 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeID-Sim: An Identity-Focused Similarity Metric
Apr 06, 2026Humans have remarkable selective sensitivity to identities -- easily distinguishing between highly similar identities, even across significantly different contexts such as diverse viewpoints or lighting. Vision models have struggled to match this capability, and progress toward identity-focused tasks such as personalized image generation is slowed by a lack of identity-focused evaluation metrics. To help facilitate progress, we propose ID-Sim, a feed-forward metric designed to faithfully reflect human selective sensitivity. To build ID-Sim, we curate a high-quality training set of images spanning diverse real-world domains, augmented with generative synthetic data that provides controlled, fine-grained identity and contextual variations. We evaluate our metric on a new unified evaluation benchmark for assessing consistency with human annotations across identity-focused recognition, retrieval, and generative tasks.
TokenDial: Continuous Attribute Control in Text-to-Video via Spatiotemporal Token Offsets
Mar 29, 2026We present TokenDial, a framework for continuous, slider-style attribute control in pretrained text-to-video generation models. While modern generators produce strong holistic videos, they offer limited control over how much an attribute changes (e.g., effect intensity or motion magnitude) without drifting identity, background, or temporal coherence. TokenDial is built on the observation: additive offsets in the intermediate spatiotemporal visual patch-token space form a semantic control direction, where adjusting the offset magnitude yields coherent, predictable edits for both appearance and motion dynamics. We learn attribute-specific token offsets without retraining the backbone, using pretrained understanding signals: semantic direction matching for appearance and motion-magnitude scaling for motion. We demonstrate TokenDial's effectiveness on diverse attributes and prompts, achieving stronger controllability and higher-quality edits than state-of-the-art baselines, supported by extensive quantitative evaluation and human studies.
TRACE: Object Motion Editing in Videos with First-Frame Trajectory Guidance
Mar 26, 2026We study object motion path editing in videos, where the goal is to alter a target object's trajectory while preserving the original scene content. Unlike prior video editing methods that primarily manipulate appearance or rely on point-track-based trajectory control, which is often challenging for users to provide during inference, especially in videos with camera motion, we offer a practical, easy-to-use approach to controllable object-centric motion editing. We present Trace, a framework that enables users to design the desired trajectory in a single anchor frame and then synthesizes a temporally consistent edited video. Our approach addresses this task with a two-stage pipeline: a cross-view motion transformation module that maps first-frame path design to frame-aligned box trajectories under camera motion, and a motion-conditioned video re-synthesis module that follows these trajectories to regenerate the object while preserving the remaining content of the input video. Experiments on diverse real-world videos show that our method produces more coherent, realistic, and controllable motion edits than recent image-to-video and video-to-video methods.
DreamLoop: Controllable Cinemagraph Generation from a Single Photograph
Jan 06, 2026Cinemagraphs, which combine static photographs with selective, looping motion, offer unique artistic appeal. Generating them from a single photograph in a controllable manner is particularly challenging. Existing image-animation techniques are restricted to simple, low-frequency motions and operate only in narrow domains with repetitive textures like water and smoke. In contrast, large-scale video diffusion models are not tailored for cinemagraph constraints and lack the specialized data required to generate seamless, controlled loops. We present DreamLoop, a controllable video synthesis framework dedicated to generating cinemagraphs from a single photo without requiring any cinemagraph training data. Our key idea is to adapt a general video diffusion model by training it on two objectives: temporal bridging and motion conditioning. This strategy enables flexible cinemagraph generation. During inference, by using the input image as both the first- and last- frame condition, we enforce a seamless loop. By conditioning on static tracks, we maintain a static background. Finally, by providing a user-specified motion path for a target object, our method provides intuitive control over the animation's trajectory and timing. To our knowledge, DreamLoop is the first method to enable cinemagraph generation for general scenes with flexible and intuitive controls. We demonstrate that our method produces high-quality, complex cinemagraphs that align with user intent, outperforming existing approaches.
