 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIndividual differences in the cognitive mechanisms of planning strategy discovery
May 29, 2025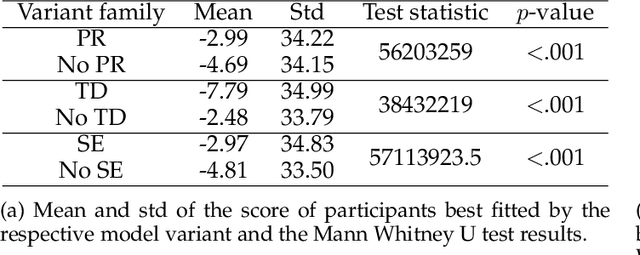
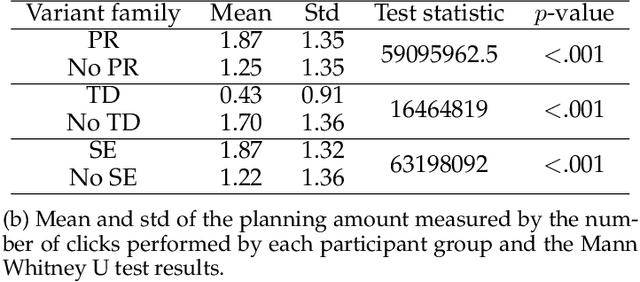
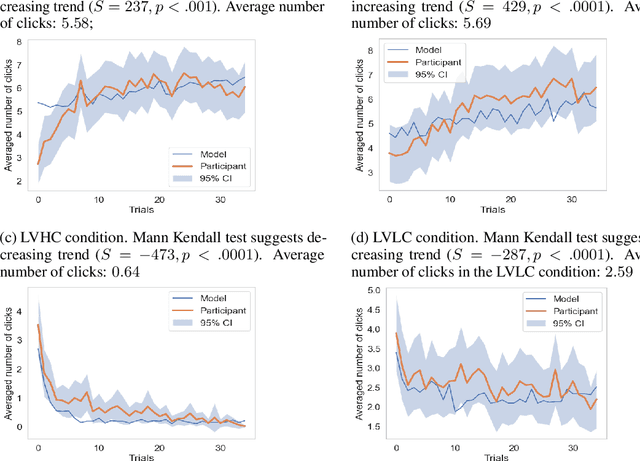
People employ efficient planning strategies. But how are these strategies acquired? Previous research suggests that people can discover new planning strategies through learning from reinforcements, a process known as metacognitive reinforcement learning (MCRL). While prior work has shown that MCRL models can learn new planning strategies and explain more participants' experience-driven discovery better than alternative mechanisms, it also revealed significant individual differences in metacognitive learning. Furthermore, when fitted to human data, these models exhibit a slower rate of strategy discovery than humans. In this study, we investigate whether incorporating cognitive mechanisms that might facilitate human strategy discovery can bring models of MCRL closer to human performance. Specifically, we consider intrinsically generated metacognitive pseudo-rewards, subjective effort valuation, and termination deliberation. Analysis of planning task data shows that a larger proportion of participants used at least one of these mechanisms, with significant individual differences in their usage and varying impacts on strategy discovery. Metacognitive pseudo-rewards, subjective effort valuation, and learning the value of acting without further planning were found to facilitate strategy discovery. While these enhancements provided valuable insights into individual differences and the effect of these mechanisms on strategy discovery, they did not fully close the gap between model and human performance, prompting further exploration of additional factors that people might use to discover new planning strategies.
Chumor 2.0: Towards Benchmarking Chinese Humor Understanding
Dec 23, 2024



