 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBag of Tricks with Quantized Convolutional Neural Networks for image classification
Mar 13, 2023



Deep neural networks have been proven effective in a wide range of tasks. However, their high computational and memory costs make them impractical to deploy on resource-constrained devices. To address this issue, quantization schemes have been proposed to reduce the memory footprint and improve inference speed. While numerous quantization methods have been proposed, they lack systematic analysis for their effectiveness. To bridge this gap, we collect and improve existing quantization methods and propose a gold guideline for post-training quantization. We evaluate the effectiveness of our proposed method with two popular models, ResNet50 and MobileNetV2, on the ImageNet dataset. By following our guidelines, no accuracy degradation occurs even after directly quantizing the model to 8-bits without additional training. A quantization-aware training based on the guidelines can further improve the accuracy in lower-bits quantization. Moreover, we have integrated a multi-stage fine-tuning strategy that works harmoniously with existing pruning techniques to reduce costs even further. Remarkably, our results reveal that a quantized MobileNetV2 with 30\% sparsity actually surpasses the performance of the equivalent full-precision model, underscoring the effectiveness and resilience of our proposed scheme.
Elastic-Link for Binarized Neural Network
Dec 19, 2021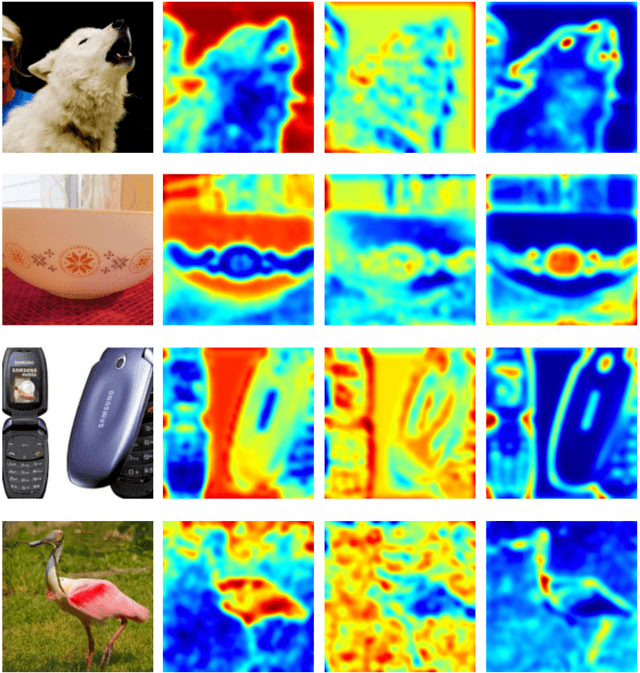
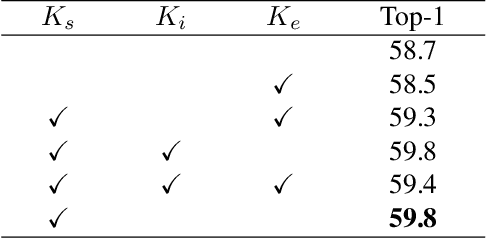
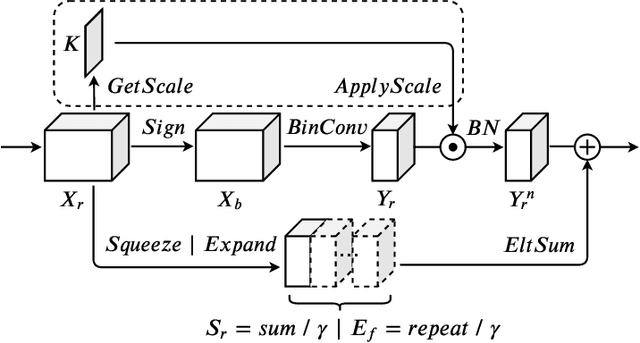
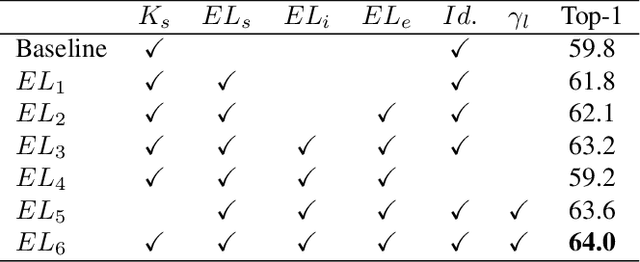
Recent work has shown that Binarized Neural Networks (BNNs) are able to greatly reduce computational costs and memory footprints, facilitating model deployment on resource-constrained devices. However, in comparison to their full-precision counterparts, BNNs suffer from severe accuracy degradation. Research aiming to reduce this accuracy gap has thus far largely focused on specific network architectures with few or no 1x1 convolutional layers, for which standard binarization methods do not work well. Because 1x1 convolutions are common in the design of modern architectures (e.g. GoogleNet, ResNet, DenseNet), it is crucial to develop a method to binarize them effectively for BNNs to be more widely adopted. In this work, we propose an "Elastic-Link" (EL) module to enrich information flow within a BNN by adaptively adding real-valued input features to the subsequent convolutional output features. The proposed EL module is easily implemented and can be used in conjunction with other methods for BNNs. We demonstrate that adding EL to BNNs produces a significant improvement on the challenging large-scale ImageNet dataset. For example, we raise the top-1 accuracy of binarized ResNet26 from 57.9% to 64.0%. EL also aids convergence in the training of binarized MobileNet, for which a top-1 accuracy of 56.4% is achieved. Finally, with the integration of ReActNet, it yields a new state-of-the-art result of 71.9% top-1 accuracy.