CineVerse: Consistent Keyframe Synthesis for Cinematic Scene Composition
Apr 28, 2025We present CineVerse, a novel framework for the task of cinematic scene composition. Similar to traditional multi-shot generation, our task emphasizes the need for consistency and continuity across frames. However, our task also focuses on addressing challenges inherent to filmmaking, such as multiple characters, complex interactions, and visual cinematic effects. In order to learn to generate such content, we first create the CineVerse dataset. We use this dataset to train our proposed two-stage approach. First, we prompt a large language model (LLM) with task-specific instructions to take in a high-level scene description and generate a detailed plan for the overall setting and characters, as well as the individual shots. Then, we fine-tune a text-to-image generation model to synthesize high-quality visual keyframes. Experimental results demonstrate that CineVerse yields promising improvements in generating visually coherent and contextually rich movie scenes, paving the way for further exploration in cinematic video synthesis.
MotionCanvas: Cinematic Shot Design with Controllable Image-to-Video Generation
Feb 06, 2025



This paper presents a method that allows users to design cinematic video shots in the context of image-to-video generation. Shot design, a critical aspect of filmmaking, involves meticulously planning both camera movements and object motions in a scene. However, enabling intuitive shot design in modern image-to-video generation systems presents two main challenges: first, effectively capturing user intentions on the motion design, where both camera movements and scene-space object motions must be specified jointly; and second, representing motion information that can be effectively utilized by a video diffusion model to synthesize the image animations. To address these challenges, we introduce MotionCanvas, a method that integrates user-driven controls into image-to-video (I2V) generation models, allowing users to control both object and camera motions in a scene-aware manner. By connecting insights from classical computer graphics and contemporary video generation techniques, we demonstrate the ability to achieve 3D-aware motion control in I2V synthesis without requiring costly 3D-related training data. MotionCanvas enables users to intuitively depict scene-space motion intentions, and translates them into spatiotemporal motion-conditioning signals for video diffusion models. We demonstrate the effectiveness of our method on a wide range of real-world image content and shot-design scenarios, highlighting its potential to enhance the creative workflows in digital content creation and adapt to various image and video editing applications.
Personalized Residuals for Concept-Driven Text-to-Image Generation
May 21, 2024
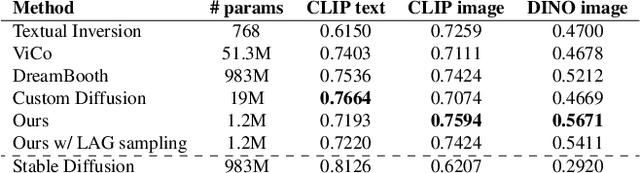
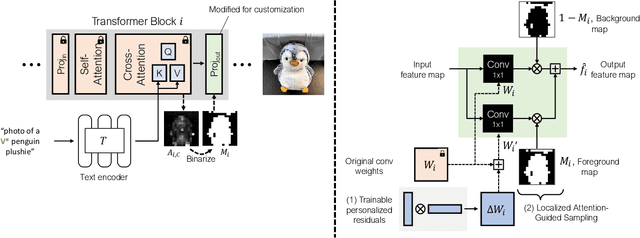
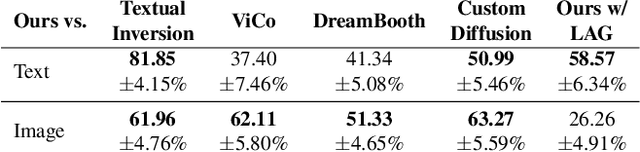
We present personalized residuals and localized attention-guided sampling for efficient concept-driven generation using text-to-image diffusion models. Our method first represents concepts by freezing the weights of a pretrained text-conditioned diffusion model and learning low-rank residuals for a small subset of the model's layers. The residual-based approach then directly enables application of our proposed sampling technique, which applies the learned residuals only in areas where the concept is localized via cross-attention and applies the original diffusion weights in all other regions. Localized sampling therefore combines the learned identity of the concept with the existing generative prior of the underlying diffusion model. We show that personalized residuals effectively capture the identity of a concept in ~3 minutes on a single GPU without the use of regularization images and with fewer parameters than previous models, and localized sampling allows using the original model as strong prior for large parts of the image.
