 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniVerse: A Unified Modulation Framework for Segmentation-Free,Disentangled Multi-Concept Personalization
May 29, 2026Personalized visual understanding has advanced significantly, yet existing approaches struggle to localize and extract specific concepts when input images contain multiple objects. Many prior methods rely heavily on segmentation-based supervision or exhibit poor compositional generalization, limiting their ability to accurately disentangle and manipulate individual concepts. In this work, we propose UniVerse, a Unified Modulation Framework for segmentation-free, disentangled multi-concept personalization in diffusion transformers. Our method allows for composable and decomposable concept extraction, enabling fine-grained localization and representation of target objects without explicit segmentation masks. UniVerse learns to decompose complex scenes into concept-specific representations and then compose them in a unified manner, enabling robust personalization across diverse visual contexts. Through extensive experiments on multiple benchmarks, we demonstrate that UniVerse significantly outperforms state-of-the-art baselines in both localization accuracy and visual fidelity. Qualitative and quantitative results show that our approach can precisely extract target concepts in cluttered scenes, paving the way for more flexible, interpretable, and personalized visual generation and understanding.
TRACE: Object Motion Editing in Videos with First-Frame Trajectory Guidance
Mar 26, 2026We study object motion path editing in videos, where the goal is to alter a target object's trajectory while preserving the original scene content. Unlike prior video editing methods that primarily manipulate appearance or rely on point-track-based trajectory control, which is often challenging for users to provide during inference, especially in videos with camera motion, we offer a practical, easy-to-use approach to controllable object-centric motion editing. We present Trace, a framework that enables users to design the desired trajectory in a single anchor frame and then synthesizes a temporally consistent edited video. Our approach addresses this task with a two-stage pipeline: a cross-view motion transformation module that maps first-frame path design to frame-aligned box trajectories under camera motion, and a motion-conditioned video re-synthesis module that follows these trajectories to regenerate the object while preserving the remaining content of the input video. Experiments on diverse real-world videos show that our method produces more coherent, realistic, and controllable motion edits than recent image-to-video and video-to-video methods.
CineVerse: Consistent Keyframe Synthesis for Cinematic Scene Composition
Apr 28, 2025We present CineVerse, a novel framework for the task of cinematic scene composition. Similar to traditional multi-shot generation, our task emphasizes the need for consistency and continuity across frames. However, our task also focuses on addressing challenges inherent to filmmaking, such as multiple characters, complex interactions, and visual cinematic effects. In order to learn to generate such content, we first create the CineVerse dataset. We use this dataset to train our proposed two-stage approach. First, we prompt a large language model (LLM) with task-specific instructions to take in a high-level scene description and generate a detailed plan for the overall setting and characters, as well as the individual shots. Then, we fine-tune a text-to-image generation model to synthesize high-quality visual keyframes. Experimental results demonstrate that CineVerse yields promising improvements in generating visually coherent and contextually rich movie scenes, paving the way for further exploration in cinematic video synthesis.
Coherent Zero-Shot Visual Instruction Generation
Jun 06, 2024

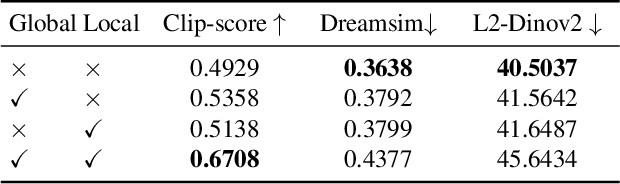

Despite the advances in text-to-image synthesis, particularly with diffusion models, generating visual instructions that require consistent representation and smooth state transitions of objects across sequential steps remains a formidable challenge. This paper introduces a simple, training-free framework to tackle the issues, capitalizing on the advancements in diffusion models and large language models (LLMs). Our approach systematically integrates text comprehension and image generation to ensure visual instructions are visually appealing and maintain consistency and accuracy throughout the instruction sequence. We validate the effectiveness by testing multi-step instructions and comparing the text alignment and consistency with several baselines. Our experiments show that our approach can visualize coherent and visually pleasing instructions
Grounded Text-to-Image Synthesis with Attention Refocusing
Jun 08, 2023Driven by scalable diffusion models trained on large-scale paired text-image datasets, text-to-image synthesis methods have shown compelling results. However, these models still fail to precisely follow the text prompt when multiple objects, attributes, and spatial compositions are involved in the prompt. In this paper, we identify the potential reasons in both the cross-attention and self-attention layers of the diffusion model. We propose two novel losses to refocus the attention maps according to a given layout during the sampling process. We perform comprehensive experiments on the DrawBench and HRS benchmarks using layouts synthesized by Large Language Models, showing that our proposed losses can be integrated easily and effectively into existing text-to-image methods and consistently improve their alignment between the generated images and the text prompts.
Toward Realistic Single-View 3D Object Reconstruction with Unsupervised Learning from Multiple Images
Sep 07, 2021
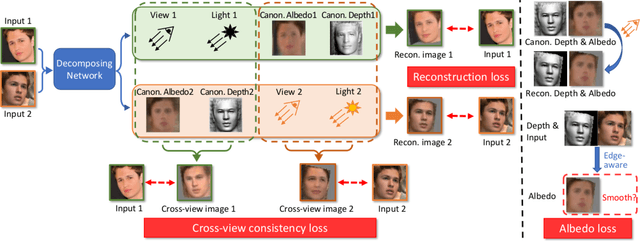
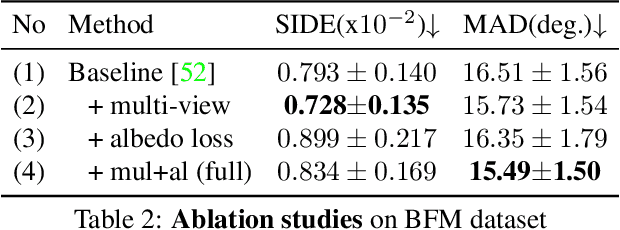

Recovering the 3D structure of an object from a single image is a challenging task due to its ill-posed nature. One approach is to utilize the plentiful photos of the same object category to learn a strong 3D shape prior for the object. This approach has successfully been demonstrated by a recent work of Wu et al. (2020), which obtained impressive 3D reconstruction networks with unsupervised learning. However, their algorithm is only applicable to symmetric objects. In this paper, we eliminate the symmetry requirement with a novel unsupervised algorithm that can learn a 3D reconstruction network from a multi-image dataset. Our algorithm is more general and covers the symmetry-required scenario as a special case. Besides, we employ a novel albedo loss that improves the reconstructed details and realisticity. Our method surpasses the previous work in both quality and robustness, as shown in experiments on datasets of various structures, including single-view, multi-view, image-collection, and video sets.
Explore Image Deblurring via Blur Kernel Space
Apr 03, 2021


This paper introduces a method to encode the blur operators of an arbitrary dataset of sharp-blur image pairs into a blur kernel space. Assuming the encoded kernel space is close enough to in-the-wild blur operators, we propose an alternating optimization algorithm for blind image deblurring. It approximates an unseen blur operator by a kernel in the encoded space and searches for the corresponding sharp image. Unlike recent deep-learning-based methods, our system can handle unseen blur kernel, while avoiding using complicated handcrafted priors on the blur operator often found in classical methods. Due to the method's design, the encoded kernel space is fully differentiable, thus can be easily adopted in deep neural network models. Moreover, our method can be used for blur synthesis by transferring existing blur operators from a given dataset into a new domain. Finally, we provide experimental results to confirm the effectiveness of the proposed method.