT), as an ICASSP2022 Signal Processing Grand Challenge. The challenge consists of two tracks, namely speaker diarization and multi-speaker ASR. In this paper we provide a detailed introduction of the dateset, rules, evaluation methods and baseline systems, aiming to further promote reproducible research in this field.