Modulating Pretrained Diffusion Models for Multimodal Image Synthesis
Feb 24, 2023
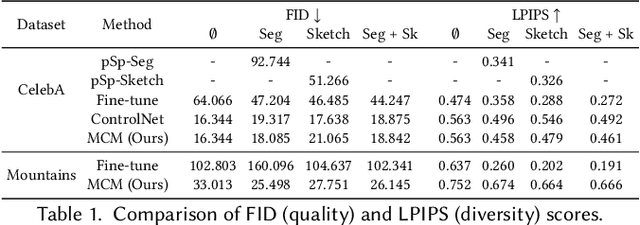


We present multimodal conditioning modules (MCM) for enabling conditional image synthesis using pretrained diffusion models. Previous multimodal synthesis works rely on training networks from scratch or fine-tuning pretrained networks, both of which are computationally expensive for large, state-of-the-art diffusion models. Our method uses pretrained networks but does not require any updates to the diffusion network's parameters. MCM is a small module trained to modulate the diffusion network's predictions during sampling using 2D modalities (e.g., semantic segmentation maps, sketches) that were unseen during the original training of the diffusion model. We show that MCM enables user control over the spatial layout of the image and leads to increased control over the image generation process. Training MCM is cheap as it does not require gradients from the original diffusion net, consists of only $\sim$1$\%$ of the number of parameters of the base diffusion model, and is trained using only a limited number of training examples. We evaluate our method on unconditional and text-conditional models to demonstrate the improved control over the generated images and their alignment with respect to the conditioning inputs.
CoGS: Controllable Generation and Search from Sketch and Style
Mar 17, 2022
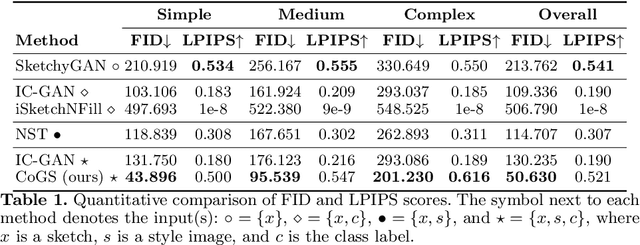
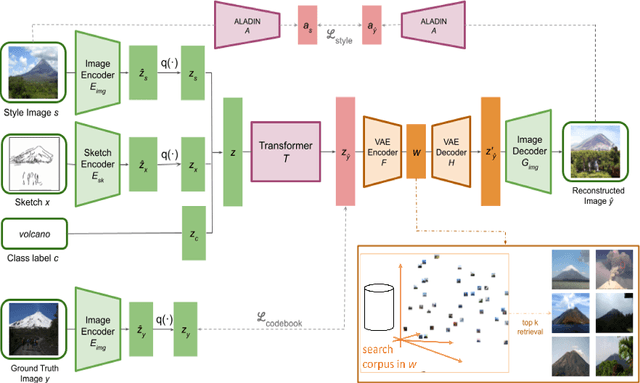
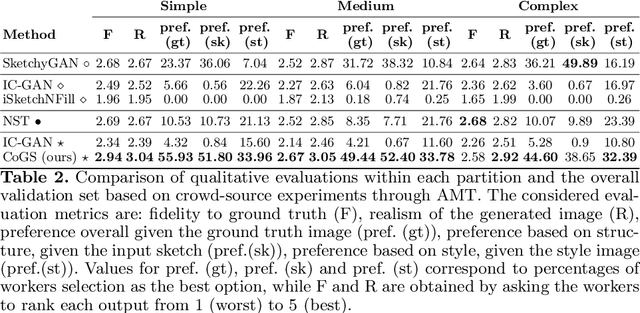
We present CoGS, a novel method for the style-conditioned, sketch-driven synthesis of images. CoGS enables exploration of diverse appearance possibilities for a given sketched object, enabling decoupled control over the structure and the appearance of the output. Coarse-grained control over object structure and appearance are enabled via an input sketch and an exemplar "style" conditioning image to a transformer-based sketch and style encoder to generate a discrete codebook representation. We map the codebook representation into a metric space, enabling fine-grained control over selection and interpolation between multiple synthesis options for a given image before generating the image via a vector quantized GAN (VQGAN) decoder. Our framework thereby unifies search and synthesis tasks, in that a sketch and style pair may be used to run an initial synthesis which may be refined via combination with similar results in a search corpus to produce an image more closely matching the user's intent. We show that our model, trained on the 125 object classes of our newly created Pseudosketches dataset, is capable of producing a diverse gamut of semantic content and appearance styles.