Existing humor datasets and evaluations predominantly focus on English, leaving limited resources for culturally nuanced humor in non-English languages like Chinese. To address this gap, we construct Chumor, the first Chinese humor explanation dataset that exceeds the size of existing humor datasets. Chumor is sourced from Ruo Zhi Ba, a Chinese Reddit-like platform known for sharing intellectually challenging and culturally specific jokes. We test ten LLMs through direct and chain-of-thought prompting, revealing that Chumor poses significant challenges to existing LLMs, with their accuracy slightly above random and far below human. In addition, our analysis highlights that human-annotated humor explanations are significantly better than those generated by GPT-4o and ERNIE-4-turbo. We release Chumor at https://huggingface.co/datasets/dnaihao/Chumor, our project page is at https://dnaihao.github.io/Chumor-dataset/, our leaderboard is at https://huggingface.co/spaces/dnaihao/Chumor, and our codebase is at https://github.com/dnaihao/Chumor-dataset.
Experience-driven discovery of planning strategies
Dec 04, 2024
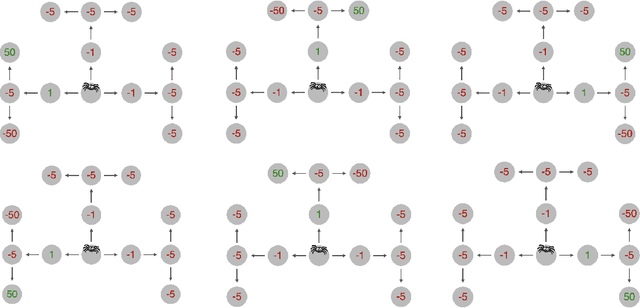
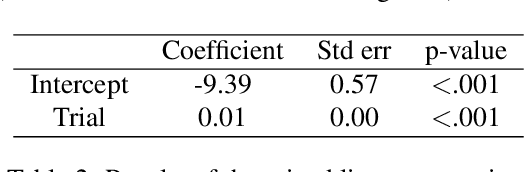
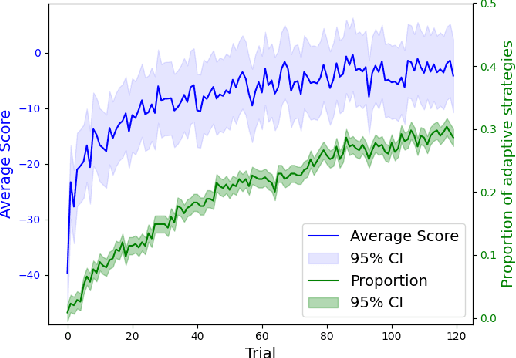
One explanation for how people can plan efficiently despite limited cognitive resources is that we possess a set of adaptive planning strategies and know when and how to use them. But how are these strategies acquired? While previous research has studied how individuals learn to choose among existing strategies, little is known about the process of forming new planning strategies. In this work, we propose that new planning strategies are discovered through metacognitive reinforcement learning. To test this, we designed a novel experiment to investigate the discovery of new planning strategies. We then present metacognitive reinforcement learning models and demonstrate their capability for strategy discovery as well as show that they provide a better explanation of human strategy discovery than alternative learning mechanisms. However, when fitted to human data, these models exhibit a slower discovery rate than humans, leaving room for improvement.
Your Fixed Watermark is Fragile: Towards Semantic-Aware Watermark for EaaS Copyright Protection
Nov 14, 2024



Embedding-as-a-Service (EaaS) has emerged as a successful business pattern but faces significant challenges related to various forms of copyright infringement, including API misuse and different attacks. Various studies have proposed backdoor-based watermarking schemes to protect the copyright of EaaS services. In this paper, we reveal that previous watermarking schemes possess semantic-independent characteristics and propose the Semantic Perturbation Attack (SPA). Our theoretical and experimental analyses demonstrate that this semantic-independent nature makes current watermarking schemes vulnerable to adaptive attacks that exploit semantic perturbations test to bypass watermark verification. To address this vulnerability, we propose the Semantic Aware Watermarking (SAW) scheme, a robust defense mechanism designed to resist SPA, by injecting a watermark that adapts to the text semantics. Extensive experimental results across multiple datasets demonstrate that the True Positive Rate (TPR) for detecting watermarked samples under SPA can reach up to more than 95%, rendering previous watermarks ineffective. Meanwhile, our watermarking scheme can resist such attack while ensuring the watermark verification capability. Our code is available at https://github.com/Zk4-ps/EaaS-Embedding-Watermark.
Chumor 1.0: A Truly Funny and Challenging Chinese Humor Understanding Dataset from Ruo Zhi Ba
Jun 18, 2024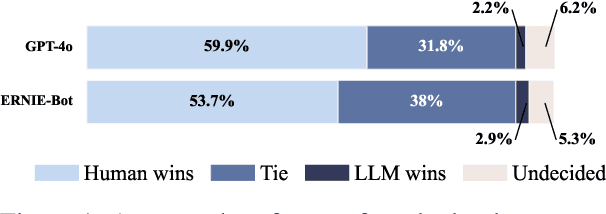

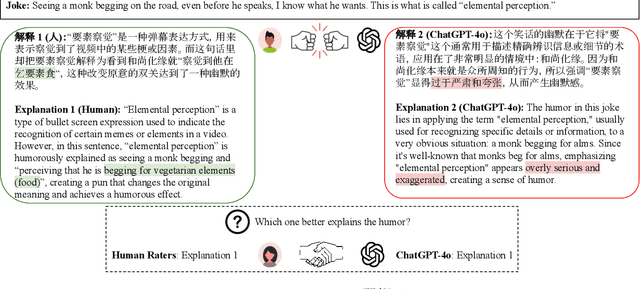
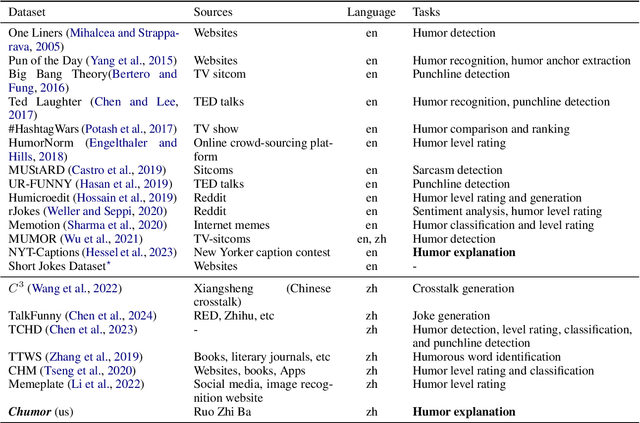
Existing humor datasets and evaluations predominantly focus on English, lacking resources for culturally nuanced humor in non-English languages like Chinese. To address this gap, we construct Chumor, a dataset sourced from Ruo Zhi Ba (RZB), a Chinese Reddit-like platform dedicated to sharing intellectually challenging and culturally specific jokes. We annotate explanations for each joke and evaluate human explanations against two state-of-the-art LLMs, GPT-4o and ERNIE Bot, through A/B testing by native Chinese speakers. Our evaluation shows that Chumor is challenging even for SOTA LLMs, and the human explanations for Chumor jokes are significantly better than explanations generated by the LLMs.
Tables as Images? Exploring the Strengths and Limitations of LLMs on Multimodal Representations of Tabular Data
Feb 23, 2024

