 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Normalization Methods in Federated Learning
Paper and Code
Oct 07, 2022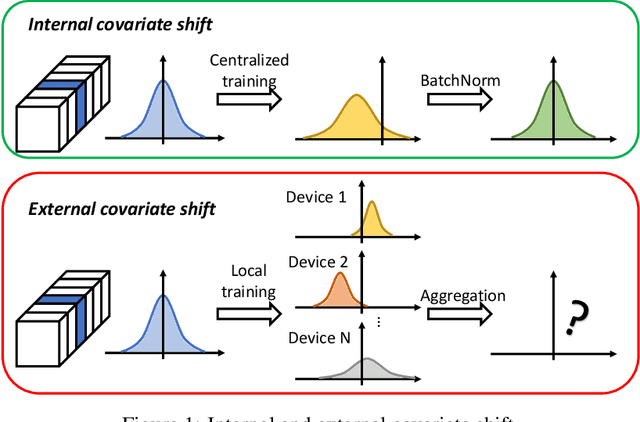

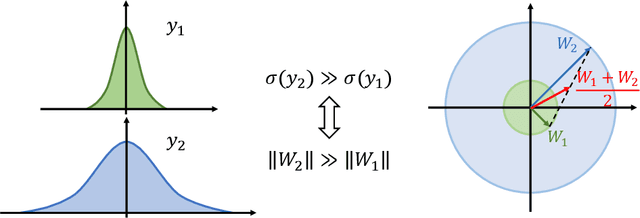
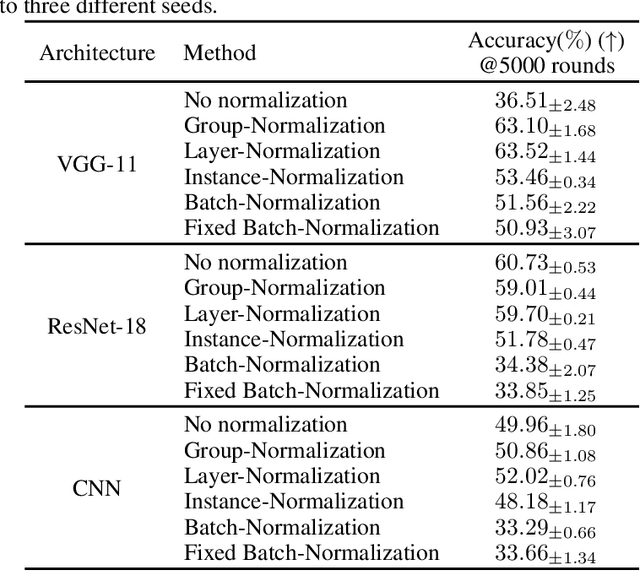
Federated learning (FL) is a popular distributed learning framework that can reduce privacy risks by not explicitly sharing private data. In this work, we explicitly uncover external covariate shift problem in FL, which is caused by the independent local training processes on different devices. We demonstrate that external covariate shifts will lead to the obliteration of some devices' contributions to the global model. Further, we show that normalization layers are indispensable in FL since their inherited properties can alleviate the problem of obliterating some devices' contributions. However, recent works have shown that batch normalization, which is one of the standard components in many deep neural networks, will incur accuracy drop of the global model in FL. The essential reason for the failure of batch normalization in FL is poorly studied. We unveil that external covariate shift is the key reason why batch normalization is ineffective in FL. We also show that layer normalization is a better choice in FL which can mitigate the external covariate shift and improve the performance of the global model. We conduct experiments on CIFAR10 under non-IID settings. The results demonstrate that models with layer normalization converge fastest and achieve the best or comparable accuracy for three different model architectures.