Density of States Estimation for Out-of-Distribution Detection
Jun 22, 2020
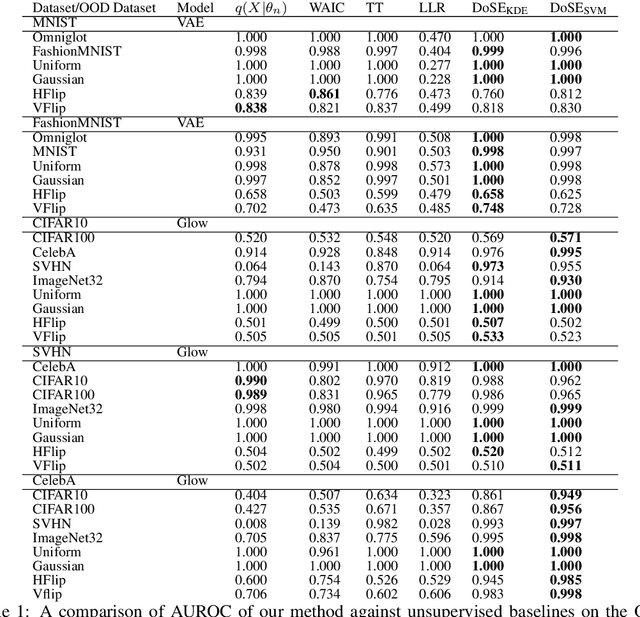
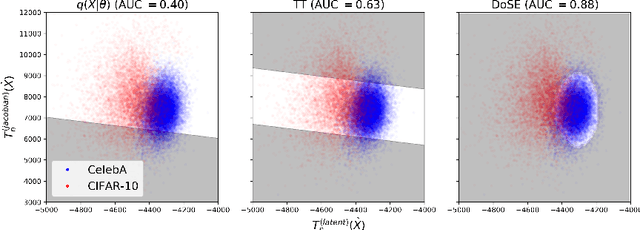
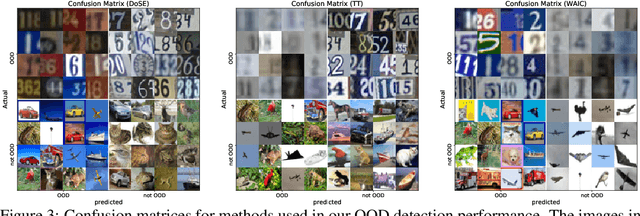
Perhaps surprisingly, recent studies have shown probabilistic model likelihoods have poor specificity for out-of-distribution (OOD) detection and often assign higher likelihoods to OOD data than in-distribution data. To ameliorate this issue we propose DoSE, the density of states estimator. Drawing on the statistical physics notion of ``density of states,'' the DoSE decision rule avoids direct comparison of model probabilities, and instead utilizes the ``probability of the model probability,'' or indeed the frequency of any reasonable statistic. The frequency is calculated using nonparametric density estimators (e.g., KDE and one-class SVM) which measure the typicality of various model statistics given the training data and from which we can flag test points with low typicality as anomalous. Unlike many other methods, DoSE requires neither labeled data nor OOD examples. DoSE is modular and can be trivially applied to any existing, trained model. We demonstrate DoSE's state-of-the-art performance against other unsupervised OOD detectors on previously established ``hard'' benchmarks.