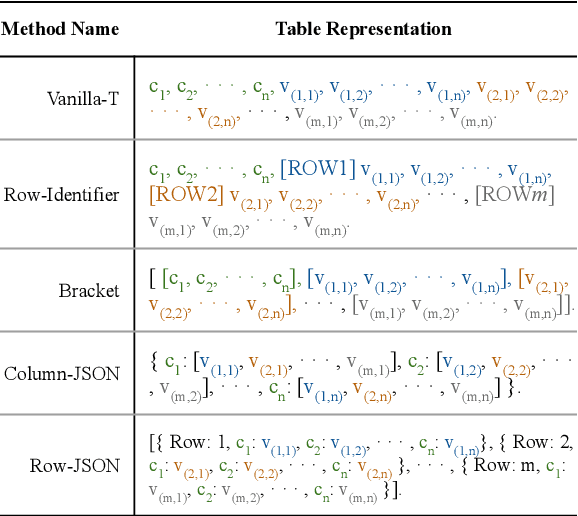

In this paper, we investigate the effectiveness of various LLMs in interpreting tabular data through different prompting strategies and data formats. Our analysis extends across six benchmarks for table-related tasks such as question-answering and fact-checking. We introduce for the first time the assessment of LLMs' performance on image-based table representations. Specifically, we compare five text-based and three image-based table representations, demonstrating the influence of representation and prompting on LLM performance. Our study provides insights into the effective use of LLMs on table-related tasks.
Structurally guided task decomposition in spatial navigation tasks
Oct 03, 2023

How are people able to plan so efficiently despite limited cognitive resources? We aimed to answer this question by extending an existing model of human task decomposition that can explain a wide range of simple planning problems by adding structure information to the task to facilitate planning in more complex tasks. The extended model was then applied to a more complex planning domain of spatial navigation. Our results suggest that our framework can correctly predict the navigation strategies of the majority of the participants in an online experiment.
What are the mechanisms underlying metacognitive learning?
Feb 09, 2023

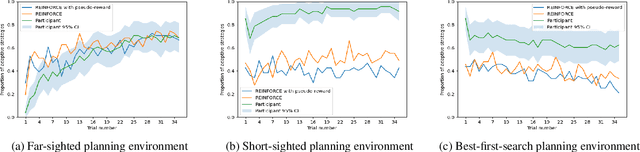
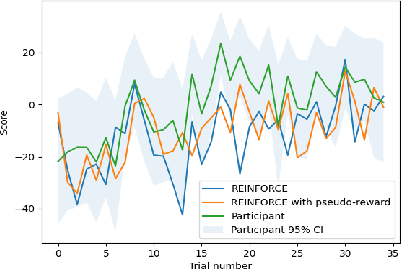
How is it that humans can solve complex planning tasks so efficiently despite limited cognitive resources? One reason is its ability to know how to use its limited computational resources to make clever choices. We postulate that people learn this ability from trial and error (metacognitive reinforcement learning). Here, we systematize models of the underlying learning mechanisms and enhance them with more sophisticated additional mechanisms. We fit the resulting 86 models to human data collected in previous experiments where different phenomena of metacognitive learning were demonstrated and performed Bayesian model selection. Our results suggest that a gradient ascent through the space of cognitive strategies can explain most of the observed qualitative phenomena, and is therefore a promising candidate for explaining the mechanism underlying metacognitive learning.
Have I done enough planning or should I plan more?
Jan 03, 2022


People's decisions about how to allocate their limited computational resources are essential to human intelligence. An important component of this metacognitive ability is deciding whether to continue thinking about what to do and move on to the next decision. Here, we show that people acquire this ability through learning and reverse-engineer the underlying learning mechanisms. Using a process-tracing paradigm that externalises human planning, we find that people quickly adapt how much planning they perform to the cost and benefit of planning. To discover the underlying metacognitive learning mechanisms we augmented a set of reinforcement learning models with metacognitive features and performed Bayesian model selection. Our results suggest that the metacognitive ability to adjust the amount of planning might be learned through a policy-gradient mechanism that is guided by metacognitive pseudo-rewards that communicate the value of planning.